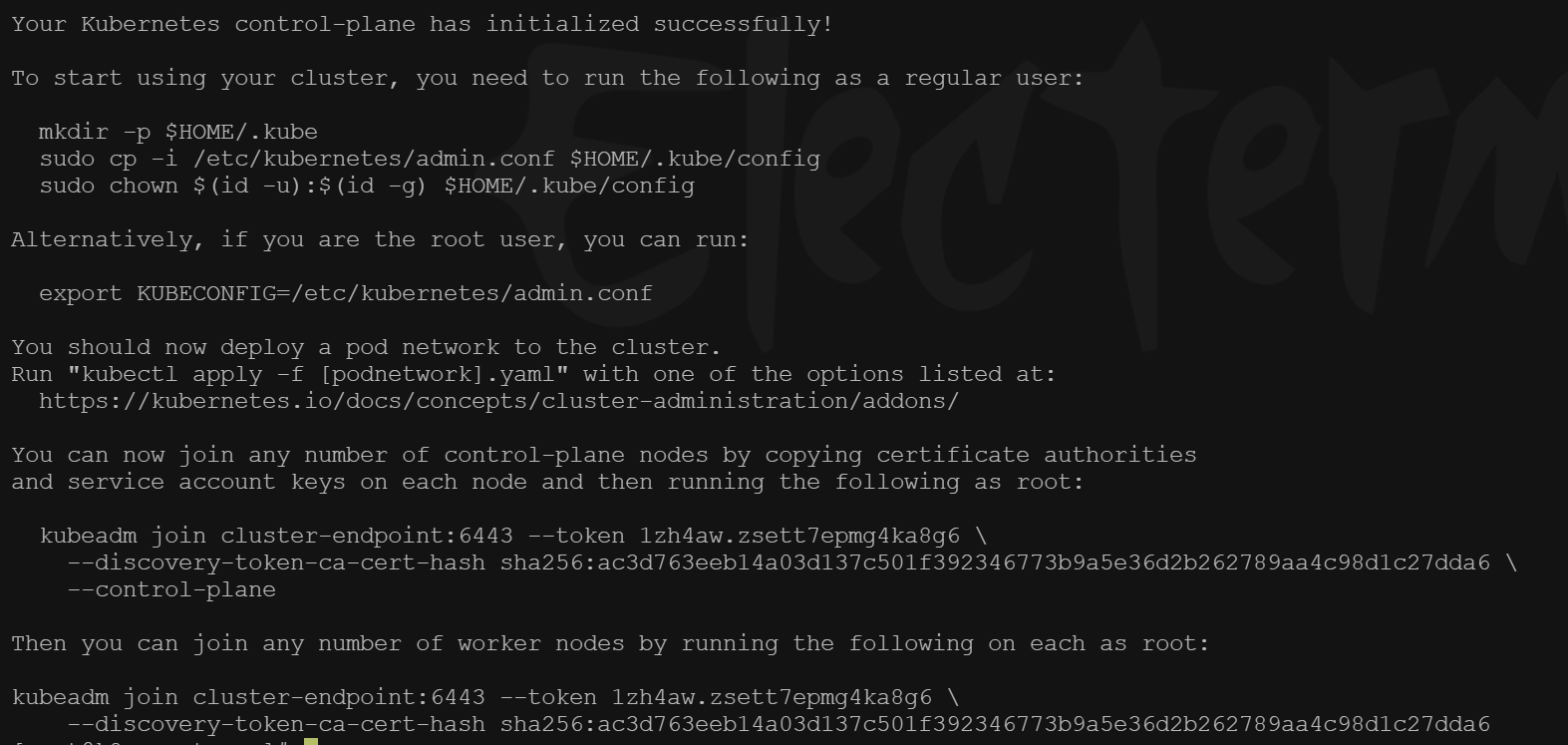
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root:
# 也可以指定查看default的pod, 不指定默认查看的就是default kubectl get pod -n default
# 描述mynginx的详细信息 kubectl describe pod mynginx
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 7m29s default-scheduler Successfully assigned default/mynginx to k8s-node2 Normal Pulling 7m28s kubelet Pulling image "nginx" Normal Pulled 7m20s kubelet Successfully pulled image "nginx"in 8.585906172s Normal Created 7m19s kubelet Created container mynginx Normal Started 7m19s kubelet Started container mynginx # 这里Scheduled说明了nginx创建在了k8s-node2
# STATUS显示Running表示创建的应用正在运行了 [root@k8s-master ~]# kubectl get pod NAME READY STATUS RESTARTS AGE mynginx 1/1 Running 0 3m47s
# 到k8s-node2上查看nginx容器 docker ps | grep mynginx
# 删除pod kubectl delete pod mynginx # 完整的写法可以指定命名空间 kubectl delete pod mynginx -n xxx
# 查看更完善的信息, 可以查看应用运行的IP # 每一个pod - k8s都会分配一个ip kubectl get pod -owide kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES mynginx 1/1 Running 0 3m38s 192.168.169.133 k8s-node2 <none> <none>
# 描述 kubectl describe pod nginx-pv-demo-5f8d846496-fjph9 # 此时是挂载失败了, 要先创建把/nfs/data/nginx-pv创建出来才能进行挂载 # Output: mount.nfs: mounting 172.31.0.204:/nfs/data/nginx-pv failed, reason given by server: No such file or directory
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root:
--- apiVersion:installer.kubesphere.io/v1alpha1 kind:ClusterConfiguration metadata: name:ks-installer namespace:kubesphere-system labels: version:v3.1.1 spec: persistence: storageClass:""# If there is no default StorageClass in your cluster, you need to specify an existing StorageClass here. authentication: jwtSecret:""# Keep the jwtSecret consistent with the Host Cluster. Retrieve the jwtSecret by executing "kubectl -n kubesphere-system get cm kubesphere-config -o yaml | grep -v "apiVersion" | grep jwtSecret" on the Host Cluster. local_registry:""# Add your private registry address if it is needed. etcd: monitoring:true# Enable or disable etcd monitoring dashboard installation. You have to create a Secret for etcd before you enable it. endpointIps:172.31.0.204# etcd cluster EndpointIps. It can be a bunch of IPs here. port:2379# etcd port. tlsEnable:true common: redis: enabled:true openldap: enabled:true minioVolumeSize:20Gi# Minio PVC size. openldapVolumeSize:2Gi# openldap PVC size. redisVolumSize:2Gi# Redis PVC size. monitoring: # type: external # Whether to specify the external prometheus stack, and need to modify the endpoint at the next line. endpoint:http://prometheus-operated.kubesphere-monitoring-system.svc:9090# Prometheus endpoint to get metrics data. es:# Storage backend for logging, events and auditing. # elasticsearchMasterReplicas: 1 # The total number of master nodes. Even numbers are not allowed. # elasticsearchDataReplicas: 1 # The total number of data nodes. elasticsearchMasterVolumeSize:4Gi# The volume size of Elasticsearch master nodes. elasticsearchDataVolumeSize:20Gi# The volume size of Elasticsearch data nodes. logMaxAge:7# Log retention time in built-in Elasticsearch. It is 7 days by default. elkPrefix:logstash# The string making up index names. The index name will be formatted as ks-<elk_prefix>-log. basicAuth: enabled:false username:"" password:"" externalElasticsearchUrl:"" externalElasticsearchPort:"" console: enableMultiLogin:true# Enable or disable simultaneous logins. It allows different users to log in with the same account at the same time. port:30880 alerting:# (CPU: 0.1 Core, Memory: 100 MiB) It enables users to customize alerting policies to send messages to receivers in time with different time intervals and alerting levels to choose from. enabled:true# Enable or disable the KubeSphere Alerting System. # thanosruler: # replicas: 1 # resources: {} auditing:# Provide a security-relevant chronological set of records,recording the sequence of activities happening on the platform, initiated by different tenants. enabled:true# Enable or disable the KubeSphere Auditing Log System. devops:# (CPU: 0.47 Core, Memory: 8.6 G) Provide an out-of-the-box CI/CD system based on Jenkins, and automated workflow tools including Source-to-Image & Binary-to-Image. enabled:true# Enable or disable the KubeSphere DevOps System. jenkinsMemoryLim:2Gi# Jenkins memory limit. jenkinsMemoryReq:1500Mi# Jenkins memory request. jenkinsVolumeSize:8Gi# Jenkins volume size. jenkinsJavaOpts_Xms:512m# The following three fields are JVM parameters. jenkinsJavaOpts_Xmx:512m jenkinsJavaOpts_MaxRAM:2g events:# Provide a graphical web console for Kubernetes Events exporting, filtering and alerting in multi-tenant Kubernetes clusters. enabled:true# Enable or disable the KubeSphere Events System. ruler: enabled:true replicas:2 logging:# (CPU: 57 m, Memory: 2.76 G) Flexible logging functions are provided for log query, collection and management in a unified console. Additional log collectors can be added, such as Elasticsearch, Kafka and Fluentd. enabled:true# Enable or disable the KubeSphere Logging System. logsidecar: enabled:true replicas:2 metrics_server:# (CPU: 56 m, Memory: 44.35 MiB) It enables HPA (Horizontal Pod Autoscaler). enabled:false# Enable or disable metrics-server. monitoring: storageClass:""# If there is an independent StorageClass you need for Prometheus, you can specify it here. The default StorageClass is used by default. # prometheusReplicas: 1 # Prometheus replicas are responsible for monitoring different segments of data source and providing high availability. prometheusMemoryRequest:400Mi# Prometheus request memory. prometheusVolumeSize:20Gi# Prometheus PVC size. # alertmanagerReplicas: 1 # AlertManager Replicas. multicluster: clusterRole:none# host | member | none # You can install a solo cluster, or specify it as the Host or Member Cluster. network: networkpolicy:# Network policies allow network isolation within the same cluster, which means firewalls can be set up between certain instances (Pods). # Make sure that the CNI network plugin used by the cluster supports NetworkPolicy. There are a number of CNI network plugins that support NetworkPolicy, including Calico, Cilium, Kube-router, Romana and Weave Net. enabled:true# Enable or disable network policies. ippool:# Use Pod IP Pools to manage the Pod network address space. Pods to be created can be assigned IP addresses from a Pod IP Pool. type:calico# Specify "calico" for this field if Calico is used as your CNI plugin. "none" means that Pod IP Pools are disabled. topology:# Use Service Topology to view Service-to-Service communication based on Weave Scope. type:none# Specify "weave-scope" for this field to enable Service Topology. "none" means that Service Topology is disabled. openpitrix:# An App Store that is accessible to all platform tenants. You can use it to manage apps across their entire lifecycle. store: enabled:true# Enable or disable the KubeSphere App Store. servicemesh:# (0.3 Core, 300 MiB) Provide fine-grained traffic management, observability and tracing, and visualized traffic topology. enabled:true# Base component (pilot). Enable or disable KubeSphere Service Mesh (Istio-based). kubeedge:# Add edge nodes to your cluster and deploy workloads on edge nodes. enabled:true# Enable or disable KubeEdge. cloudCore: nodeSelector: {"node-role.kubernetes.io/worker":""} tolerations: [] cloudhubPort:"10000" cloudhubQuicPort:"10001" cloudhubHttpsPort:"10002" cloudstreamPort:"10003" tunnelPort:"10004" cloudHub: advertiseAddress:# At least a public IP address or an IP address which can be accessed by edge nodes must be provided. -""# Note that once KubeEdge is enabled, CloudCore will malfunction if the address is not provided. nodeLimit:"100" service: cloudhubNodePort:"30000" cloudhubQuicNodePort:"30001" cloudhubHttpsNodePort:"30002" cloudstreamNodePort:"30003" tunnelNodePort:"30004" edgeWatcher: nodeSelector: {"node-role.kubernetes.io/worker":""} tolerations: [] edgeWatcherAgent: nodeSelector: {"node-role.kubernetes.io/worker":""} tolerations: []
##################################################### ### Welcome to KubeSphere! ### #####################################################
Console: http://172.31.0.2:30880 Account: admin Password: P@88w0rd NOTES: 1. After you log into the console, please check the monitoring status of service components in "Cluster Management". If any service is not ready, please wait patiently until all components are up and running. 2. Please change the default password after login.
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f
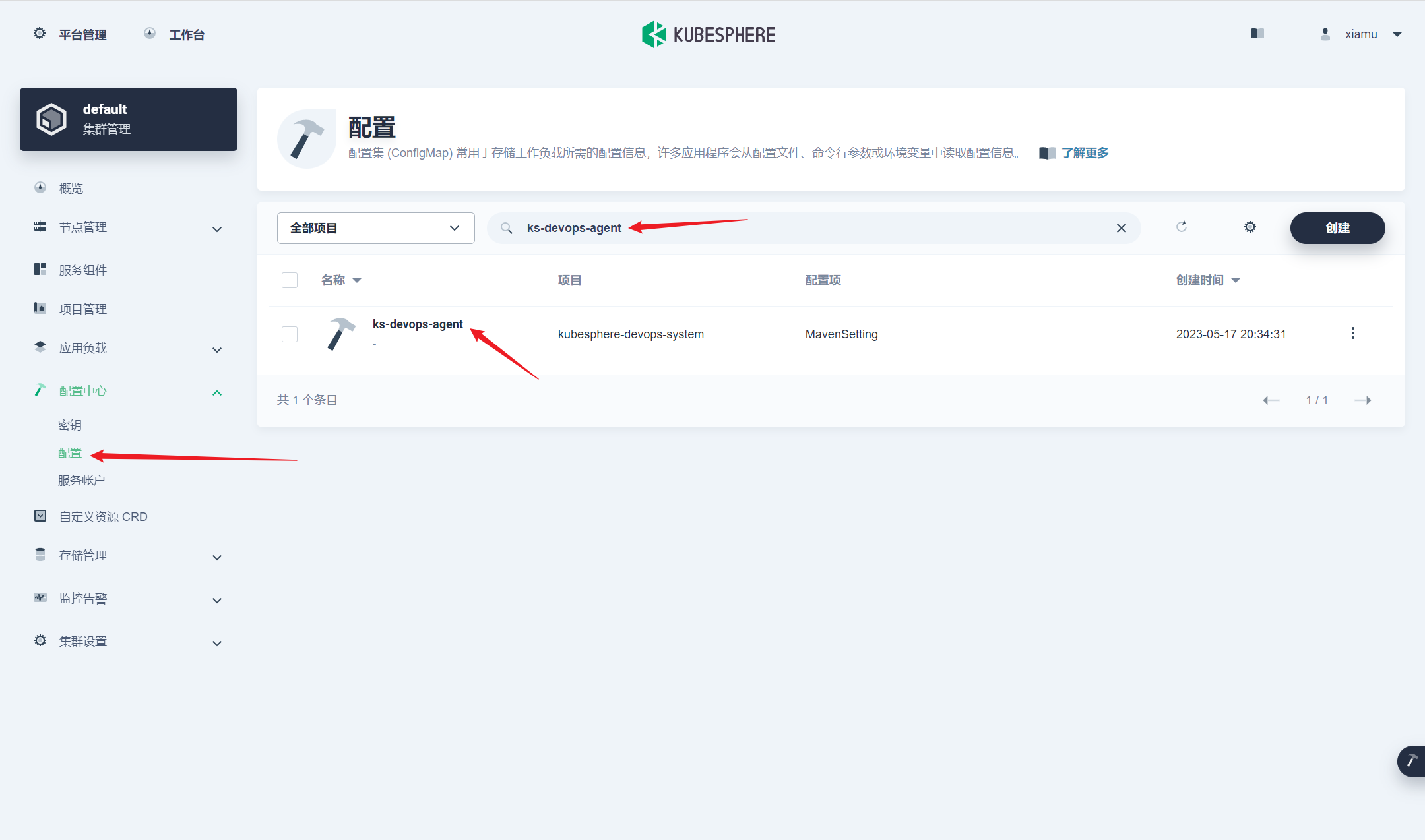
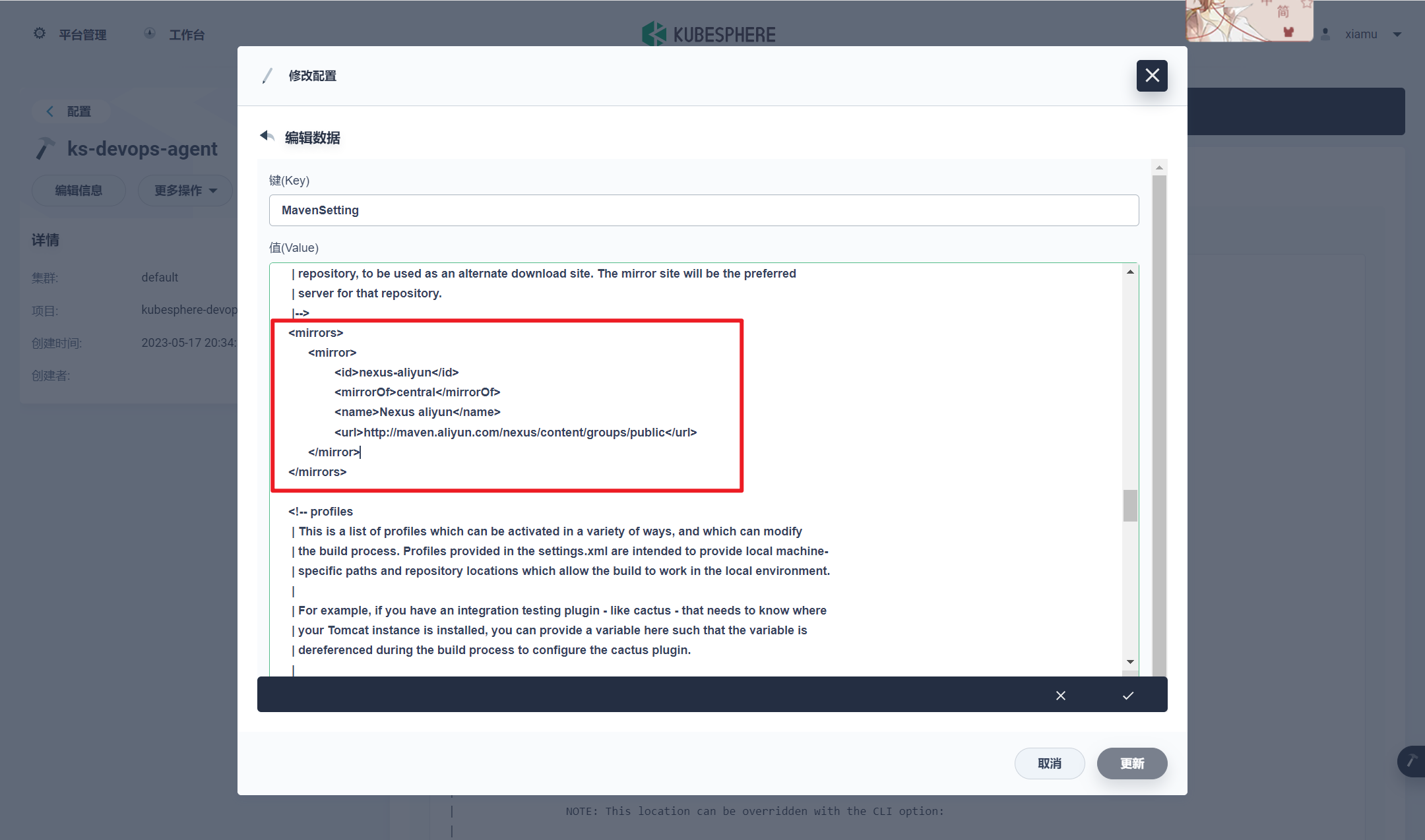
这种方式安装是最小安装, 如果想开启其他功能可以在自定义资源进行开启
另外遇到的一个bug
1 2 3 4 5 6 7 8
# 使用kk脚本之后, 出现的recognize "/etc/kubernetes/network-plugin.yaml" error: unable to recognize "/etc/kubernetes/network-plugin.yaml": no matches for kind "PodDisruptionBudget"in version "policy/v1"
##################################################### ### Welcome to KubeSphere! ### #####################################################
Console: http://172.31.0.2:30880 Account: admin Password: P@88w0rd NOTES: 1. After you log into the console, please check the monitoring status of service components in "Cluster Management". If any service is not ready, please wait patiently until all components are up and running. 2. Please change the default password after login.
