概念
linux 的配置 设置终端的字体大小
一些基本的配置
1 yum install net-tools wget zip unzip vim-enhanced net-tools -y
安装用于上传, 下载文件的工具包
配置静态 ip
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 TYPE="Ethernet" "none" "no" "static" "yes" "no" "yes" "yes" "yes" "no" "stable-privacy" "ens33" "a3b13aa9-1510-453c-8dc7-fab53450f73b" "ens33" "yes"
[root@hadoop200 ~]# vi /etc/hostname
[root@hadoop200 ~]# vi /etc/host
1 2 3 4 5 6 7 8 9 10 11
windows 中设置 host
1 2 3 4 5 6 7 8 9 192.168.1.200 hadoop200
关闭防火墙
1 2 3 [root@hadoop200 ~]
配置 atguigu 用户具有 root 权限,方便后期加 sudo 执行 root 权限的命令
1 2 3 4 5 6 root ALL=(ALL) ALL
注意:atguigu 这一行不要直接放到 root 行下面,因为所有用户都属于 wheel 组,你先配置了 atguigu 具有免密功能,但是程序执行到%wheel 行时,该功能又被覆盖回需要密码。所以 atguigu 要放到%wheel 这行下面。
1 2 3 4 5 6 7 8 [xiamu@hadoop200 opt]$ mkdir module/mkdir software/chown xiamu:xiamu module/ software/
卸载自带 jdk 删除 java
1 2 [root@hadoop100 ~]
重启之后的检查 hostname, ip, 以及能否 ping 通外网
安装 jdk 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "https://download.oracle.com/otn/java/jdk/8u212-b10/59066701cf1a433da9770636fbc4c9aa/jdk-8u212-linux-x64.tar.gz" cd /opt/module/jdk1.8.0_212/cd /etc/profile.d/export JAVA_HOME=/opt/module/jdk1.8.0_212export PATH=$PATH :$JAVA_HOME /binsource /etc/profile"1.8.0_212"
