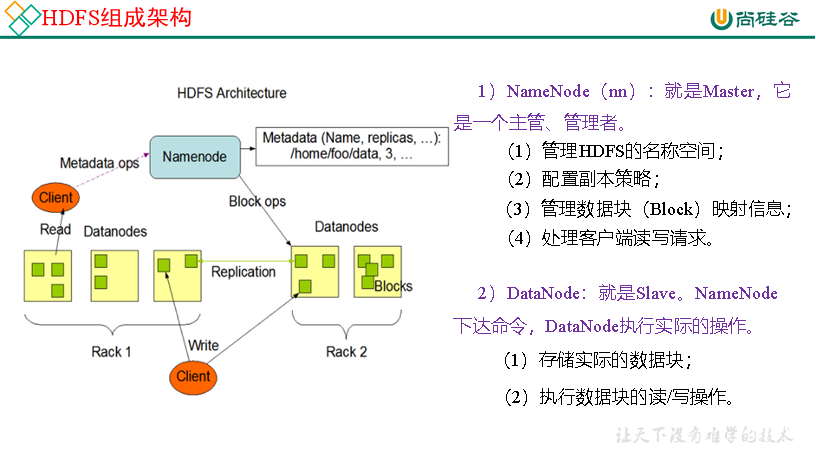
定义 HDFS(Hadoop Distributed File System), 它是一个文件系统, 用于存储文件, 通过目录树来定位文件;
组成架构
1 2 [xiamu@hadoop202 bin]$ hadoop fs -mkdir /aaa
文件块大小 HDFS 中的文件在物理上是分块存储(Block), 块的大小可以通过配置参数(dfs.blocksize)来规定, 默认大小在 Hadoop2.x/3.x 版本中是 128M, 1.x 版本中是 64M
总结: HDFS 块的大小设置主要取决于磁盘传输速率
HDFS 的 Shell 操作(开发重点) hadoop fs 具体命令 OR hdfs dfs 具体命令
常用命令 启动 Hadoop 集群[xiamu@hadoop202 bin]$ myhadoop.sh start[xiamu@hadoop202 bin]$ hadoop fs -help rm[xiamu@hadoop202 bin]$ hadoop fs -mkdir /sanguo
上传
moveFromLocal 的使用:
新建文件, 上传文件(剪切文件)[xiamu@hadoop202 hadoop-3.1.3]$ vim shuguo.txt[xiamu@hadoop202 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo
copyFromLocal 的使用
新建文件, 拷贝文件(本地的文件仍然存在)[xiamu@hadoop202 hadoop-3.1.3]$ vim weiguo.txt[xiamu@hadoop202 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo
put 约同于 copyFromLocal, 生产环境更习惯用 put
[xiamu@hadoop202 hadoop-3.1.3]$ vim wuguo.txt[xiamu@hadoop202 hadoop-3.1.3]$ hadoop fs -put wuguo.txt /sanguo
appendToFile 追加一个文件到已经存在的文件末尾
[xiamu@hadoop202 hadoop-3.1.3]$ vim liubei.txt[xiamu@hadoop202 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
HDFS 的特性, 只能追加内容, 不能修改原有的内容
下载
copyToLocal, 从 HDFS 拷贝到本地
[xiamu@hadoop202 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./
等同于 copyToLocal,生产环境更习惯用 get
[xiamu@hadoop202 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
HDFS 直接操作
-ls: 显示目录信息
[xiamu@hadoop202 hadoop-3.1.3]$ hadoop fs -ls /sanguo
-cat: 显示文件内容
[xiamu@hadoop202 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt
-chgrp、-chmod、-chown:Linux 文件系统中的用法一样,修改文件所属权限
[xiamu@hadoop202 hadoop-3.1.3]$ hadoop fs -chown xiamu:xiamu /sanguo/shuguo.txt
-mkdir:创建路径