cat jvm.options ################################################################ ## ## JVM configuration ## ################################################################ ## ## WARNING: DO NOT EDIT THIS FILE. If you want to override the ## JVM options in this file, or set any additional options, you ## should create one or more files in the jvm.options.d ## directory containing your adjustments. ## ## See https://www.elastic.co/guide/en/elasticsearch/reference/current/jvm-options.html ## for more information. ## ################################################################
################################################################ ## IMPORTANT: JVM heap size ################################################################ ## ## The heap size is automatically configured by Elasticsearch ## based on the available memory in your system and the roles ## each node is configured to fulfill. If specifying heap is ## required, it should be done through a file in jvm.options.d, ## and the min and max should be set to the same value. For ## example, to set the heap to 4 GB, create a new file in the ## jvm.options.d directory containing these lines: ## ## -Xms4g ## -Xmx4g ## ## See https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html ## for more information ## ################################################################
################################################################ ## Expert settings ################################################################ ## ## All settings below here are considered expert settings. Do ## not adjust them unless you understand what you are doing. Do ## not edit them in this file; instead, create a new file in the ## jvm.options.d directory containing your adjustments. ## ################################################################
## G1GC Configuration # NOTE: G1 GC is only supported on JDK version 10 or later # to use G1GC, uncomment the next two lines and update the version on the # following three lines to your version of the JDK # 10-13:-XX:-UseConcMarkSweepGC # 10-13:-XX:-UseCMSInitiatingOccupancyOnly 14-:-XX:+UseG1GC
# generate a heap dump when an allocation from the Java heap fails; heap dumps # are created in the working directory of the JVM unless an alternative path is # specified -XX:+HeapDumpOnOutOfMemoryError
# specify an alternative path for heap dumps; ensure the directory exists and # has sufficient space -XX:HeapDumpPath=data
# specify an alternative path for JVM fatal error logs -XX:ErrorFile=logs/hs_err_pid%p.log
#*************** Config Module Related Configurations ***************# ### If use MySQL as datasource: ### Deprecated configuration property, it is recommended to use `spring.sql.init.platform` replaced. # spring.datasource.platform=mysql spring.sql.init.platform=mysql
### Count of DB: db.num=1
### Connect URL of DB: db.url.0=jdbc:mysql://127.0.0.1:3306/nacos1?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user.0=root db.password.0=123456
# # Copyright 1999-2021 Alibaba Group Holding Ltd. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. #
#*************** Spring Boot Related Configurations ***************# ### Default web context path: server.servlet.contextPath=/nacos ### Include message field server.error.include-message=ALWAYS ### Default web server port: server.port=8848
#*************** Network Related Configurations ***************# ### If prefer hostname over ip for Nacos server addresses in cluster.conf: # nacos.inetutils.prefer-hostname-over-ip=false
### Specify local server's IP: # nacos.inetutils.ip-address=
#*************** Config Module Related Configurations ***************# ### If use MySQL as datasource: ### Deprecated configuration property, it is recommended to use `spring.sql.init.platform` replaced. spring.datasource.platform=mysql # spring.sql.init.platform=mysql
### Count of DB: db.num=1
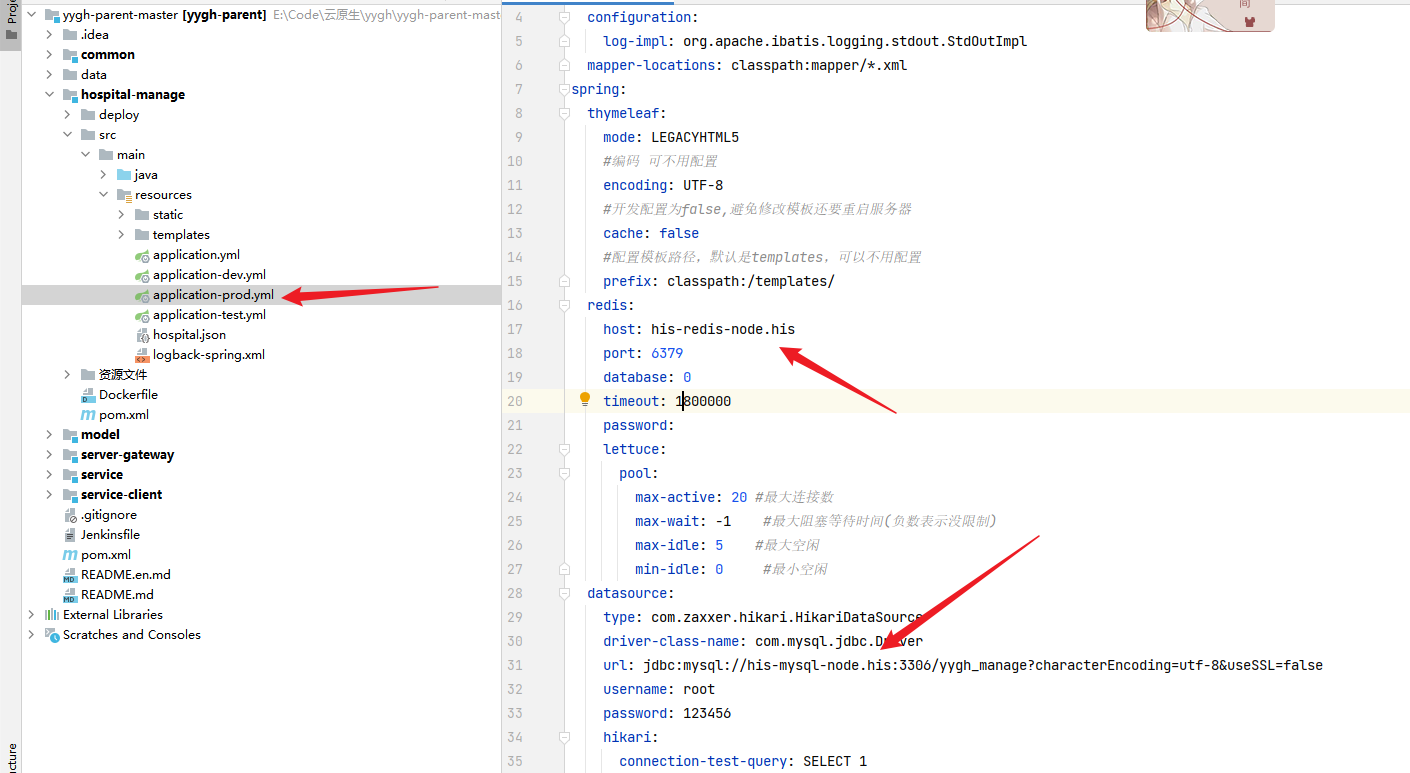
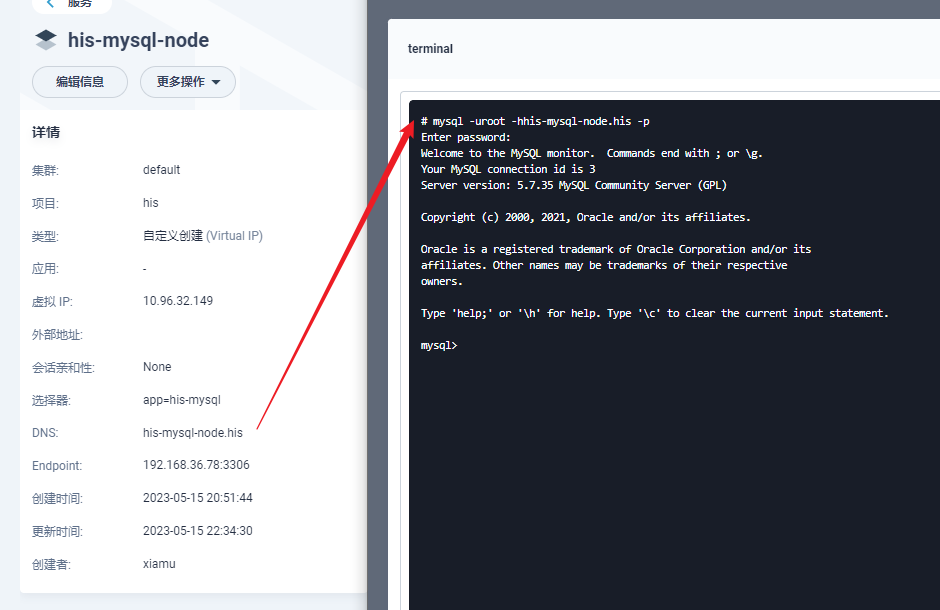
### Connect URL of DB: db.url.0=jdbc:mysql://his-mysql-node.his:3306/ry-config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user.0=root db.password.0=123456
### Connection pool configuration: hikariCP db.pool.config.connectionTimeout=30000 db.pool.config.validationTimeout=10000 db.pool.config.maximumPoolSize=20 db.pool.config.minimumIdle=2
#*************** Naming Module Related Configurations ***************#
### If enable data warmup. If set to false, the server would accept request without local data preparation: # nacos.naming.data.warmup=true
### If enable the instance auto expiration, kind like of health check of instance: # nacos.naming.expireInstance=true
### Add in 2.0.0 ### The interval to clean empty service, unit: milliseconds. # nacos.naming.clean.empty-service.interval=60000
### The expired time to clean empty service, unit: milliseconds. # nacos.naming.clean.empty-service.expired-time=60000
### The interval to clean expired metadata, unit: milliseconds. # nacos.naming.clean.expired-metadata.interval=5000
### The expired time to clean metadata, unit: milliseconds. # nacos.naming.clean.expired-metadata.expired-time=60000
### The delay time before push task to execute from service changed, unit: milliseconds. # nacos.naming.push.pushTaskDelay=500
### The timeout for push task execute, unit: milliseconds. # nacos.naming.push.pushTaskTimeout=5000
### The delay time for retrying failed push task, unit: milliseconds. # nacos.naming.push.pushTaskRetryDelay=1000
### Since 2.0.3 ### The expired time for inactive client, unit: milliseconds. # nacos.naming.client.expired.time=180000
#*************** CMDB Module Related Configurations ***************# ### The interval to dump external CMDB in seconds: # nacos.cmdb.dumpTaskInterval=3600
### The interval of polling data change event in seconds: # nacos.cmdb.eventTaskInterval=10
### The interval of loading labels in seconds: # nacos.cmdb.labelTaskInterval=300
### If turn on data loading task: # nacos.cmdb.loadDataAtStart=false
#*************** Metrics Related Configurations ***************# ### Metrics for prometheus #management.endpoints.web.exposure.include=*
### Metrics for elastic search management.metrics.export.elastic.enabled=false #management.metrics.export.elastic.host=http://localhost:9200
### Metrics for influx management.metrics.export.influx.enabled=false #management.metrics.export.influx.db=springboot #management.metrics.export.influx.uri=http://localhost:8086 #management.metrics.export.influx.auto-create-db=true #management.metrics.export.influx.consistency=one #management.metrics.export.influx.compressed=true
#*************** Access Log Related Configurations ***************# ### If turn on the access log: server.tomcat.accesslog.enabled=true