安装 Hadoop 1 2 3 4 5 6 7 8 9 10 [xiamu@hadoop202 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/export HADOOP_HOME=/opt/module/hadoop-3.1.3export PATH=$PATH :$HADOOP_HOME /binexport PATH=$PATH :$HADOOP_HOME /sbinsource /etc/profile
hadoop 目录
本地运行模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 mkdir wcinputcd wcinputcd wcoutput/cat part-r-00000
scp 拷贝命令 1 2 3 4 5 6 7 8 9
rsync 命令 1 2 3 4 5 6
xsync 集群分发脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 [xiamu@hadoop202 ~]$ cd /home/xiamu/mkdir bincd bin/if [ $# -lt 1 ]then echo Not Enough Arguement!exit ;fi for host in hadoop202 hadoop203 hadoop204do echo ==================== $host ====================for file in $@ do if [ -e $file ]then cd -P $(dirname $file ); pwd )basename $file )$host "mkdir -p $pdir " $pdir /$fname $host :$pdir else echo $file does not exists!fi done done chmod 777 xsynccp xsync /bin/source /etc/profilesource /etc/profile
设置 ssh 免密登录 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 [xiamu@hadoop202 .ssh]$ pwd cd .ssh/cat id_rsacat id_rsa.pub
集群配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 [xiamu@hadoop202 hadoop]$ vim core-site.xml"1.0" encoding="UTF-8" ?>type ="text/xsl" href="configuration.xsl" ?