[xiamu@hadoop202 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo
-cp:从 HDFS 的一个路径拷贝到 HDFS 的另一个路径
[xiamu@hadoop202 ~]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo
-mv:在 HDFS 目录中移动文件
[xiamu@hadoop202 ~]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo[xiamu@hadoop202 ~]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
-tail:显示一个文件的末尾 1kb 的数据
[xiamu@hadoop202 ~]$ hadoop fs -tail /jinguo/shuguo.txt
-rm:删除文件或文件夹
[xiamu@hadoop202 ~]$ hadoop fs -rm /sanguo/shuguo.txt
-rm -r:递归删除目录及目录里面内容
[xiamu@hadoop202 ~]$ hadoop fs -rm -r /sanguo
-du 统计文件夹的大小信息
1 2 3 4 5 6 7 [xiamu@hadoop202 ~]$ hadoop fs -du -s -h /jinguodu -h /jinguo
说明:27 表示文件大小;81 表示 27*3 个副本;/jinguo 表示查看的目录
-setrep:设置 HDFS 中文件的副本数量
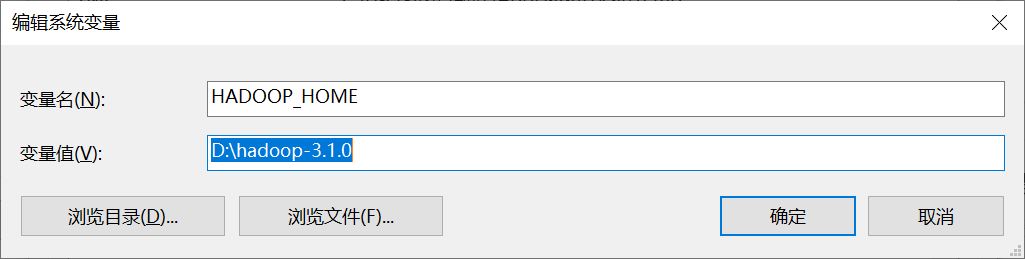
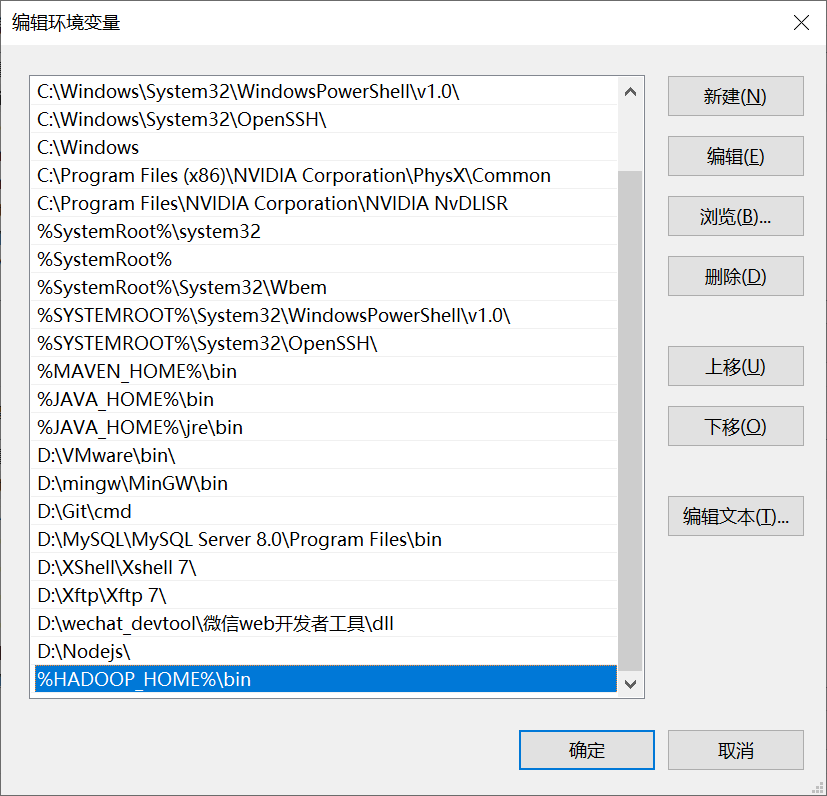
Windows 配置环境变量
创建项目 在 IDEA 中创建一个 Maven 工程 HdfsClientDemo,并导入相应的依赖坐标+日志添加
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <dependencies>
在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
1 2 3 4 5 6 7 8 log4j.rootLogger=INFO, stdout
创建包名:com.atguigu.hdfs 创建 HdfsClient 类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class HdfsClient {"hdfs://hadoop102:8020" ), configuration);"hdfs://hadoop102:8020" ), configuration,"atguigu" );"/xiyou/huaguoshan/" ));
HDFS_API 创建文件夹 为了方便, 每一个测试类中都会存在获取文件系统, 关闭资源这两个操作, 所以我们可以使用切面抽取出来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 private FileSystem fs;"hdfs://hadoop202:8020" );"xiamu" ;
创建目录代码, 相比于之前的代码, 瞬间精简了很多
1 2 3 4 5 6 7 8 9 // 创建目录"/xiyou/huaguoshan1" ));
HDFS_API 上传 1 2 3 4 5 6 7 8 9 10 11 12 13 14 // 上传操作true ,true ,"E:\\sunwukong.txt" ),"hdfs://hadoop202/xiyou/huaguoshan" )