### The directory of access log: server.tomcat.basedir=file:.
#*************** Access Control Related Configurations ***************# ### If enable spring security, this option is deprecated in 1.2.0: #spring.security.enabled=false
### The ignore urls of auth nacos.security.ignore.urls=/,/error,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.ico,/console-ui/public/**,/v1/auth/**,/v1/console/health/**,/actuator/**,/v1/console/server/**
### The auth system to use, currently only 'nacos' and 'ldap' is supported: nacos.core.auth.system.type=nacos
### If turn on auth system: nacos.core.auth.enabled=false
### Turn on/off caching of auth information. By turning on this switch, the update of auth information would have a 15 seconds delay. nacos.core.auth.caching.enabled=true
### Since 1.4.1, Turn on/off white auth for user-agent: nacos-server, only for upgrade from old version. nacos.core.auth.enable.userAgentAuthWhite=false
### Since 1.4.1, worked when nacos.core.auth.enabled=true and nacos.core.auth.enable.userAgentAuthWhite=false. ### The two properties is the white list for auth and used by identity the request from other server. nacos.core.auth.server.identity.key= nacos.core.auth.server.identity.value=
### worked when nacos.core.auth.system.type=nacos ### The token expiration in seconds: nacos.core.auth.plugin.nacos.token.cache.enable=false nacos.core.auth.plugin.nacos.token.expire.seconds=18000 ### The default token (Base64 String): nacos.core.auth.plugin.nacos.token.secret.key=
### worked when nacos.core.auth.system.type=ldap,{0} is Placeholder,replace login username #nacos.core.auth.ldap.url=ldap://localhost:389 #nacos.core.auth.ldap.basedc=dc=example,dc=org #nacos.core.auth.ldap.userDn=cn=admin,${nacos.core.auth.ldap.basedc} #nacos.core.auth.ldap.password=admin #nacos.core.auth.ldap.userdn=cn={0},dc=example,dc=org #nacos.core.auth.ldap.filter.prefix=uid #nacos.core.auth.ldap.case.sensitive=true
#*************** Istio Related Configurations ***************# ### If turn on the MCP server: nacos.istio.mcp.server.enabled=false