>in this file. -->"1.0" encoding="UTF-8" ?>type ="text/xsl" href="configuration.xsl" ?>in this file. -->"1.0" ?>"1.0" ?>type ="text/xsl" href="configuration.xsl" ?>in this file. -->
群起集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 [xiamu@hadoop202 hadoop]$ pwd
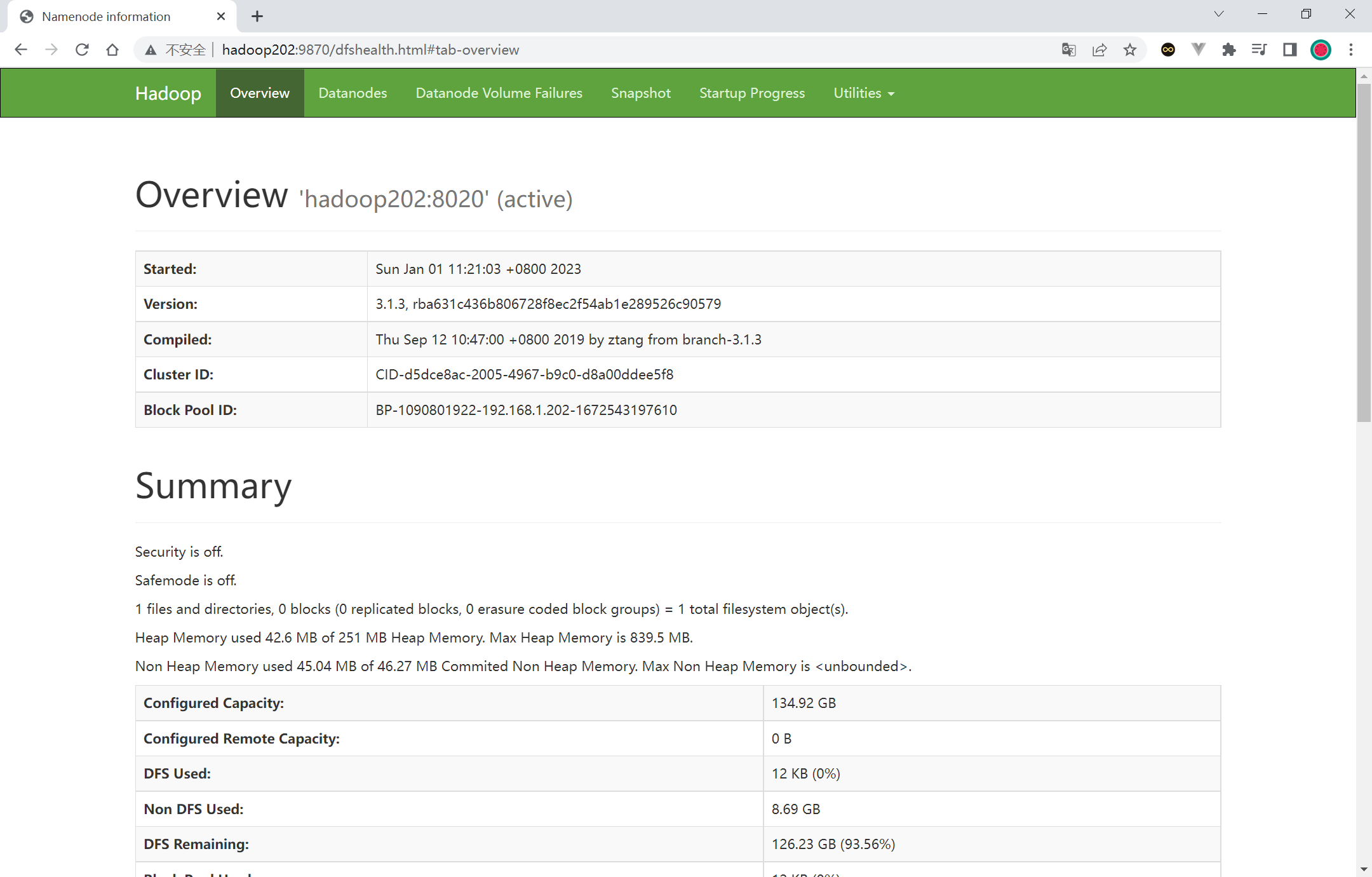
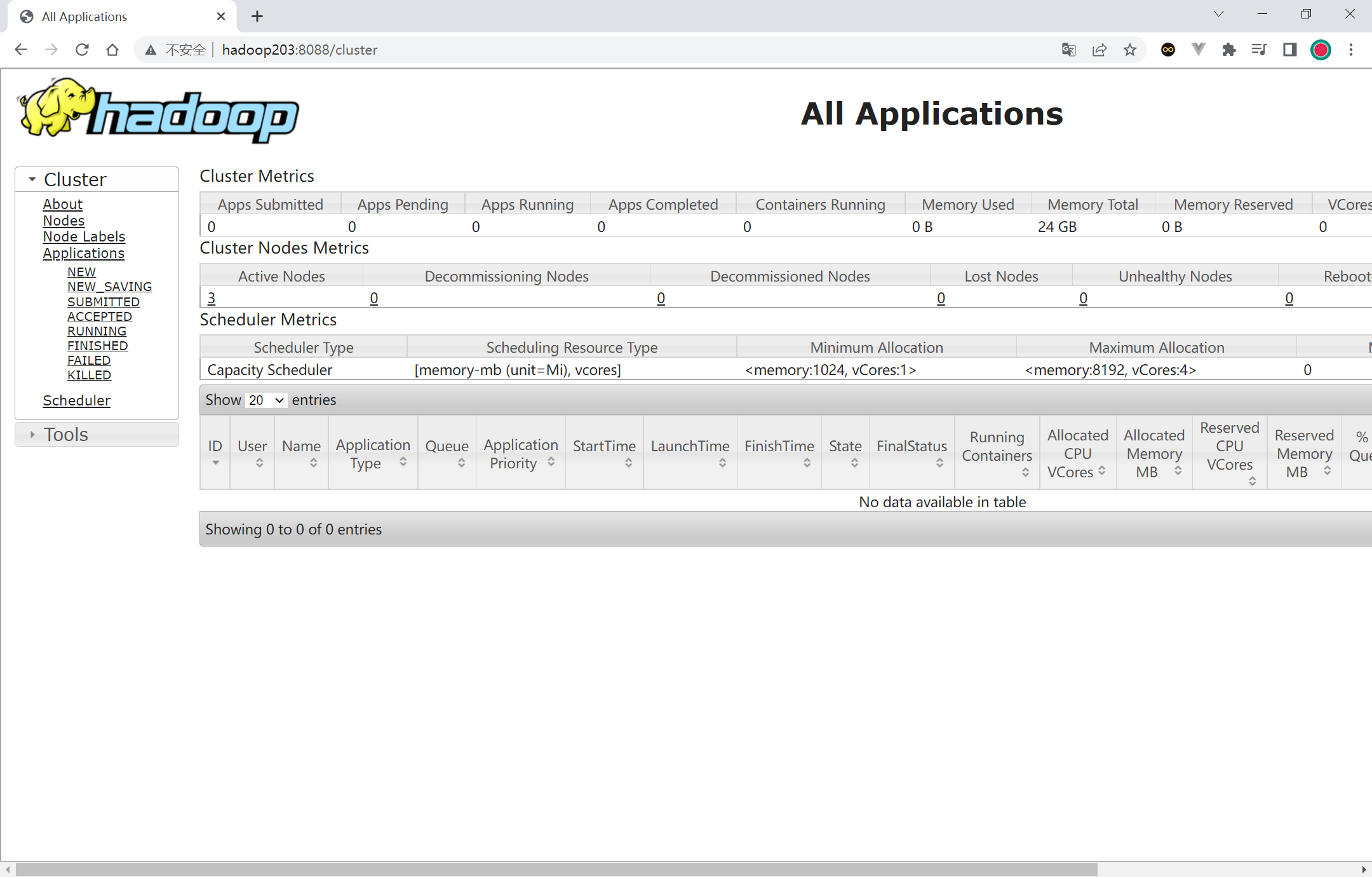
http://hadoop202:9870 http://hadoop203:8088/cluster
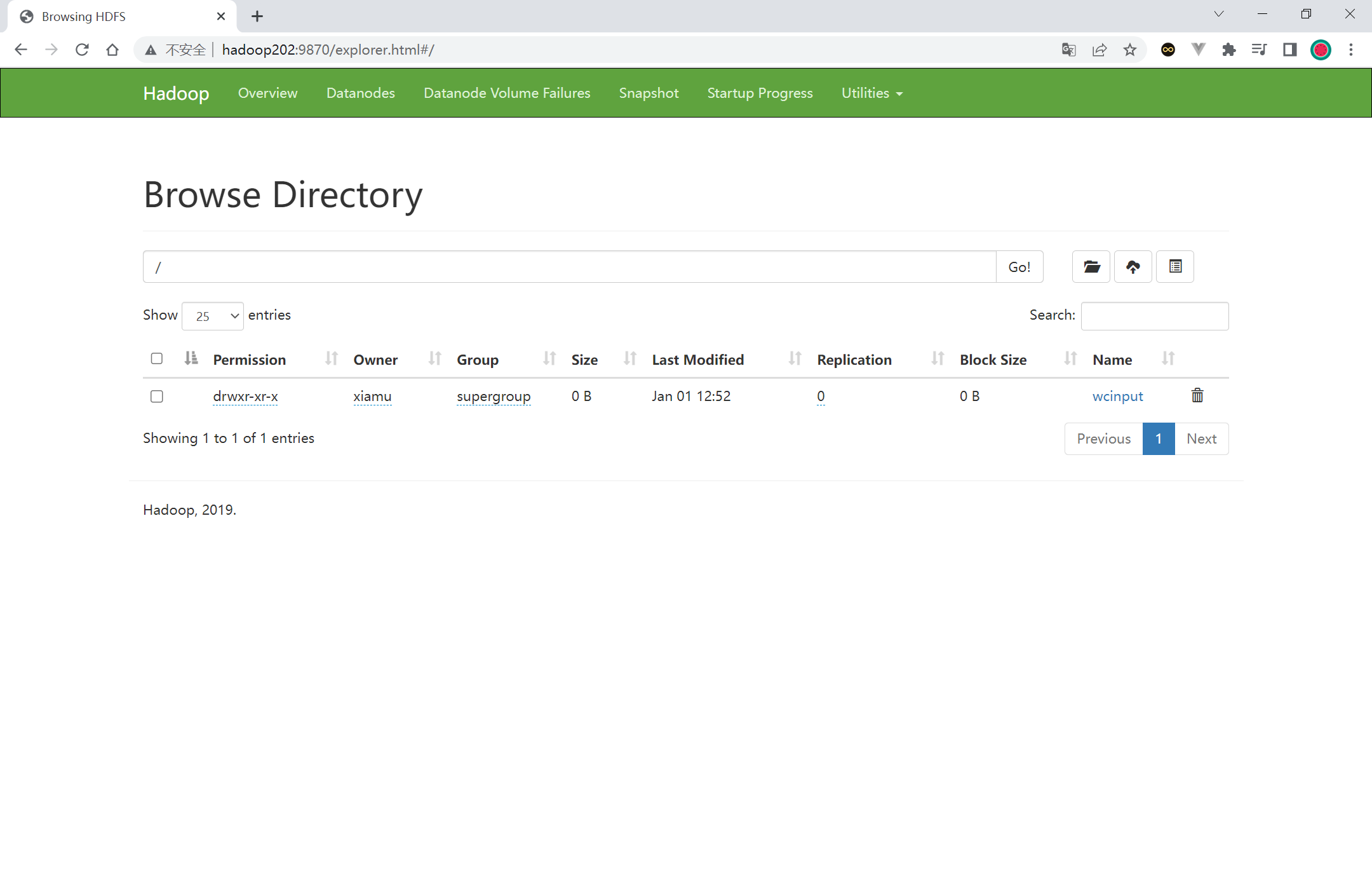
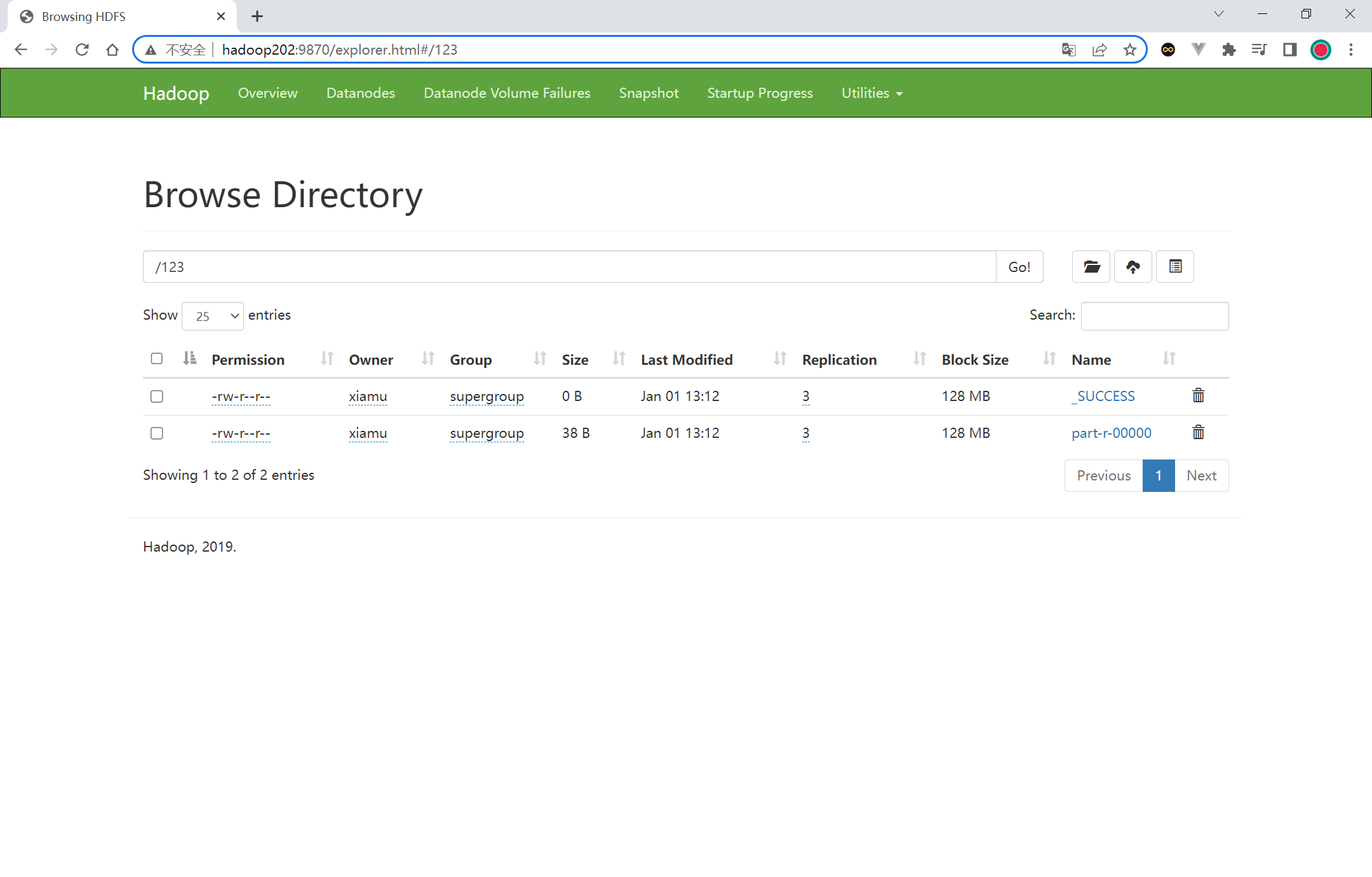
集群基本测试(上传文件) 1 2 3 4 5 [xiamu@hadoop202 hadoop-3.1.3]$ hadoop fs -mkdir /wcinput