HDFS_API 参数的优先级 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 /**false ,true ,"E:\\sunwukong.txt" ),"hdfs://hadoop202/xiyou/huaguoshan" )
在 resource 中创建 hdfs-site.xml, 然后上传文件, 发现副本数量是 1
1 2 3 4 5 6 7 8 9 <?xml version="1.0" encoding="UTF-8" ?>type ="text/xsl" href="configuration.xsl" ?>
修改 init 函数, configuration 中设置 dfs.replication 的值, 然后再次运行代码, 此时的副本数量是 2, 这就说明了这次运行的 dfs.replication 的值会覆盖掉 resource 中的 hdfs-site.xml 里的 dfs.replication 中的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Before"hdfs://hadoop202:8020" );"dfs.replication" , "2" );"xiamu" ;
HDFS_API 文件下载 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 // 文件下载true ,"hdfs://hadoop202/xiyou/huaguoshan" ),"E:\\huaguosan" ),true
HDFS_API 文件删除 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 // 删除"/jdk-8u212-linux-x64.tar.gz" ), false );"/xiyou" ), false );"/jinguo" ), true );
HDFS_API 文件更名和移动 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 // 文件的更名和移动"/input/word.txt" ), new Path("/input/ss.txt" ));"/input/ss.txt" ), new Path("/cls.txt" ));"/input" ), new Path("/output" ));
HDFS_API 文件详细查看 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 // 获取文件详细信息"/" ), true );while (listFiles.hasNext()) {"=======" + fileStatus.getPath() + "=======" );for (BlockLocation blockLocation : blockLocations) {
查询结果如下
1 2 3 4 5 6 7 8 9 10 =======hdfs://hadoop202:8020/hadoop-3.1.3.tar.gz=======
0,134217728 表示从 0 字节开始存放, 存放的大小是 134217728 字节
HDFS_API 文件和文件夹判断 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 // 判断是文件夹还是文件"/" ));for (FileStatus status : listStatus) {if (status.isFile()) {"这是一个文件: " + status.getPath().getName());else {"这是一个目录: " + status.getPath().getName());