#*************** Core Related Configurations ***************#
### set the WorkerID manually # nacos.core.snowflake.worker-id=
### MemberLookup ### Addressing pattern category, If set, the priority is highest # nacos.core.member.lookup.type=[file,address-server] ## Set the cluster list with a configuration file or command-line argument # nacos.member.list=192.168.16.101:8847?raft_port=8807,192.168.16.101?raft_port=8808,192.168.16.101:8849?raft_port=8809 ## for AddressServerMemberLookup # Maximum number of retries to query the address server upon initialization # nacos.core.address-server.retry=5 ## Server domain name address of [address-server] mode # address.server.domain=jmenv.tbsite.net ## Server port of [address-server] mode # address.server.port=8080 ## Request address of [address-server] mode # address.server.url=/nacos/serverlist
#*************** JRaft Related Configurations ***************#
### Sets the Raft cluster election timeout, default value is 5 second # nacos.core.protocol.raft.data.election_timeout_ms=5000 ### Sets the amount of time the Raft snapshot will execute periodically, default is 30 minute # nacos.core.protocol.raft.data.snapshot_interval_secs=30 ### raft internal worker threads # nacos.core.protocol.raft.data.core_thread_num=8 ### Number of threads required for raft business request processing # nacos.core.protocol.raft.data.cli_service_thread_num=4 ### raft linear read strategy. Safe linear reads are used by default, that is, the Leader tenure is confirmed by heartbeat # nacos.core.protocol.raft.data.read_index_type=ReadOnlySafe ### rpc request timeout, default 5 seconds # nacos.core.protocol.raft.data.rpc_request_timeout_ms=5000
#*************** Distro Related Configurations ***************#