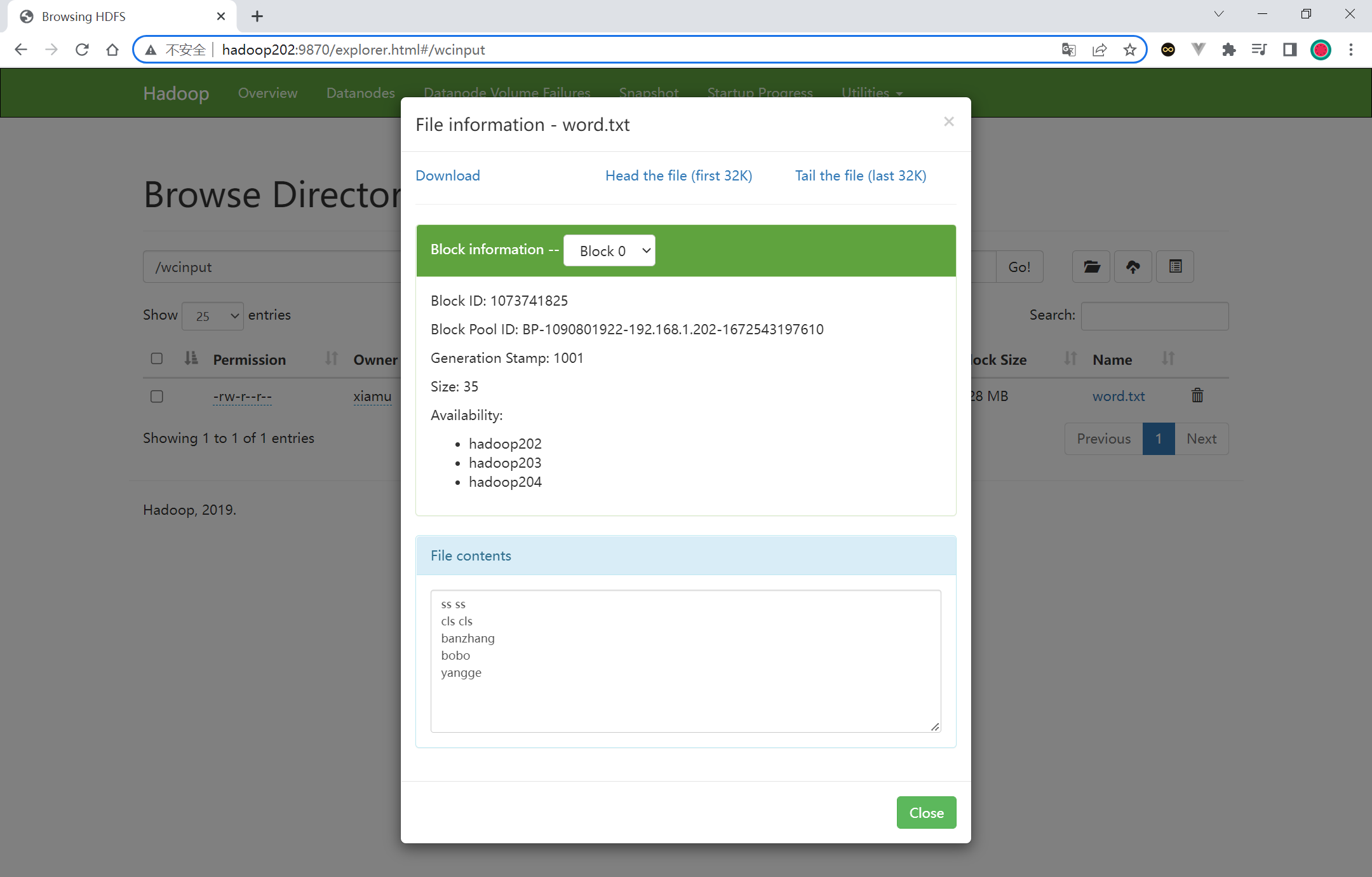
执行完成之后页面多了一个目录, 目录中包含着 word.txt 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 pwd ls cat blk_1073741826 >> tmp.tar.gzcat blk_1073741827 >> tmp.tar.gzls
集群崩溃重启方案 1 2 3 4 5 6 7 8 9 10 11 12 13 删除所有集群hadoop根目录下的data, log 目录
配置历史服务器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 [xiamu@hadoop202 hadoop]$ vim mapred-site.xmlmkdir /input
配置日志的聚集 日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [xiamu@hadoop202 hadoop]$ vim yarn-site.xmltrue </value>
从http://hadoop203:8088/cluster 访问, 查看当前正在执行的程序, 执行完成之后就可以点进去查看日志
