编写 WordCount WordCountMapper 代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 /**" " );for (String word : words) {set (word);
WordCountDriver
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class WordCountDriver {"E:\\hadoop\\input" ));"E:\\hadoop\\output666" ));true );exit (result ? 0 : 1);
WordCountMapper
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 /**sum = 0;for (IntWritable value : values) {sum += value.get();set (sum );
测试 将代码打包上传到 hadoop, 然后进行测试
1 2 [xiamu@hadoop202 hadoop-3.1.3]$ hadoop jar wc.jar com.atguigu.mapreduce.wordcount2.WordCountDriver /input /output
Partition 分区 分区总结
例如: 假设自定义分区数为 5, 则
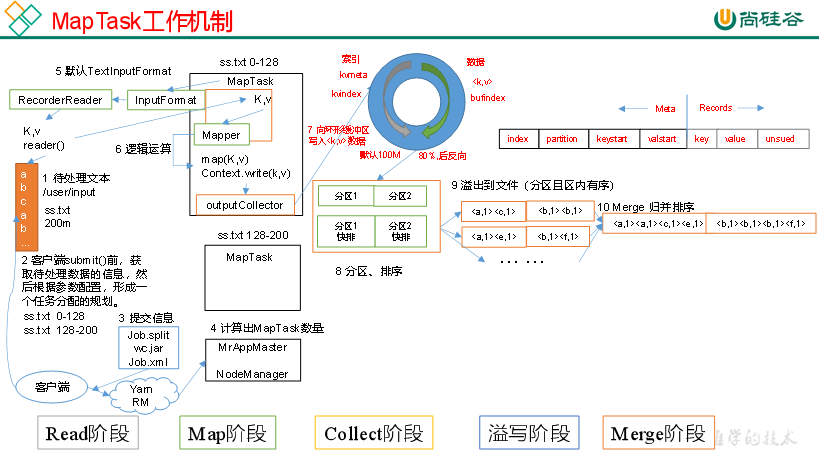
MapTask 工作机制 Read 阶段, Map 阶段, Collect 阶段, 溢写阶段, Merge 阶段
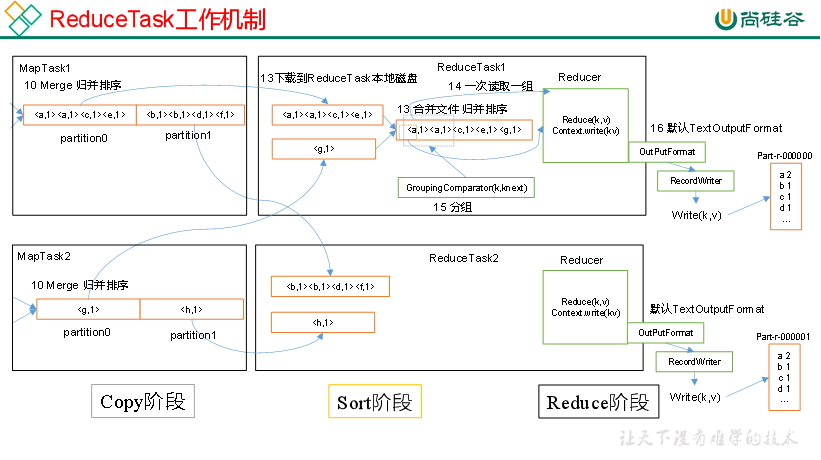
ReduceTask 工作机制 copy 阶段, sort 阶段, reduce 阶段