### Distro data sync delay time, when sync task delayed, task will be merged for same data key. Default 1 second. # nacos.core.protocol.distro.data.sync.delayMs=1000
### Distro data sync timeout for one sync data, default 3 seconds. # nacos.core.protocol.distro.data.sync.timeoutMs=3000
### Distro data sync retry delay time when sync data failed or timeout, same behavior with delayMs, default 3 seconds. # nacos.core.protocol.distro.data.sync.retryDelayMs=3000
### Distro data verify interval time, verify synced data whether expired for a interval. Default 5 seconds. # nacos.core.protocol.distro.data.verify.intervalMs=5000
### Distro data verify timeout for one verify, default 3 seconds. # nacos.core.protocol.distro.data.verify.timeoutMs=3000
### Distro data load retry delay when load snapshot data failed, default 30 seconds. # nacos.core.protocol.distro.data.load.retryDelayMs=30000
### enable to support prometheus service discovery #nacos.prometheus.metrics.enabled=true
### Since 2.3 #*************** Grpc Configurations ***************#
## sdk grpc(between nacos server and client) configuration ## Sets the maximum message size allowed to be received on the server. #nacos.remote.server.grpc.sdk.max-inbound-message-size=10485760
## Sets the time(milliseconds) without read activity before sending a keepalive ping. The typical default is two hours. #nacos.remote.server.grpc.sdk.keep-alive-time=7200000
## Sets a time(milliseconds) waiting for read activity after sending a keepalive ping. Defaults to 20 seconds. #nacos.remote.server.grpc.sdk.keep-alive-timeout=20000
## Sets a time(milliseconds) that specify the most aggressive keep-alive time clients are permitted to configure. The typical default is 5 minutes #nacos.remote.server.grpc.sdk.permit-keep-alive-time=300000
## cluster grpc(inside the nacos server) configuration #nacos.remote.server.grpc.cluster.max-inbound-message-size=10485760
## Sets the time(milliseconds) without read activity before sending a keepalive ping. The typical default is two hours. #nacos.remote.server.grpc.cluster.keep-alive-time=7200000
## Sets a time(milliseconds) waiting for read activity after sending a keepalive ping. Defaults to 20 seconds. #nacos.remote.server.grpc.cluster.keep-alive-timeout=20000
## Sets a time(milliseconds) that specify the most aggressive keep-alive time clients are permitted to configure. The typical default is 5 minutes #nacos.remote.server.grpc.cluster.permit-keep-alive-time=300000
# # Copyright 1999-2021 Alibaba Group Holding Ltd. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. #
#it is ip #example his-nacos-v1-0.his-nacos.his.svc.cluster.local:8848 his-nacos-v1-1.his-nacos.his.svc.cluster.local:8848 his-nacos-v1-2.his-nacos.his.svc.cluster.local:8848
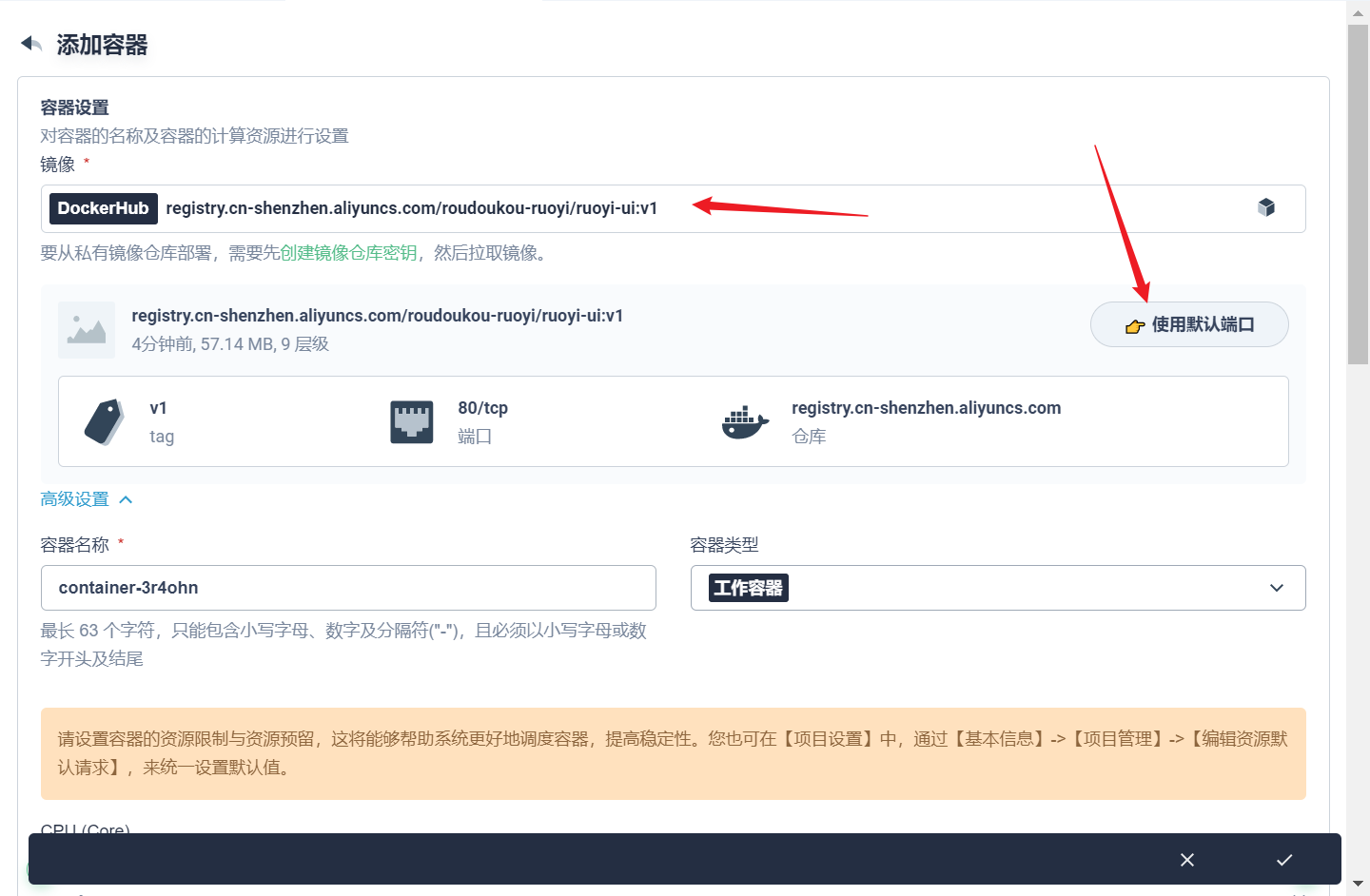
# 查看镜像 [root@k8s-master ruoyi-system]# docker images | grep ruoyi ruoyi-auth v1 0db642b44949 4 seconds ago 617MB ruoyi-system v1 c0b63feca088 8 minutes ago 632MB ruoyi-monitor v1 b0f479101e96 10 minutes ago 592MB ruoyi-job v1 fd3bcefdb9d0 10 minutes ago 629MB ruoyi-gen v1 df9dae1e1581 10 minutes ago 628MB ruoyi-gateway v1 1a37fc67241f 13 minutes ago 625MB ruoyi-file v1 85a54d4c38ea 15 minutes ago 622MB
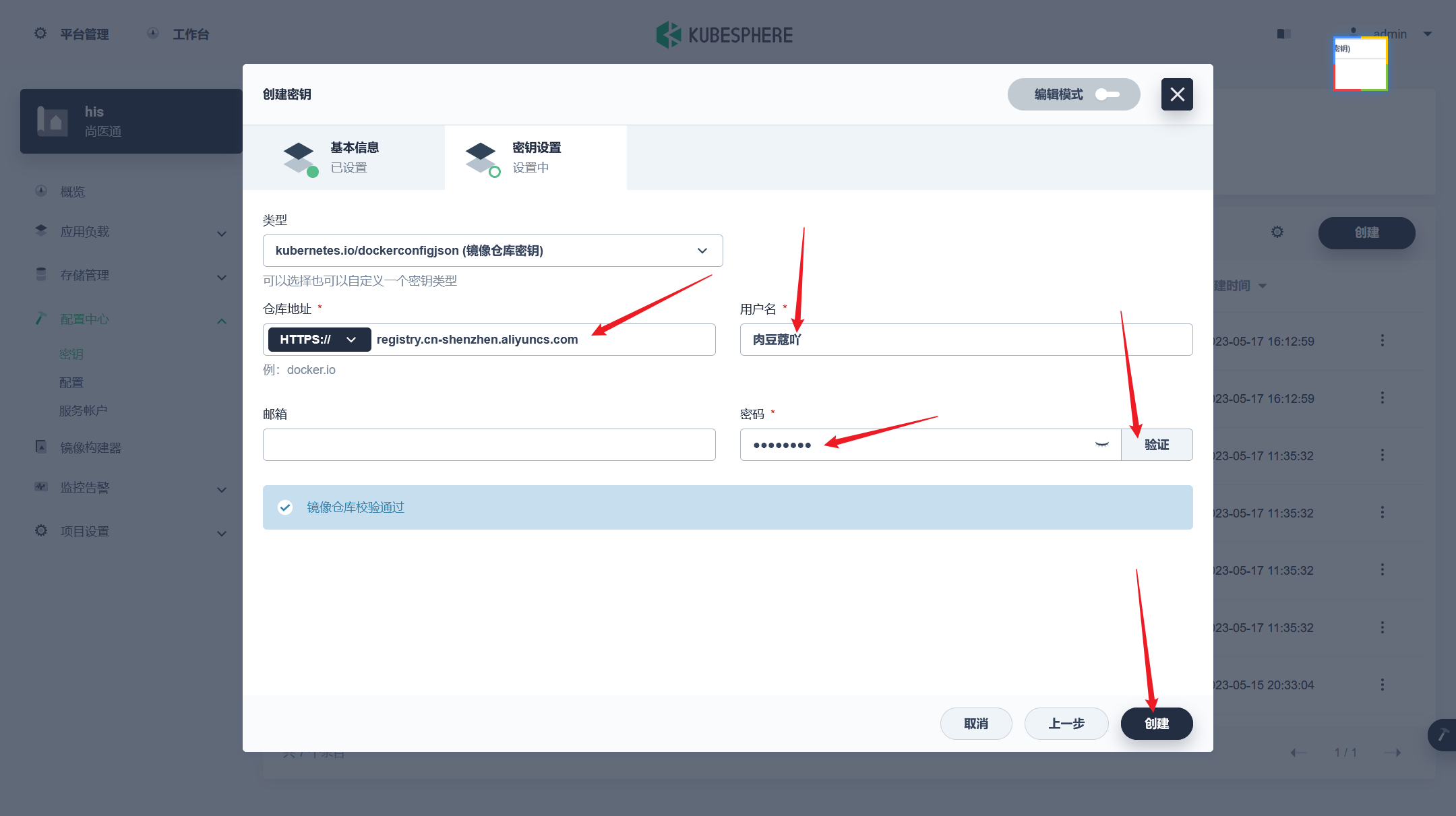
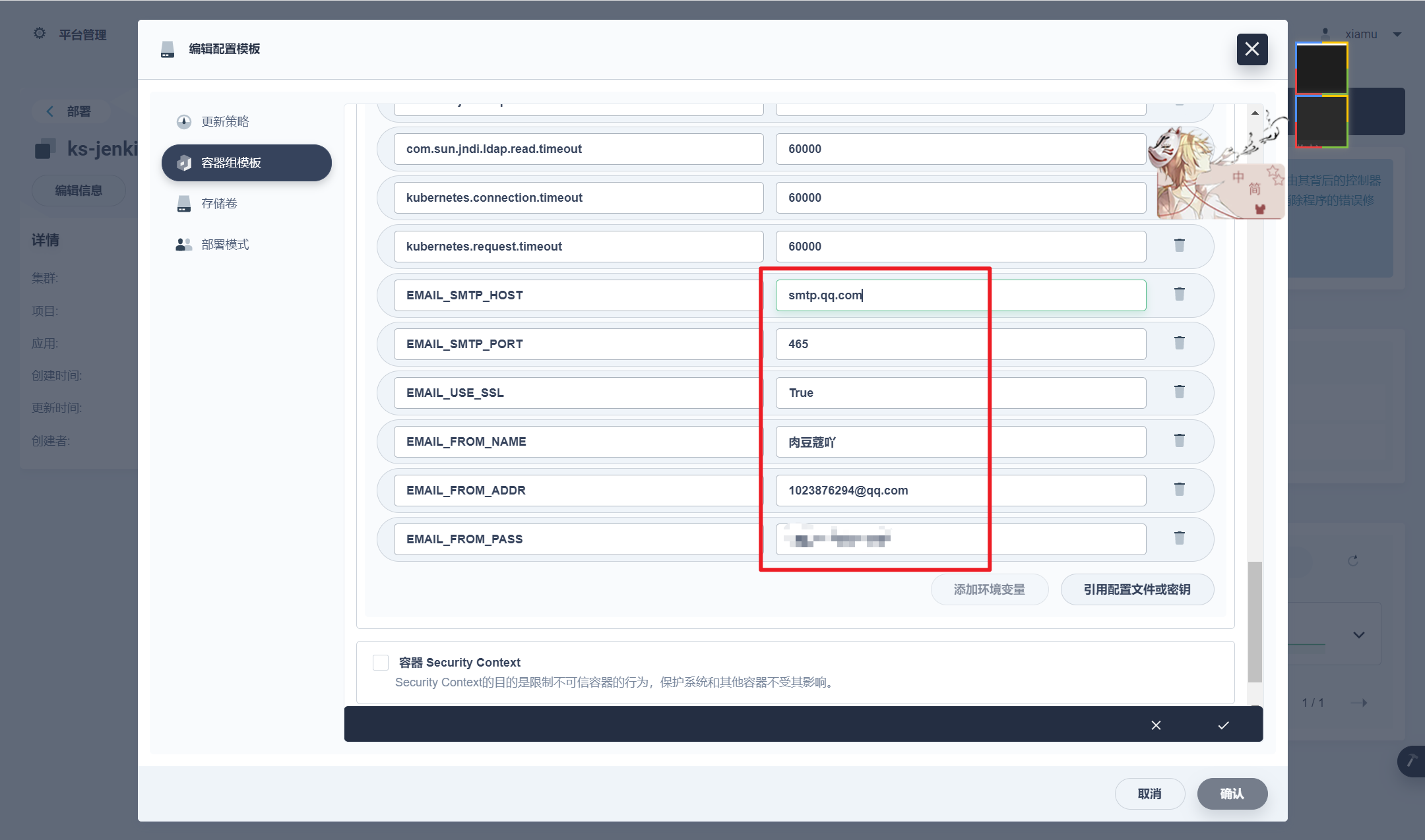
# 命名 docker tag c0b63feca088 registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-system:v1 docker tag b0f479101e96 registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-monitor:v1 docker tag fd3bcefdb9d0 registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-job:v1 docker tag df9dae1e1581 registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-gen:v1 docker tag 1a37fc67241f registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-gateway:v1 docker tag 85a54d4c38ea registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-file:v1 docker tag 0db642b44949 registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-auth:v1
# 查看镜像 [root@k8s-master ruoyi-system]# docker images | grep ruoyi ruoyi-auth v1 0db642b44949 49 seconds ago 617MB registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-auth v1 0db642b44949 49 seconds ago 617MB ruoyi-system v1 c0b63feca088 12 hours ago 632MB registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-system v1 c0b63feca088 12 hours ago 632MB ruoyi-monitor v1 b0f479101e96 12 hours ago 592MB registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-monitor v1 b0f479101e96 12 hours ago 592MB registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-job v1 fd3bcefdb9d0 12 hours ago 629MB ruoyi-job v1 fd3bcefdb9d0 12 hours ago 629MB ruoyi-gen v1 df9dae1e1581 12 hours ago 628MB registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-gen v1 df9dae1e1581 12 hours ago 628MB ruoyi-gateway v1 1a37fc67241f 12 hours ago 625MB registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-gateway v1 1a37fc67241f 12 hours ago 625MB ruoyi-file v1 85a54d4c38ea 12 hours ago 622MB registry.cn-shenzhen.aliyuncs.com/roudoukou-ruoyi/ruoyi-file v1 85a54d4c38ea 12 hours ago 622MB
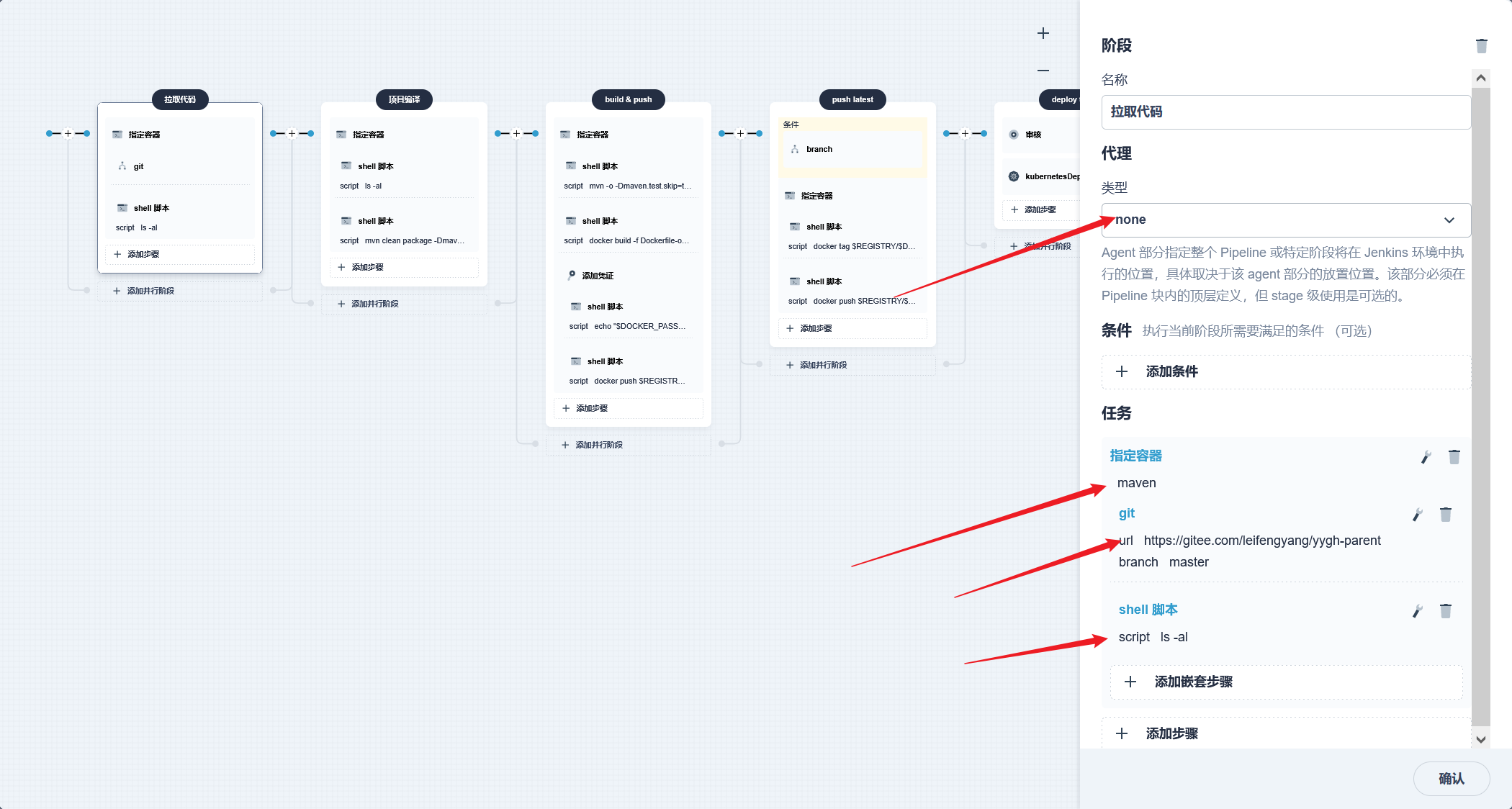
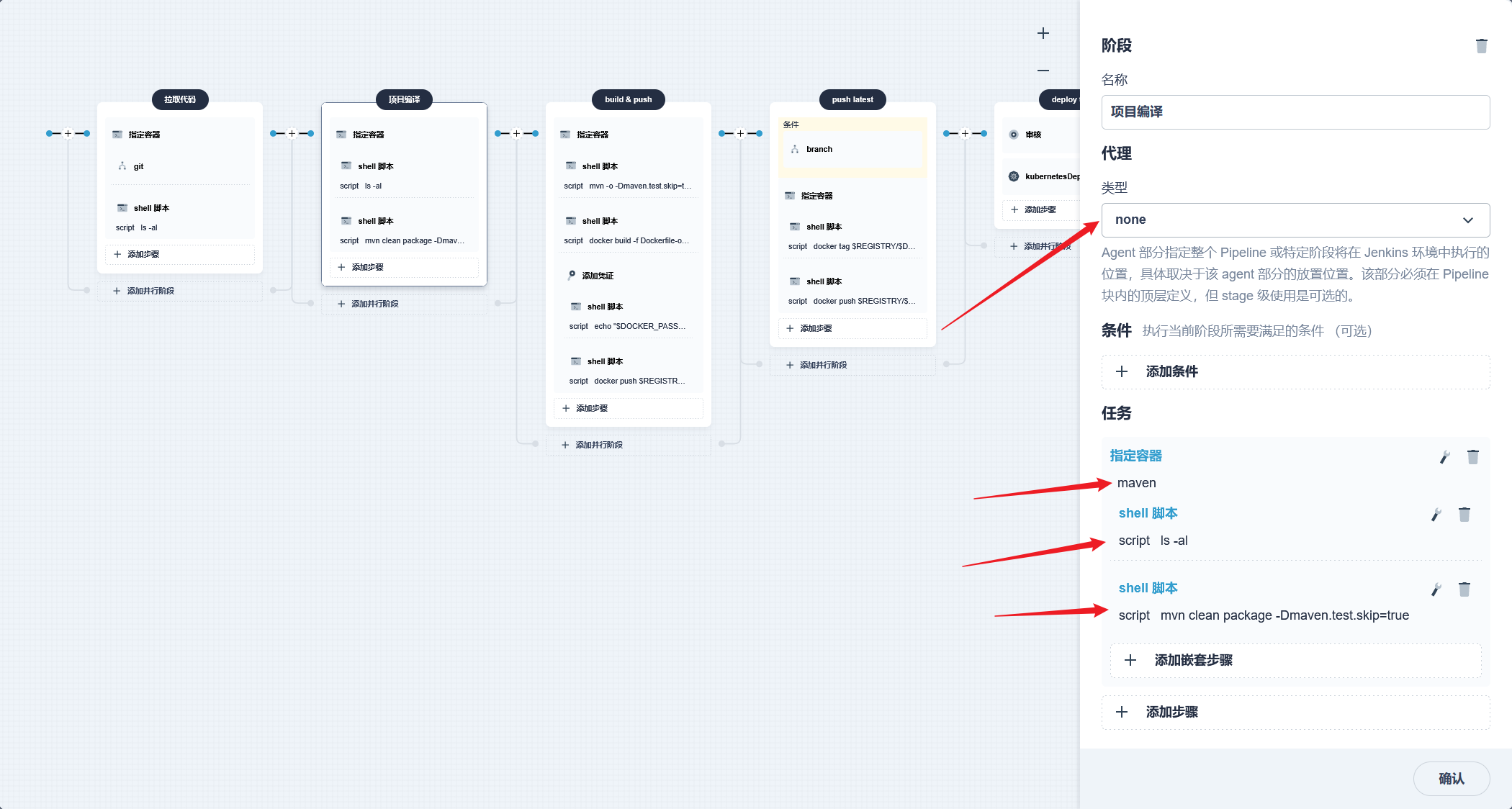
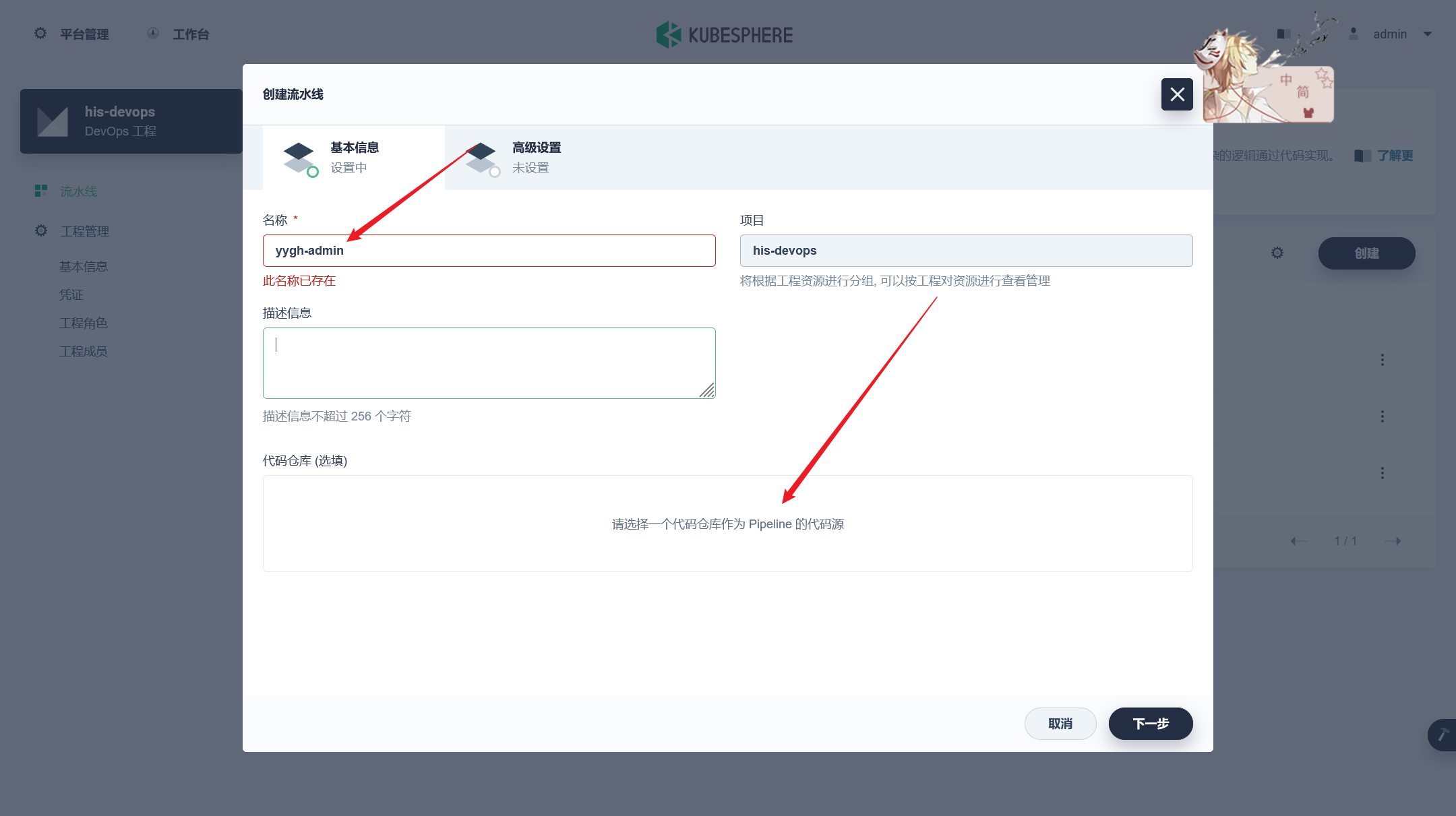
stage('项目编译') { agent none steps { container('nodejs') { sh 'npm i node-sass --sass_binary_site=https://npm.taobao.org/mirrors/node-sass/' sh 'npm install --registry=https://registry.npm.taobao.org' sh 'npm run build' sh 'ls' }
} }
stage('构建镜像') { agent none steps { container('nodejs') { sh 'ls' sh 'docker build -t yygh-admin:latest -f Dockerfile .' }