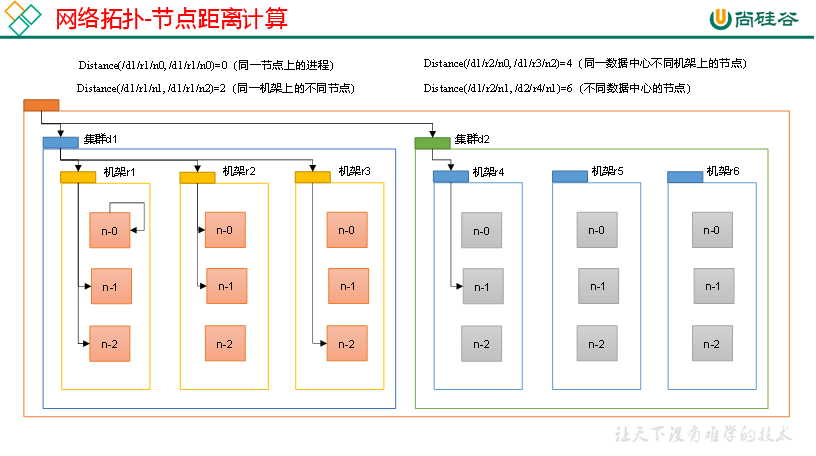
网络拓扑-节点距离计算 在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
oiv 查看 Fsimage 文件
1 2 3 [atguigu@hadoop102 current]$ hdfs
(2)基本语法hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
1 2 3 4 5 6 7 8 9 10 [atguigu@hadoop102 current]$ pwd cat /opt/module/hadoop-3.1.3/fsimage.xml
将显示的 xml 文件内容拷贝到 Idea 中创建的 xml 文件中,并格式化。部分显示结果如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 <inode>id >16386</id>type >DIRECTORY</type>id >16387</id>type >DIRECTORY</type>id >16389</id>type >FILE</type>id >1073741825</id>
思考:可以看出,Fsimage 中没有记录块所对应 DataNode,为什么?
oev 查看 Edits 文件 (1)基本语法hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
1 2 3 [atguigu@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xmlcat /opt/module/hadoop-3.1.3/edits.xml
将显示的 xml 文件内容拷贝到 Idea 中创建的 xml 文件中,并格式化。显示结果如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 <?xml version="1.0" encoding="UTF-8" ?>true </OVERWRITE>false </OVERWRITE>
思考:NameNode 如何确定下次开机启动的时候合并哪些 Edits?
CheckPoint 时间设置 通常情况下,SecondaryNameNode 每隔一小时执行一次。
1 2 3 4 <property>
2)一分钟检查一次操作次数,当操作次数达到 1 百万时,SecondaryNameNode 执行一次。
1 2 3 4 5 6 7 8 9 10 11 <property>
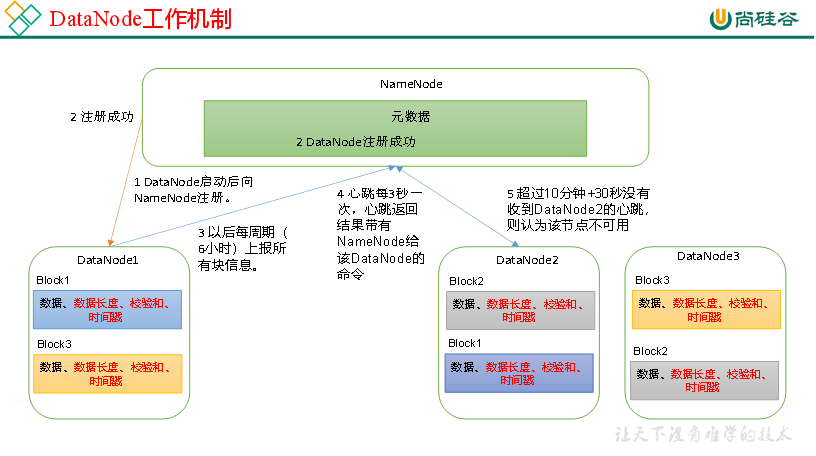
DataNode
1 2 3 4 5 <property>in milliseconds.</description>
DN 扫描自己节点块信息列表的时间,默认 6 小时
1 2 3 4 5 6 7 8 <property>in seconds for Datanode to scan data directories and reconcile the difference between blocks in memory and on the disk.case insensitive), as describedin dfs.heartbeat.interval.
(3)心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个 DataNode 的心跳,则认为该节点不可用。
 = 916259689.813 ≈ 9 亿
= 916259689.813 ≈ 9 亿