编写 Hadoop 集群常用脚本 Hadoop 集群启停脚本(包含 HDFS,Yarn,Historyserver):myhadoop.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 [xiamu@hadoop202 ~]$ cd /home/xiamu/bin/if [ $# -lt 1 ]then echo "No Args Input..." exit ;fi case $1 in "start" )echo " =================== 启动 hadoop集群 ===================" echo " --------------- 启动 hdfs ---------------" "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver" "stop" )echo " =================== 关闭 hadoop集群 ===================" echo " --------------- 关闭 historyserver ---------------" "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh" echo "Input Args Error..." esac chmod 777 myhadoop.sh
查看三台服务器 Java 进程脚本:jpsall
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [xiamu@hadoop202 ~]$ cd /home/xiamu/binfor host in hadoop202 hadoop203 hadoop204do echo =============== $host ===============$host jpsdone chmod 777 jpsall
常用端口号 hadoop3.x
常用的配置文件 3.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml workers
集群的时间同步(可选) 一般来说, 集群连接了外网就可以不用配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 yes
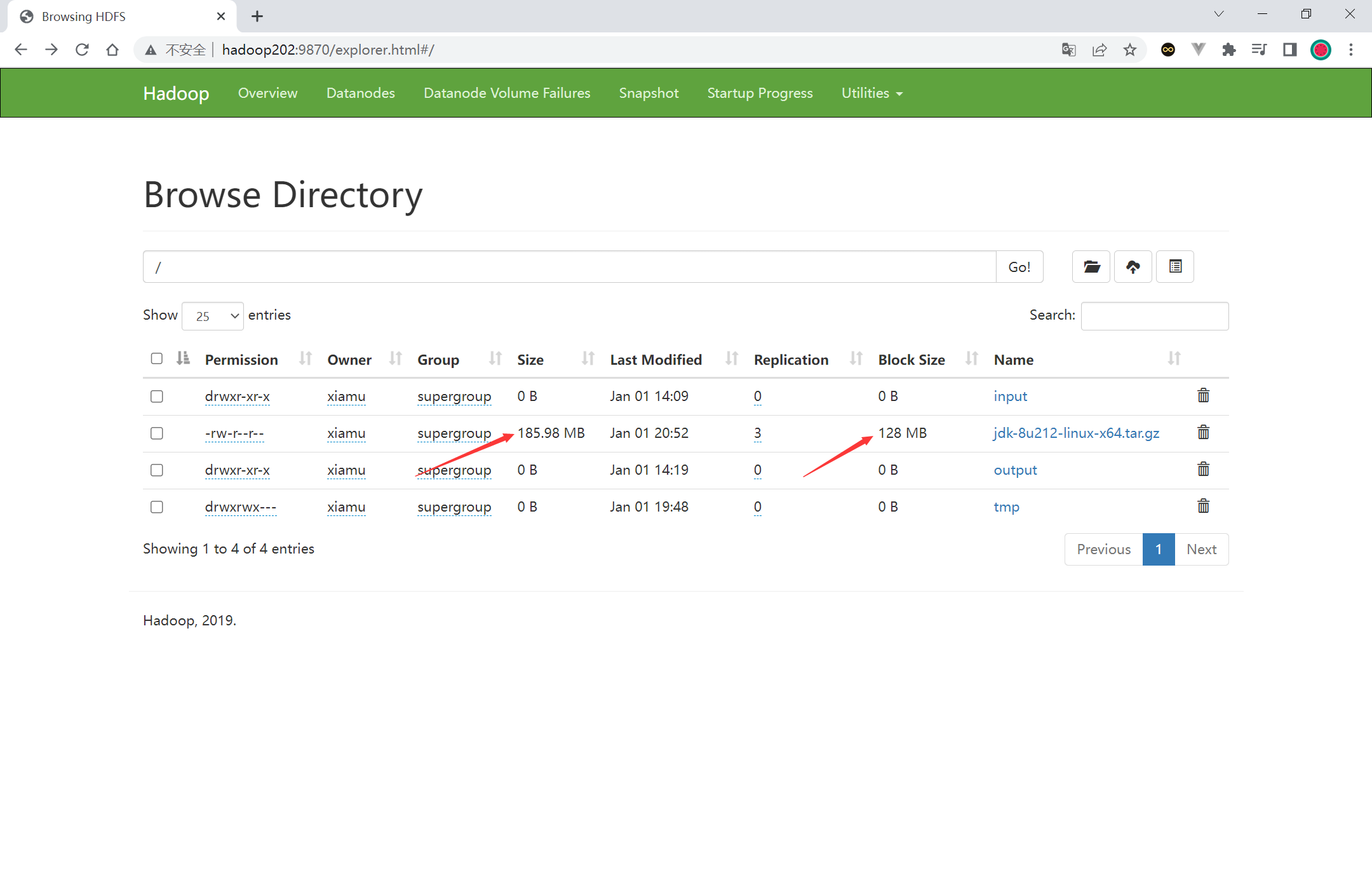
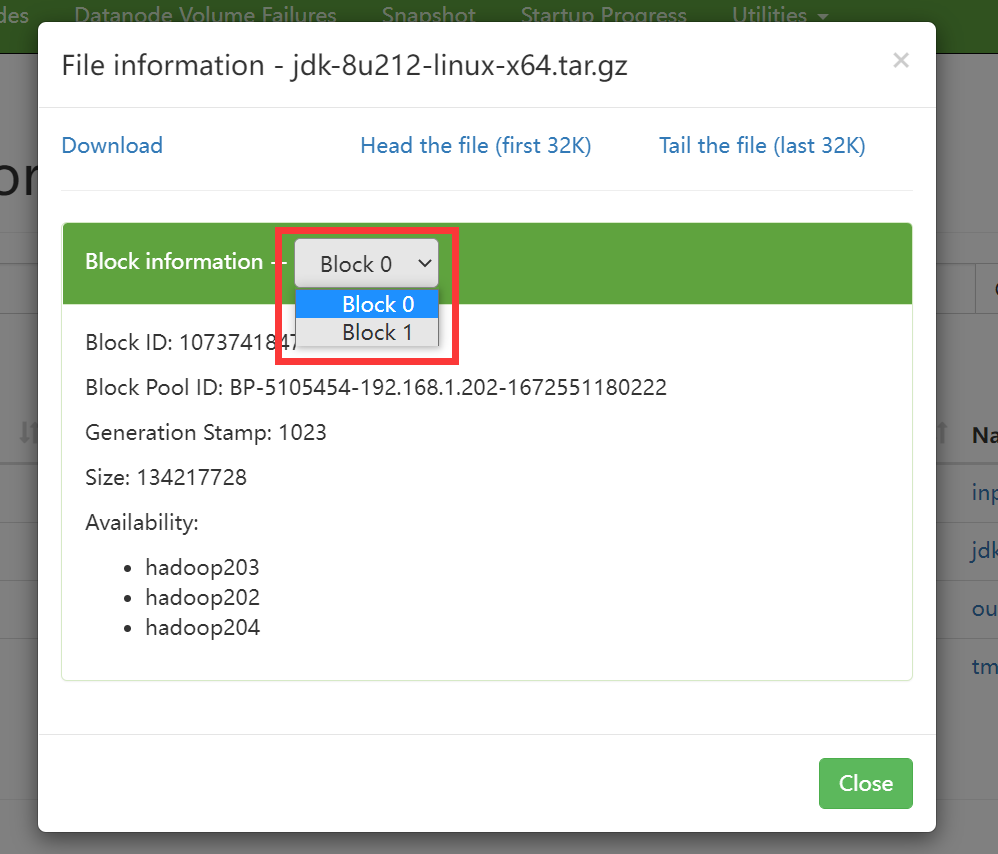
补充 1 [xiamu@hadoop202 ~]$ hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /
块大小是 128M, 但是 jdk 的大小超过了块大小, 所有 jdk 有两个块