} }
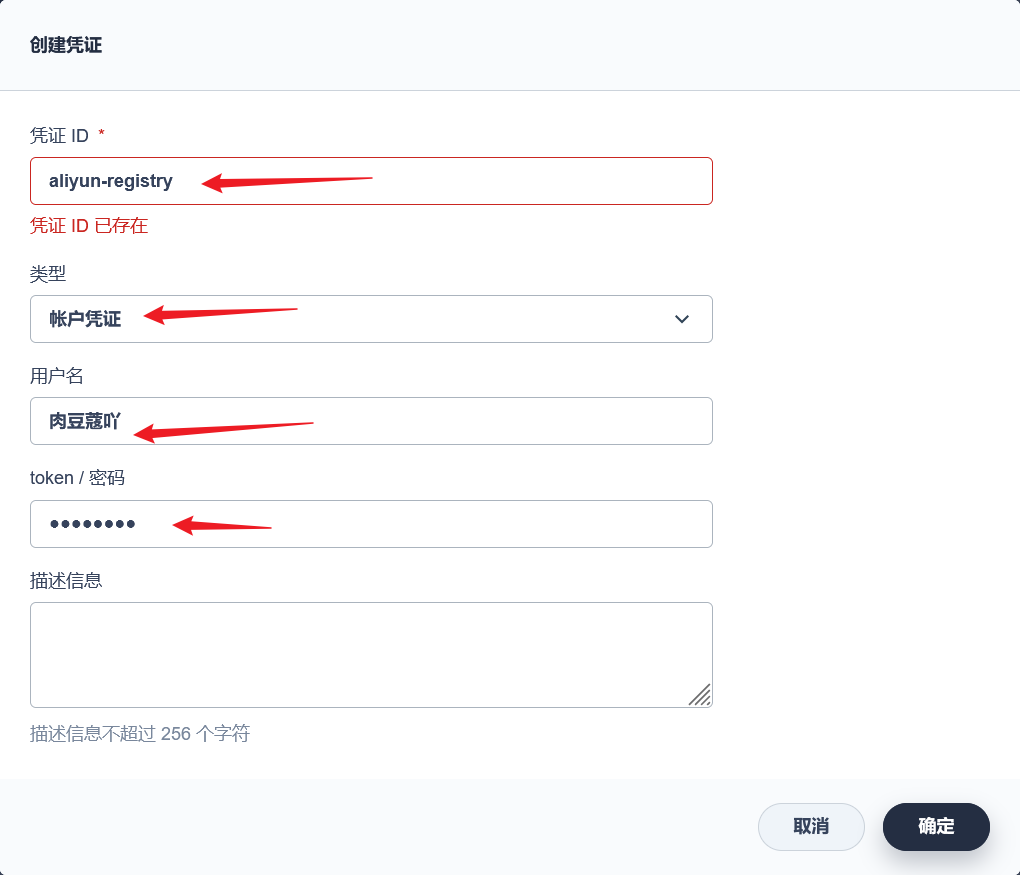
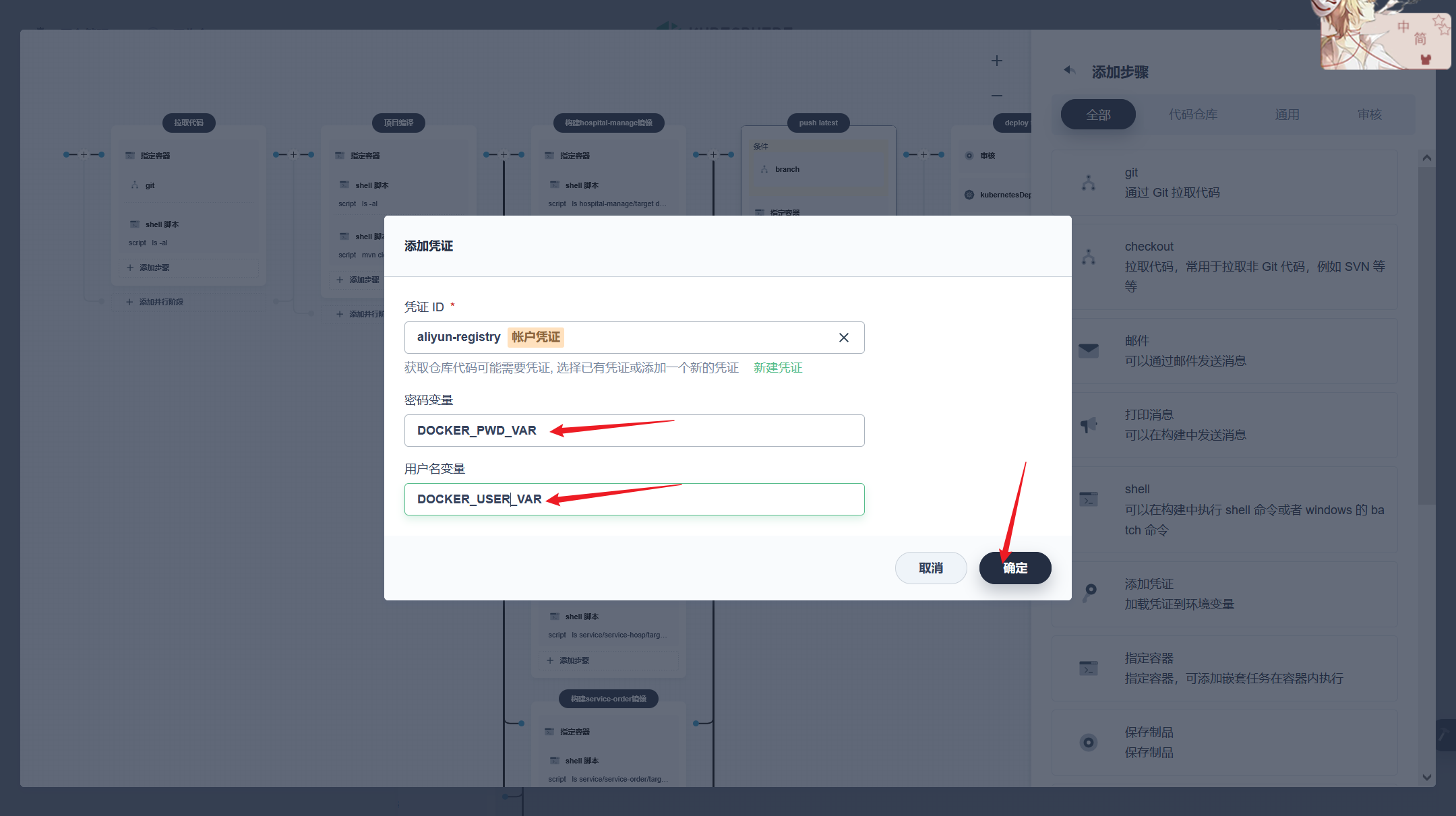
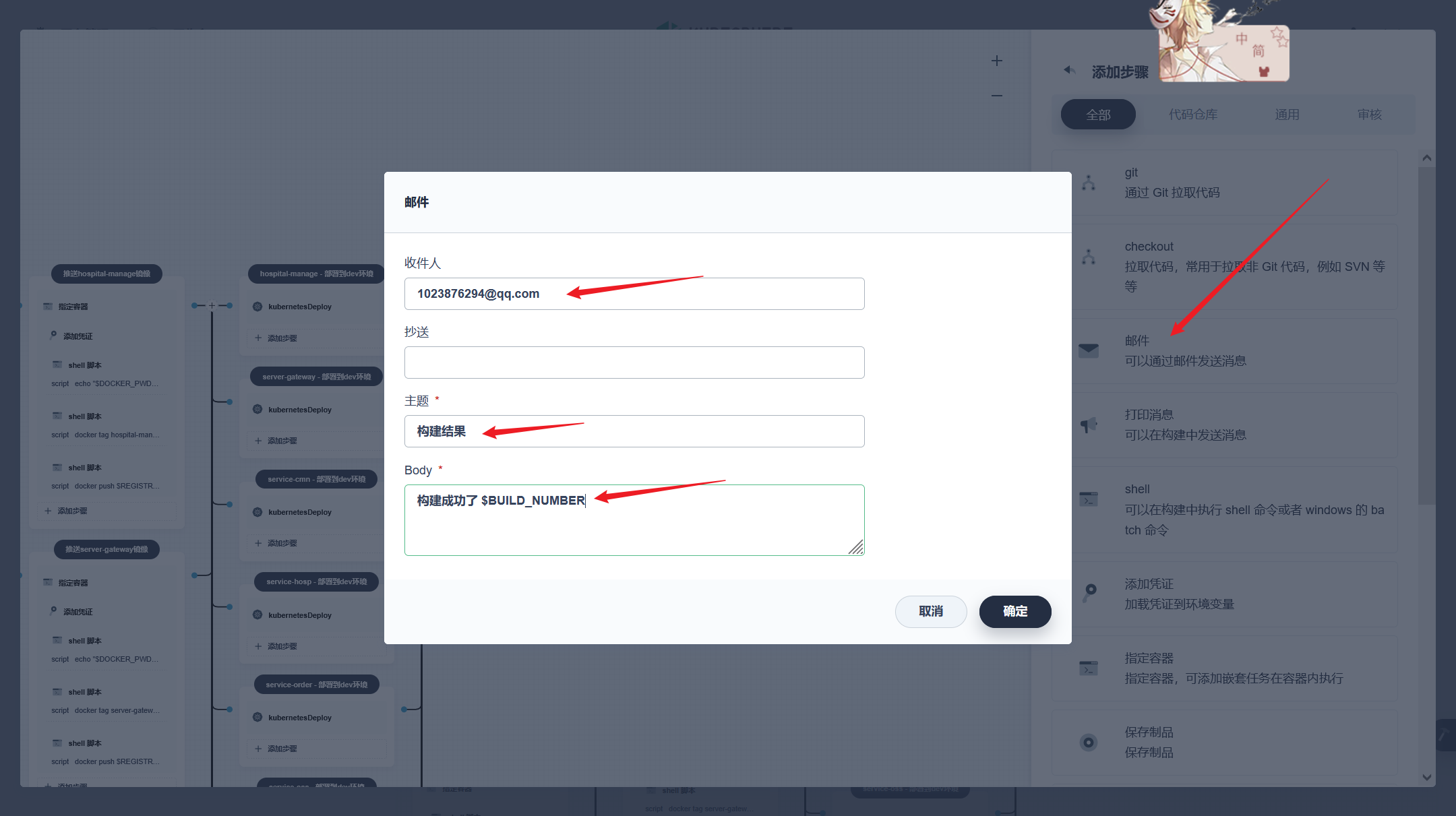
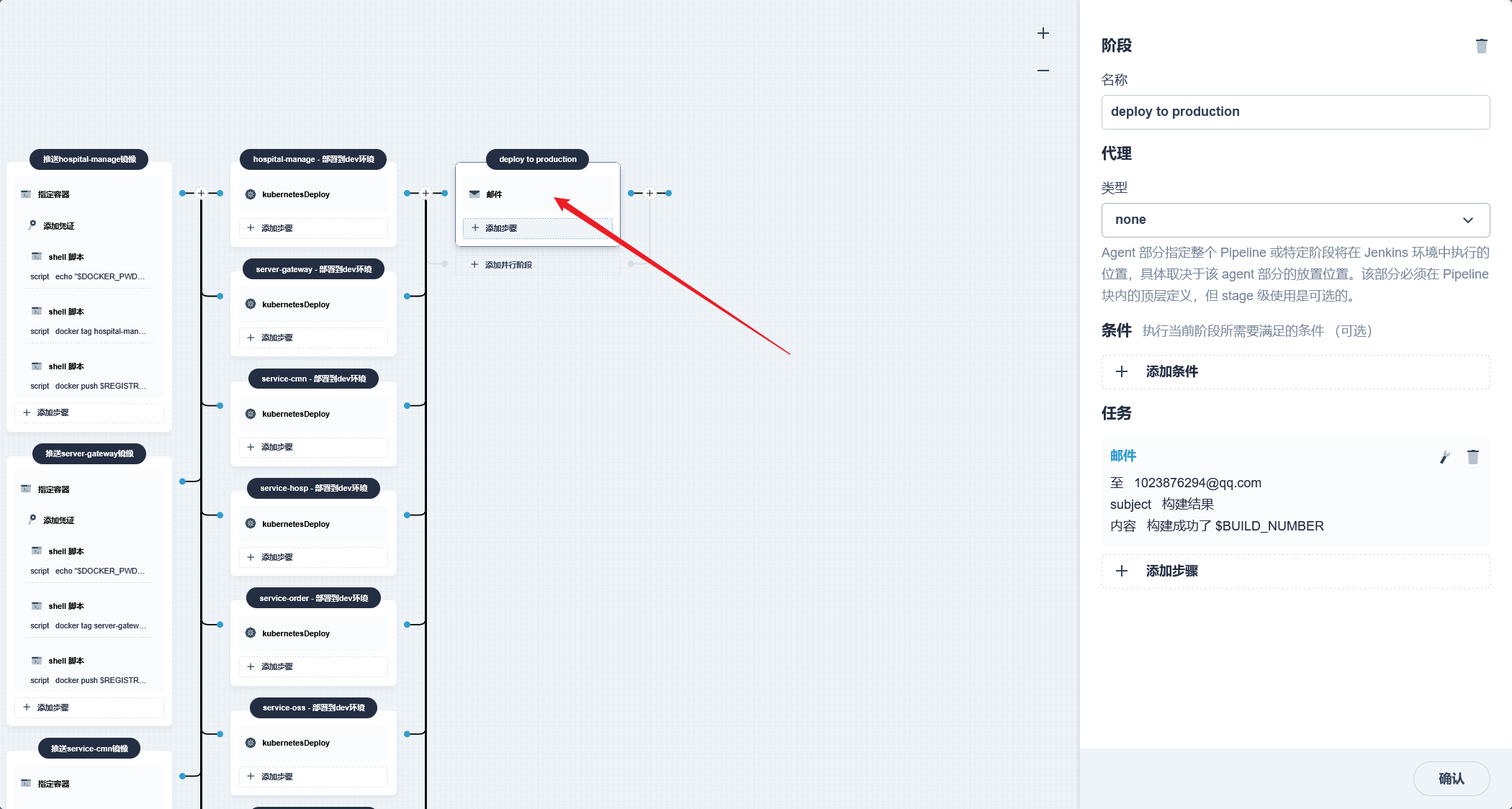
stage('推送镜像') { agent none steps { container('nodejs') { withCredentials([usernamePassword(credentialsId : 'aliyun-registry' ,usernameVariable : 'DOCKER_USER_VAR' ,passwordVariable : 'DOCKER_PWD_VAR' ,)]) { sh 'echo "$DOCKER_PWD_VAR" | docker login $REGISTRY -u "$DOCKER_USER_VAR" --password-stdin' sh 'docker tag yygh-admin:latest $REGISTRY/$DOCKERHUB_NAMESPACE/yygh-admin:SNAPSHOT-$BUILD_NUMBER' sh 'docker push $REGISTRY/$DOCKERHUB_NAMESPACE/yygh-admin:SNAPSHOT-$BUILD_NUMBER' }
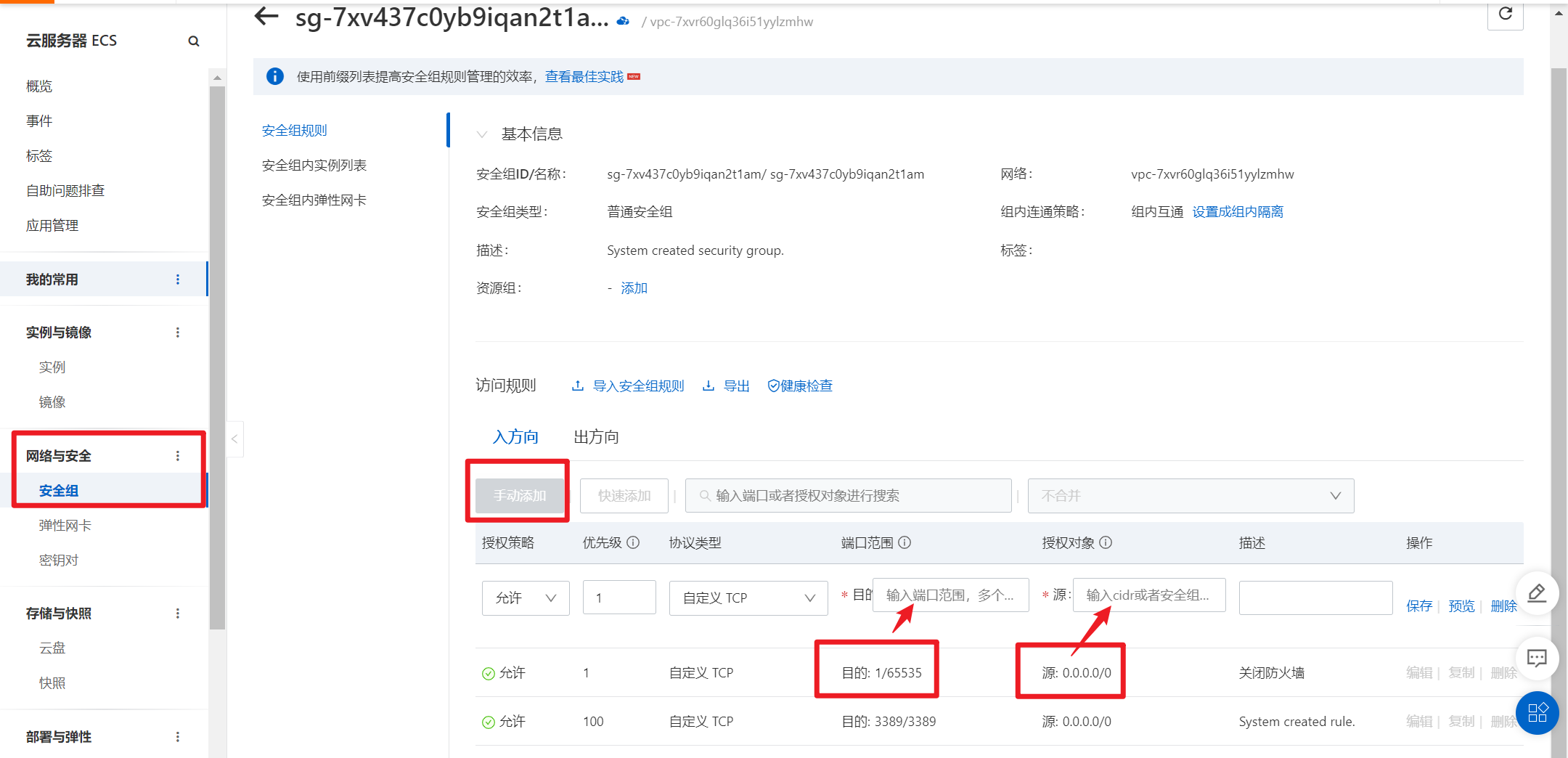
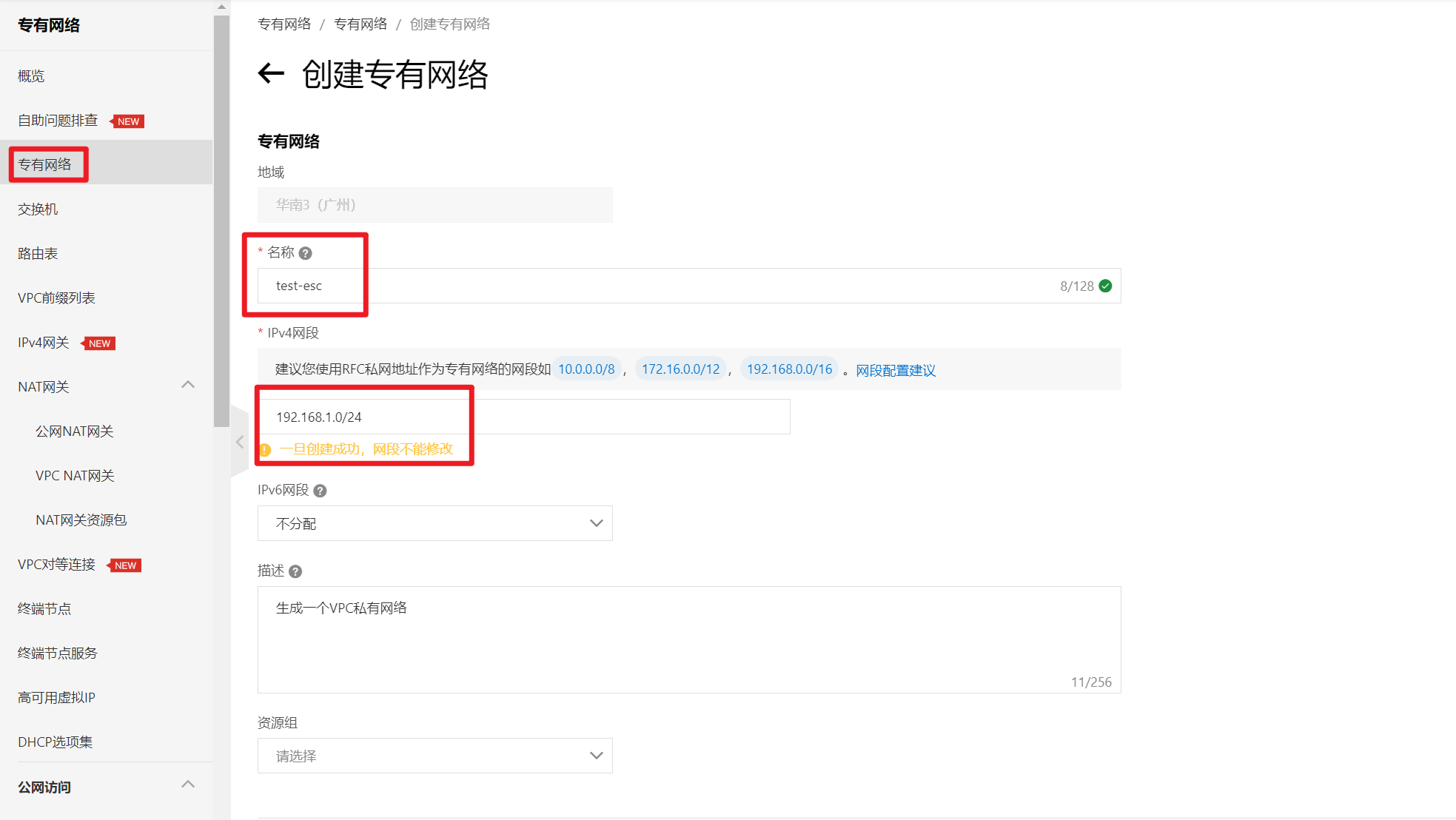
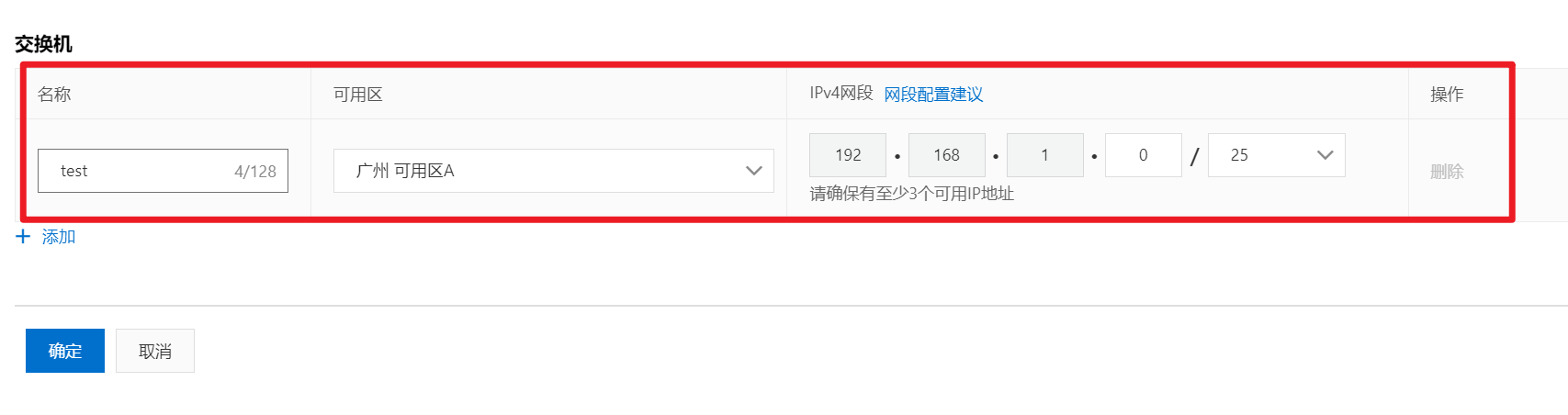

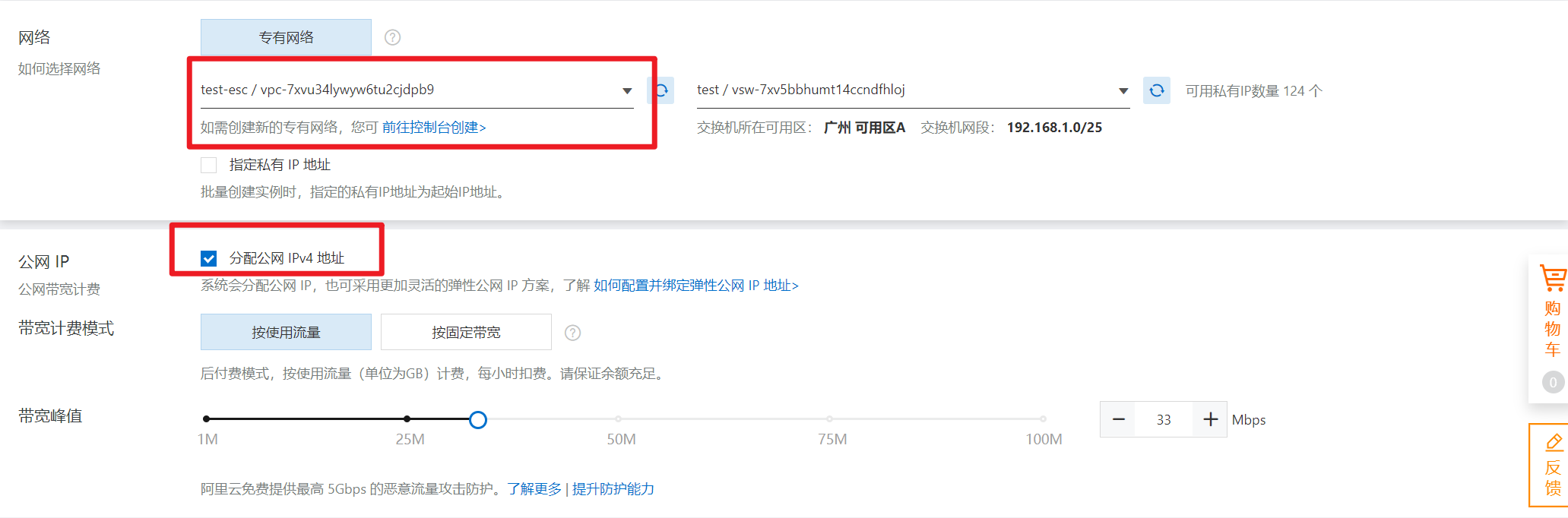

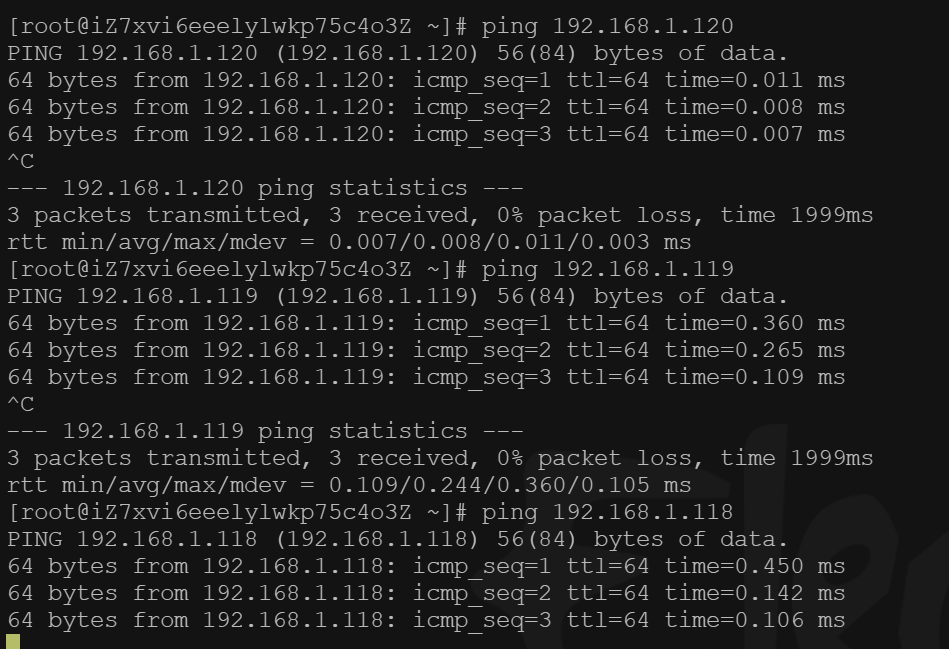

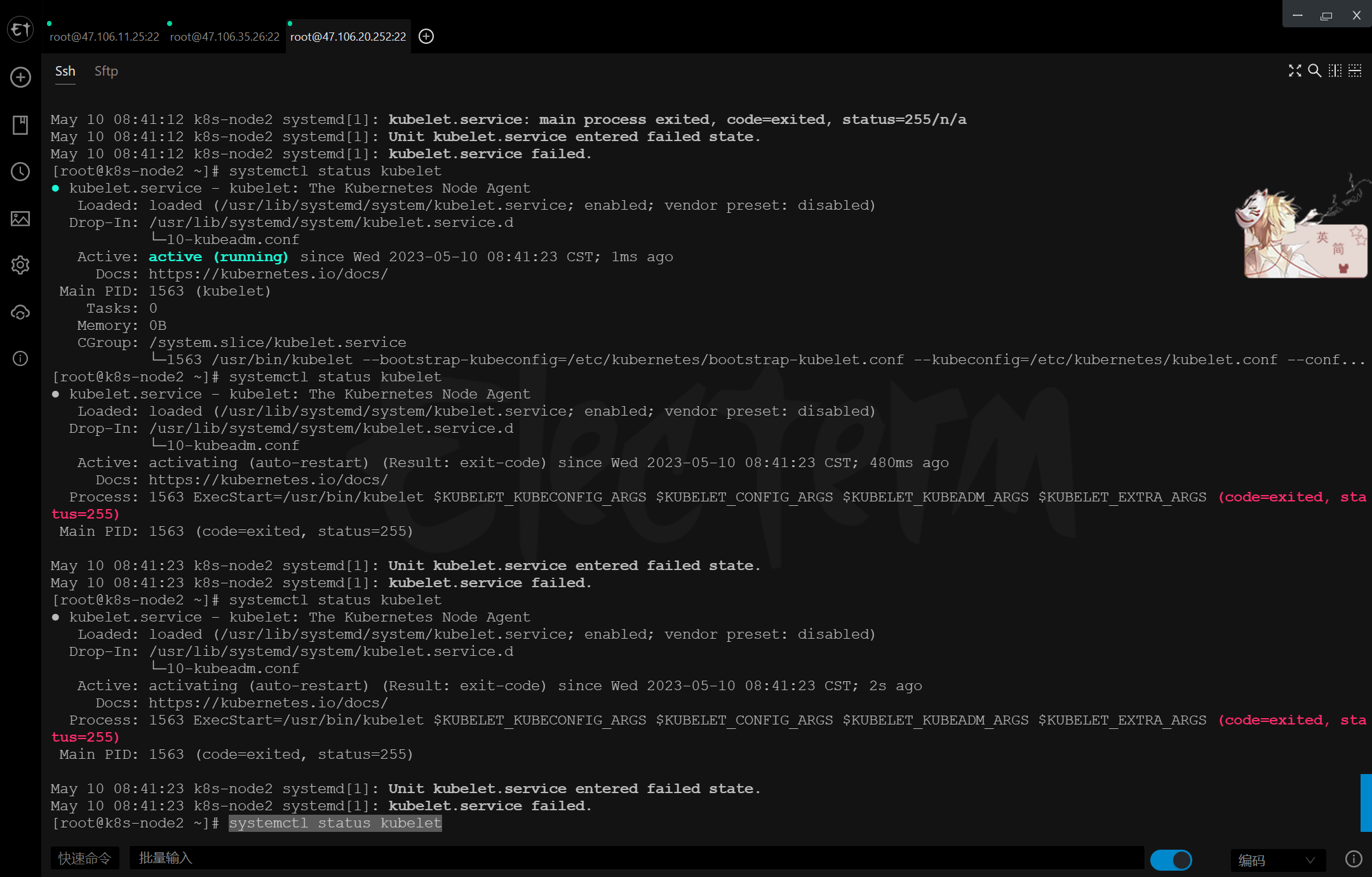
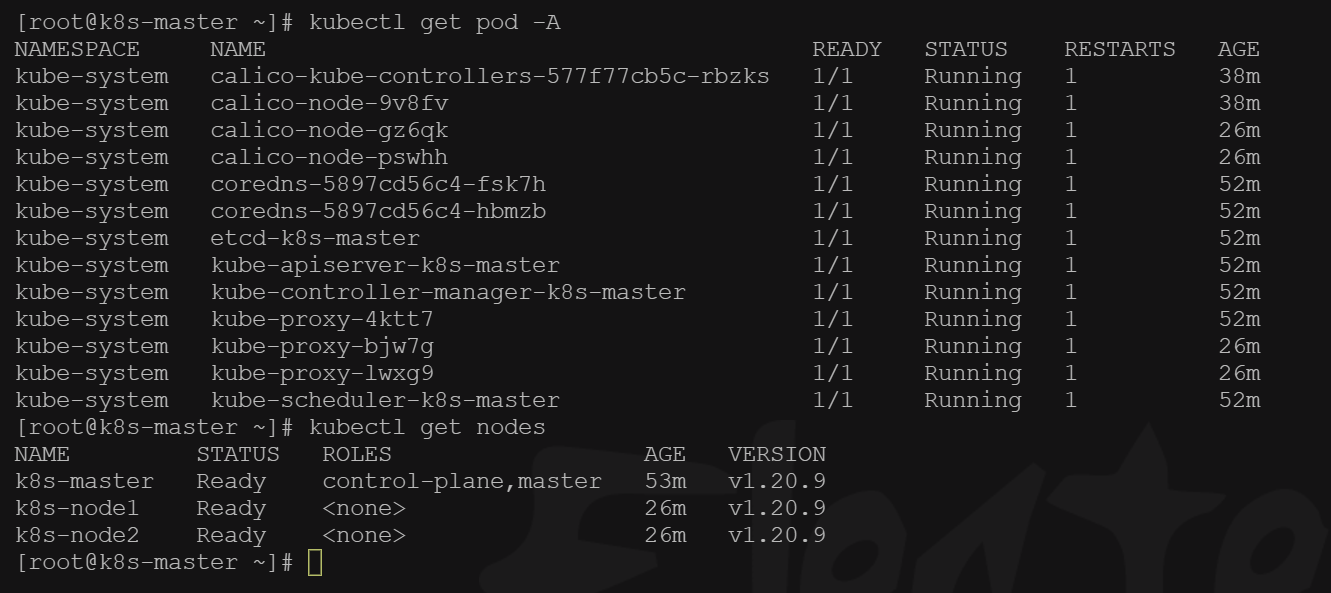


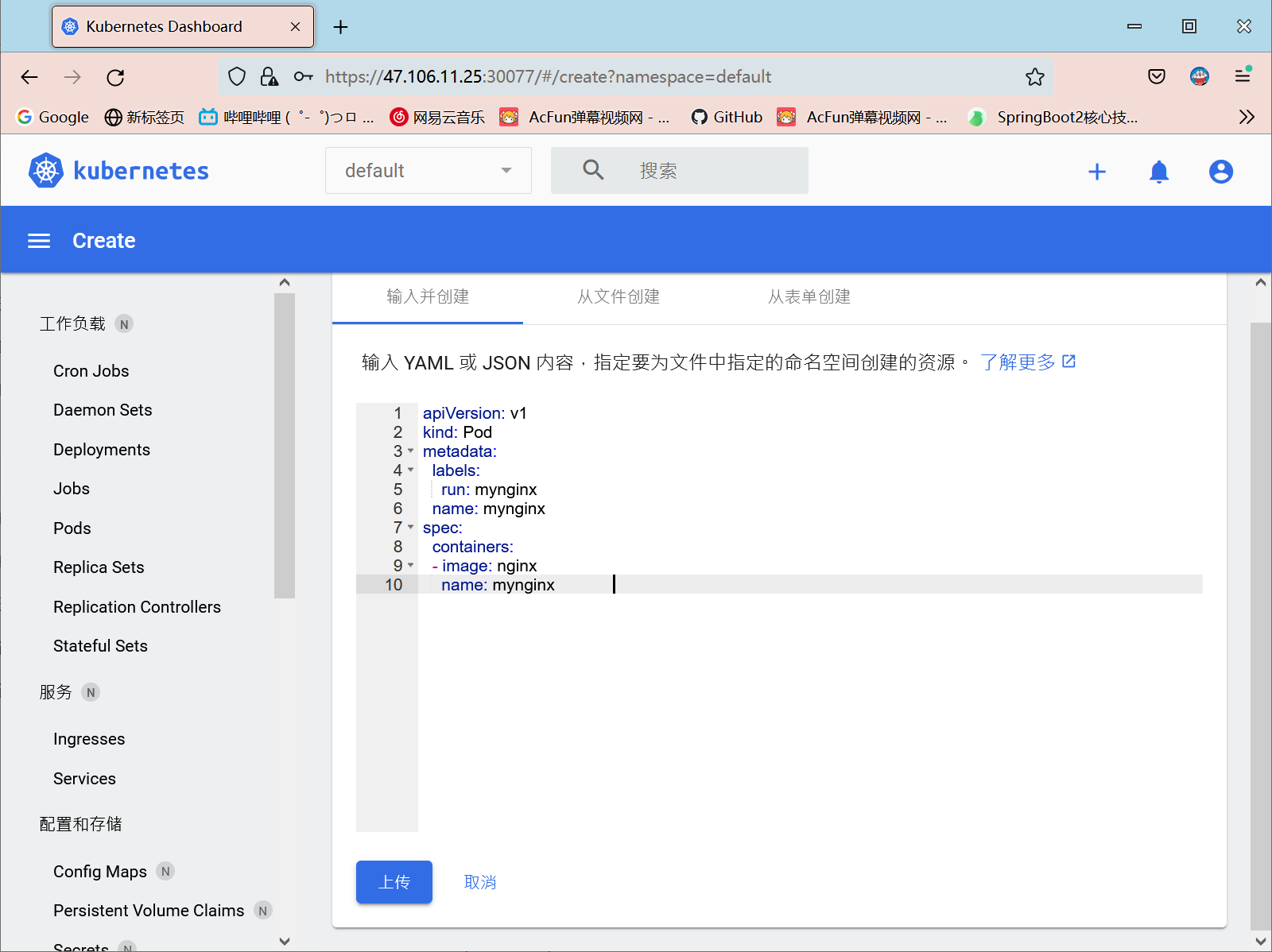
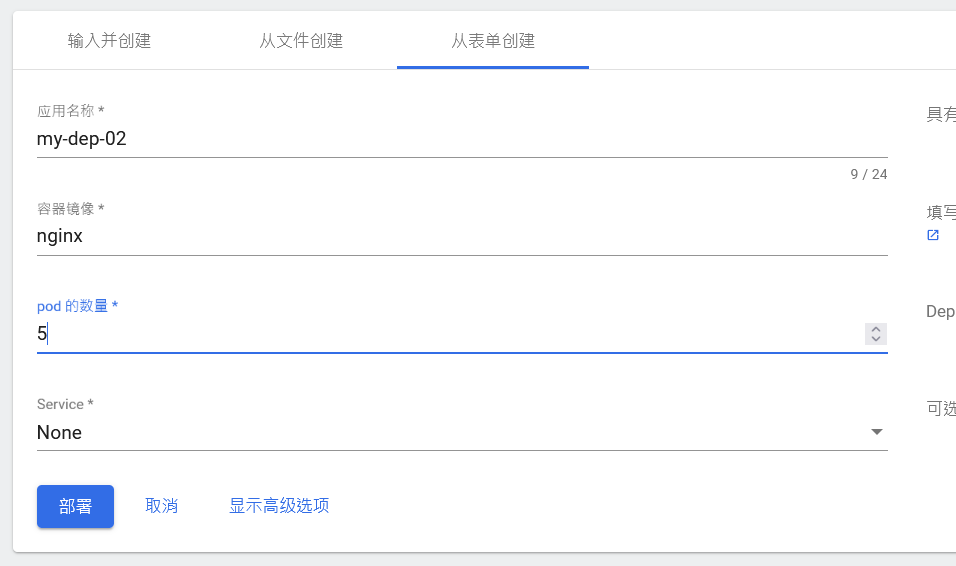
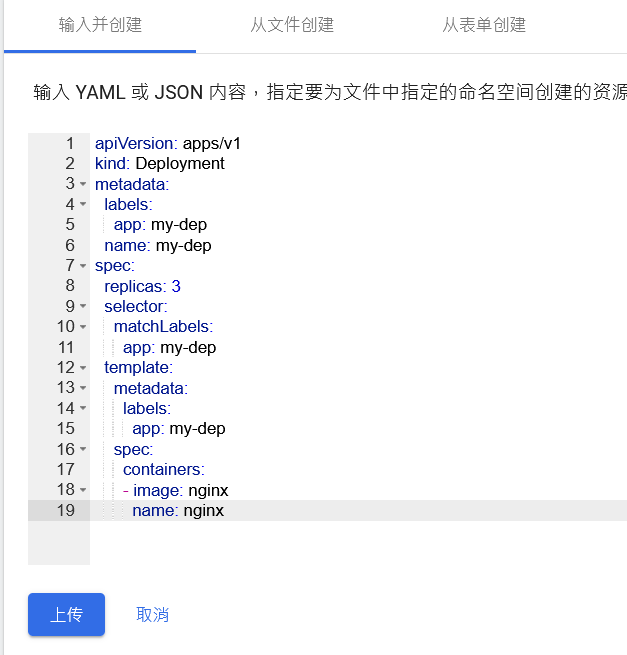
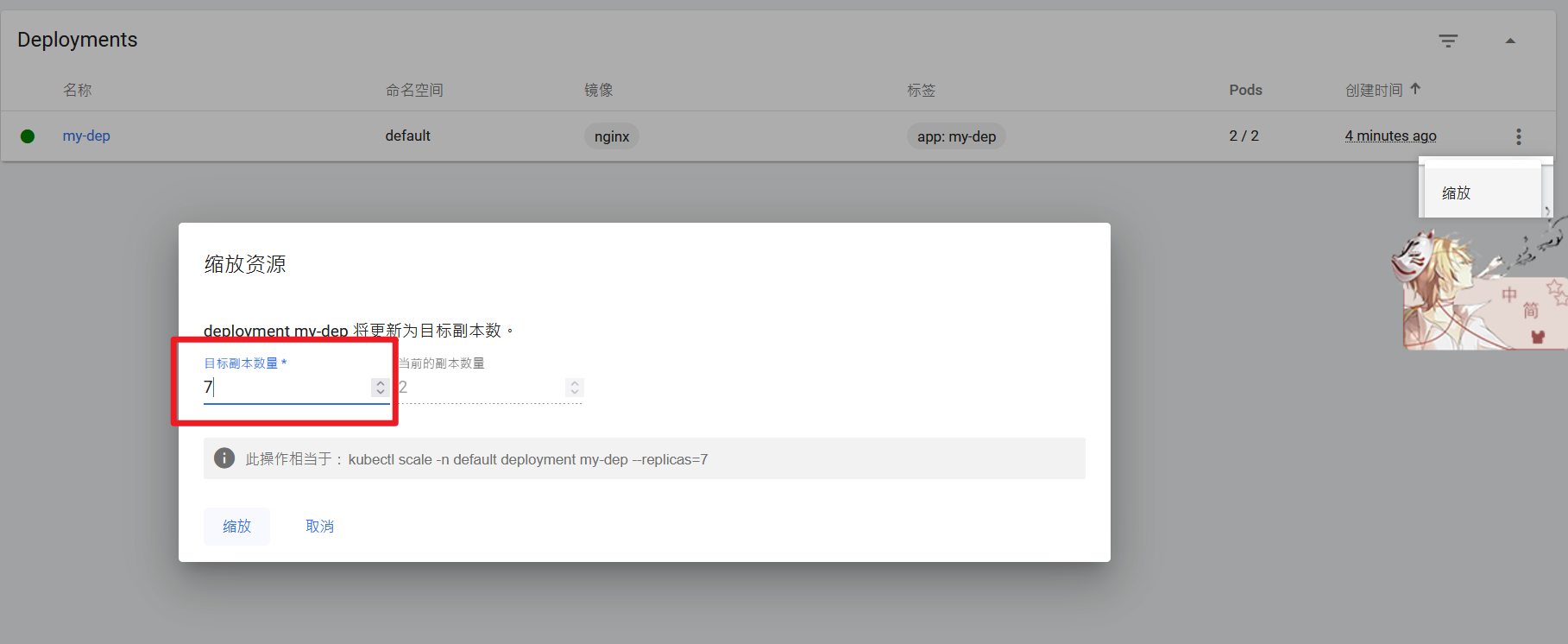
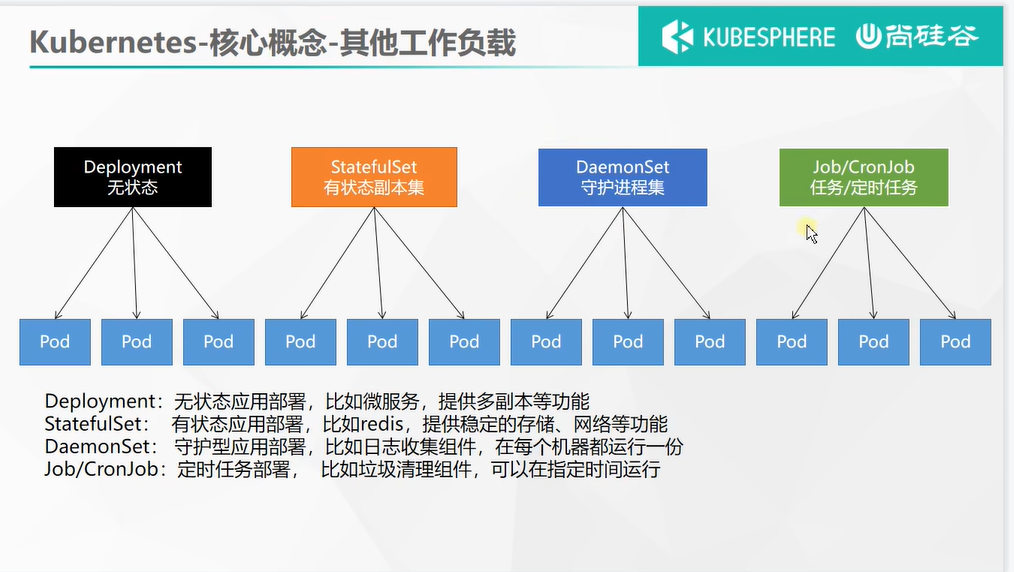
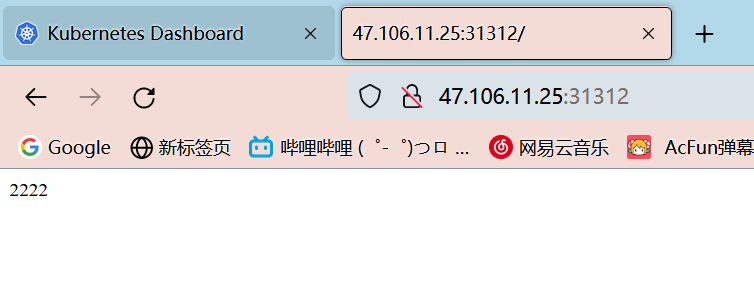
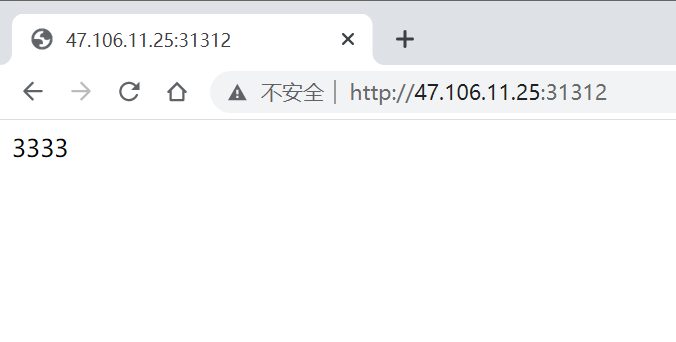
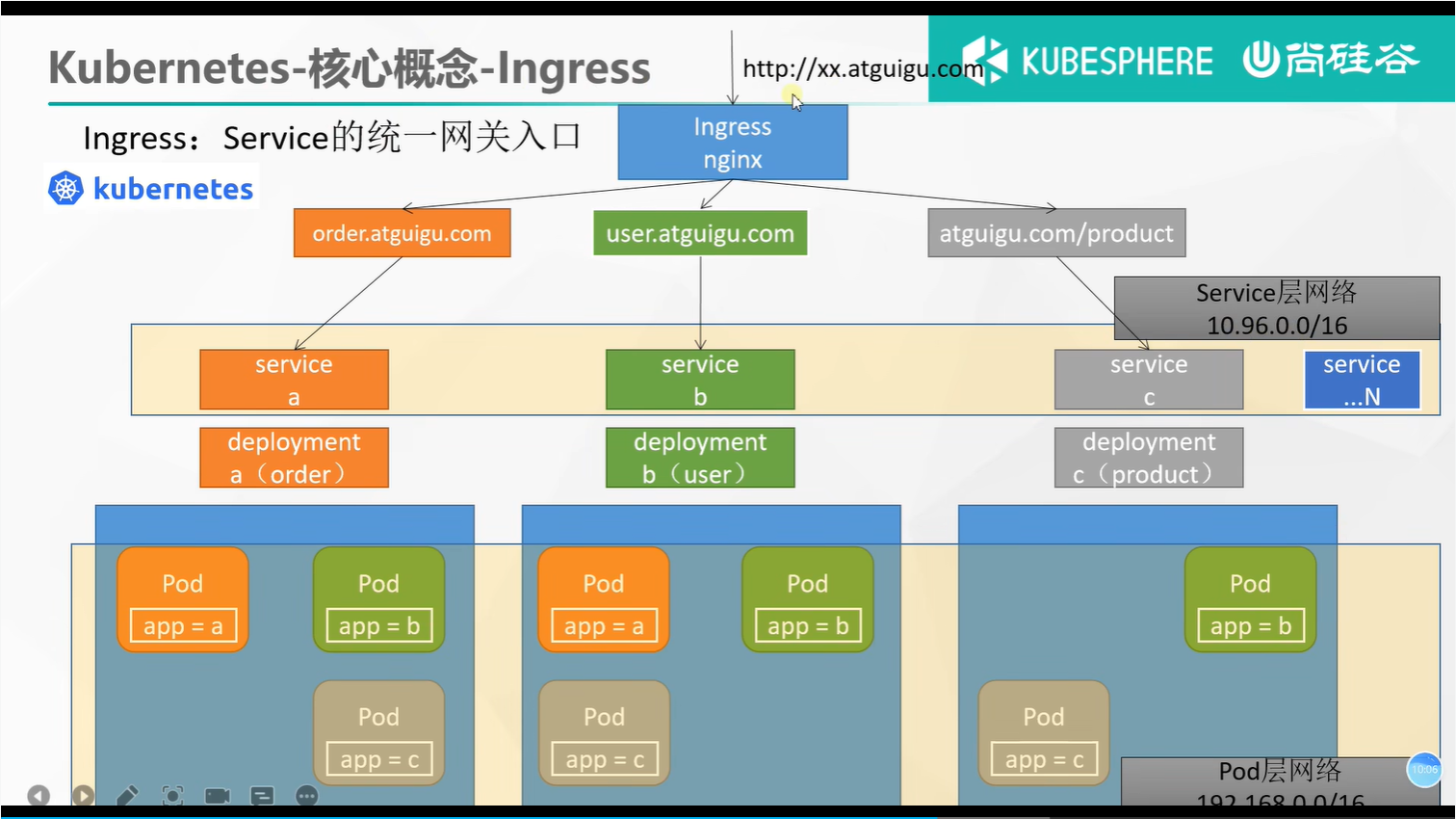
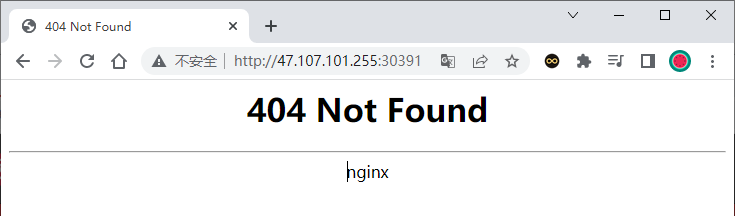
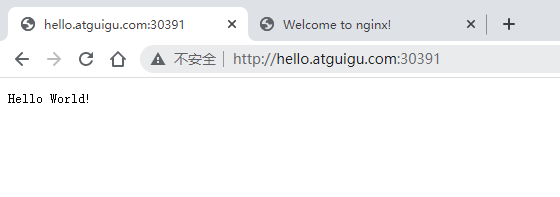
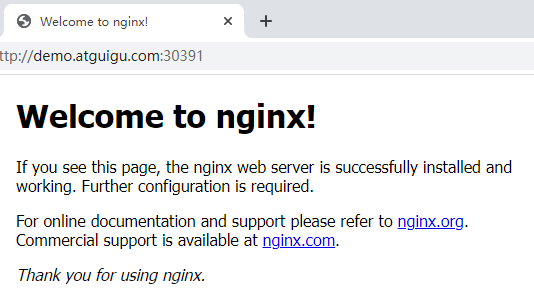
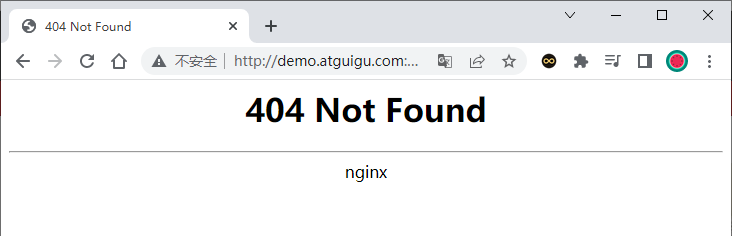
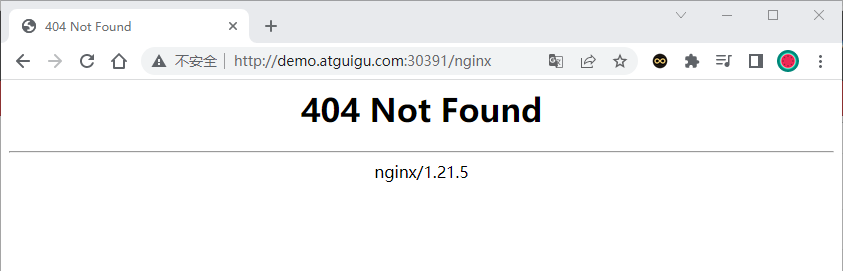
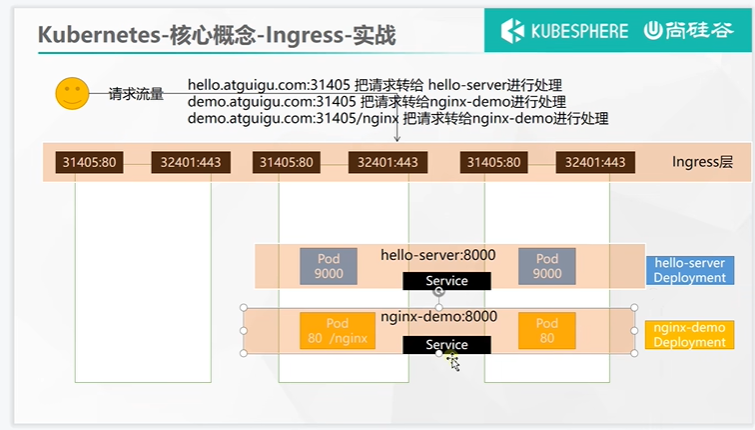
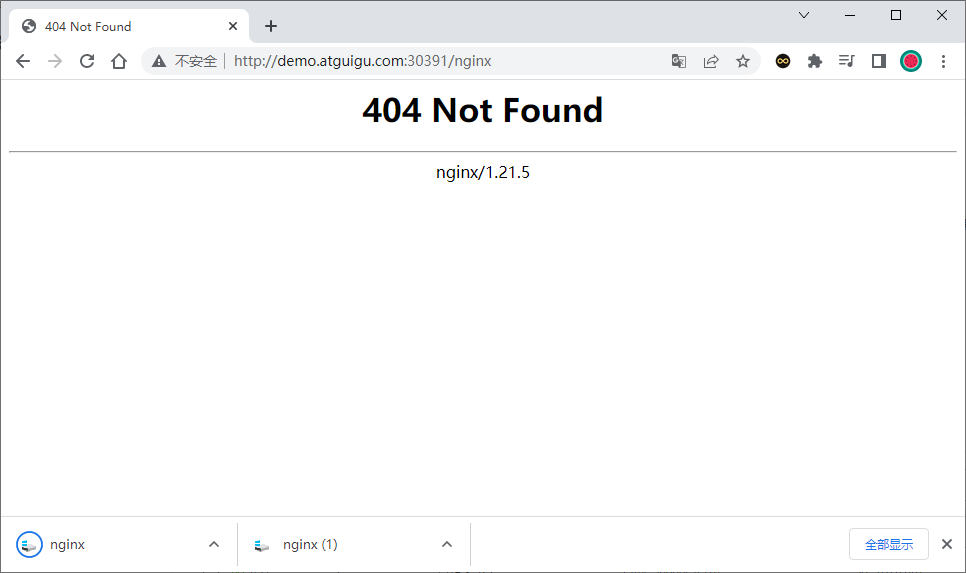
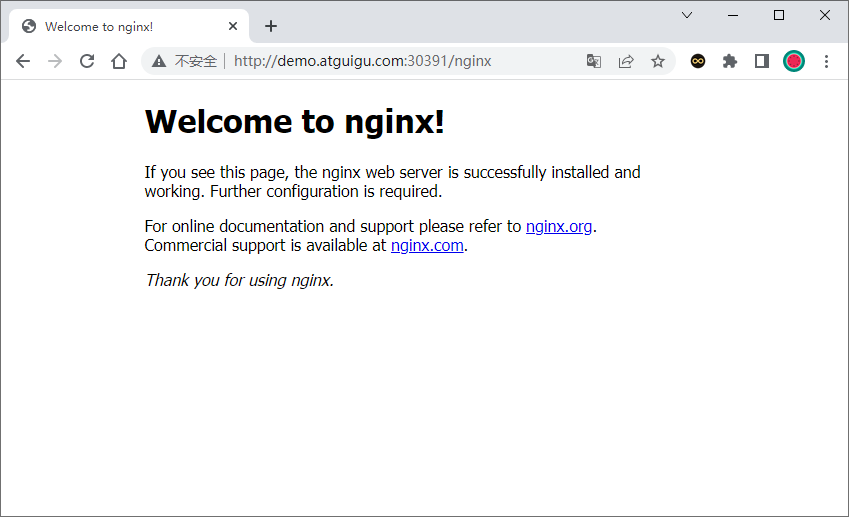

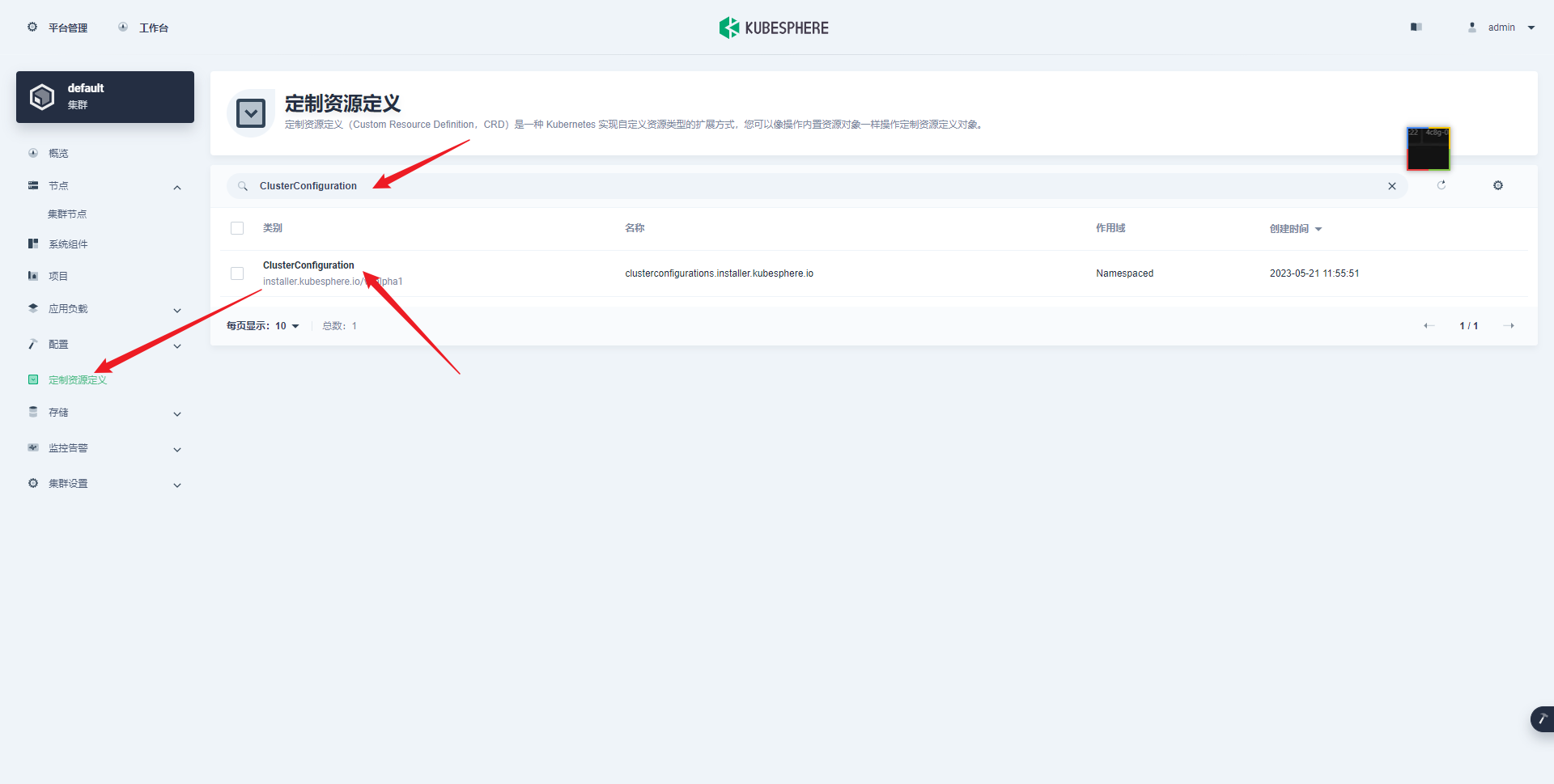
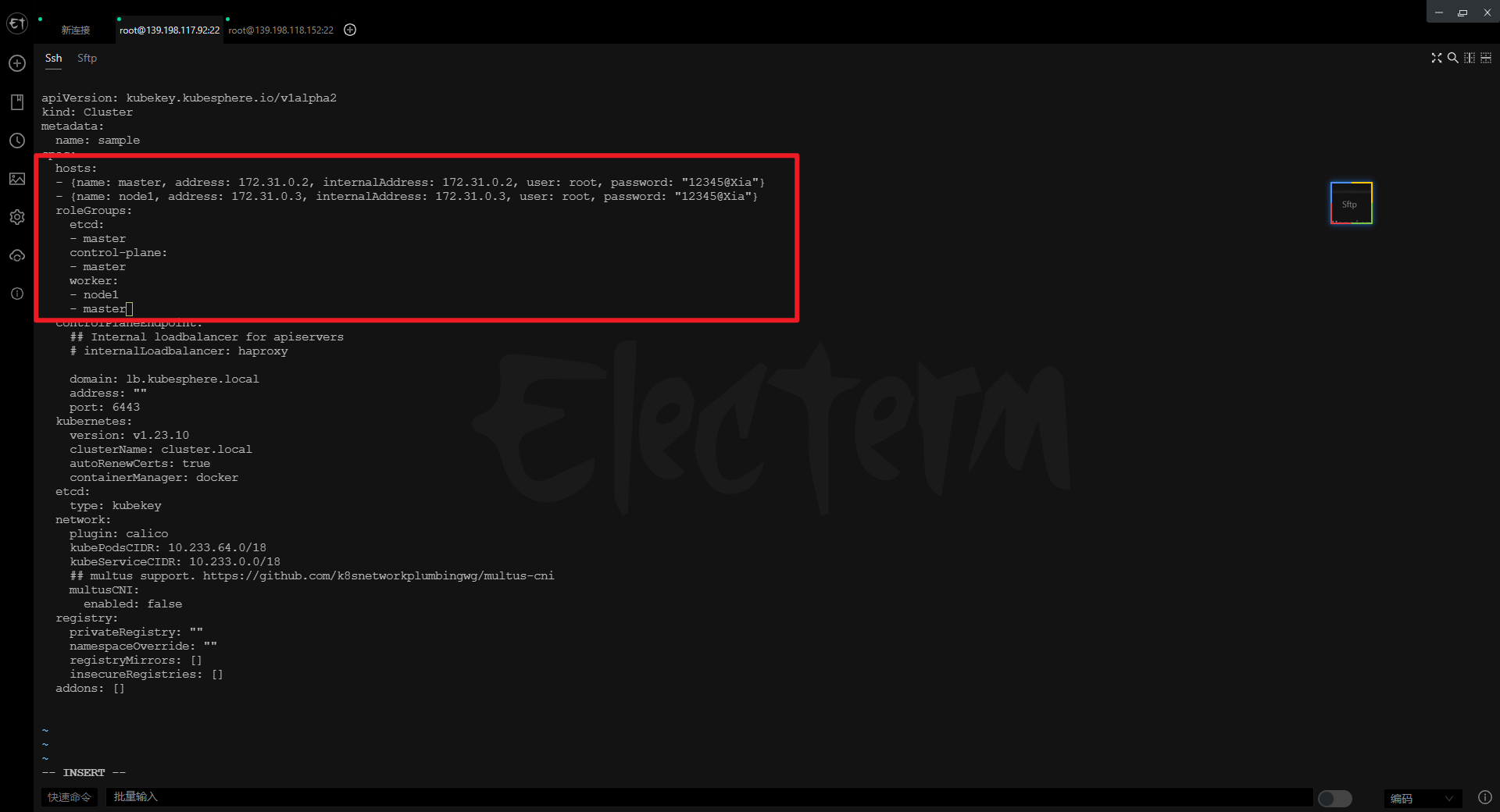
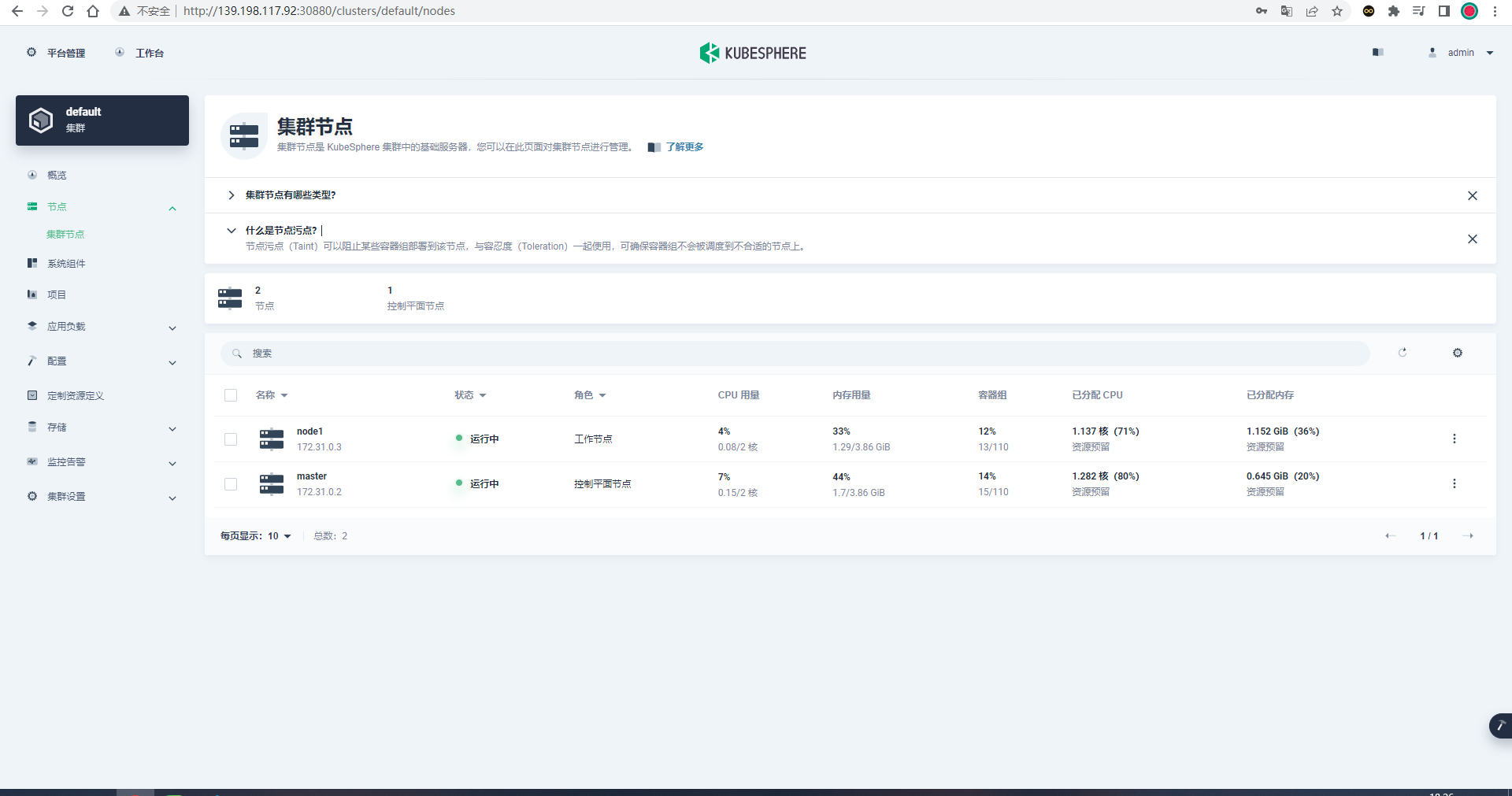
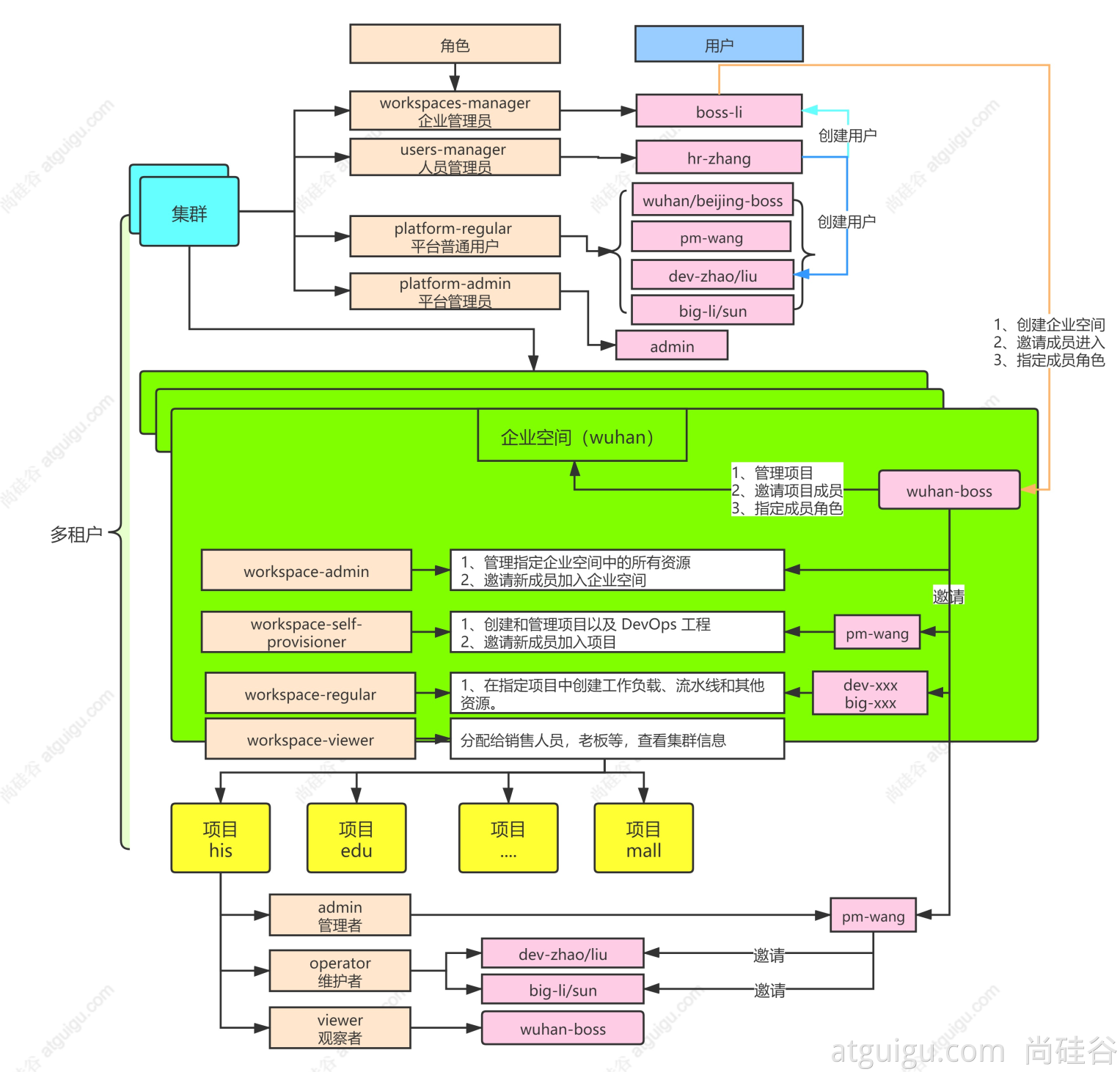
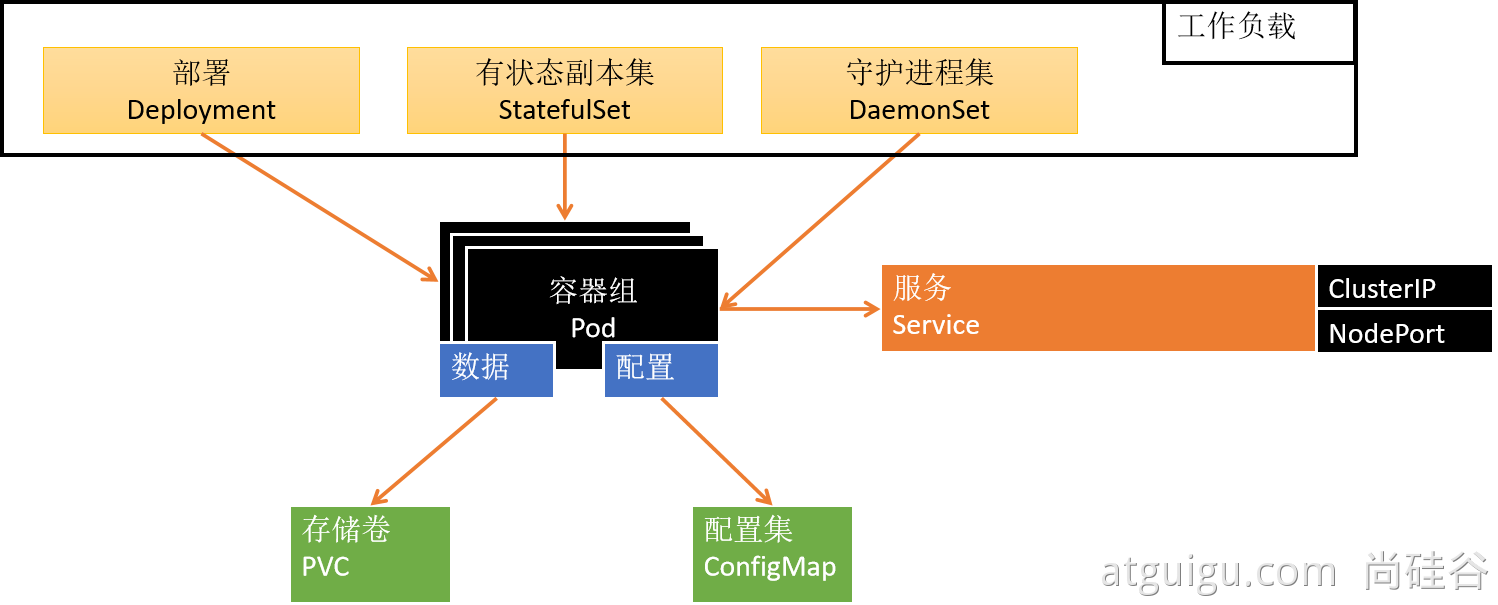
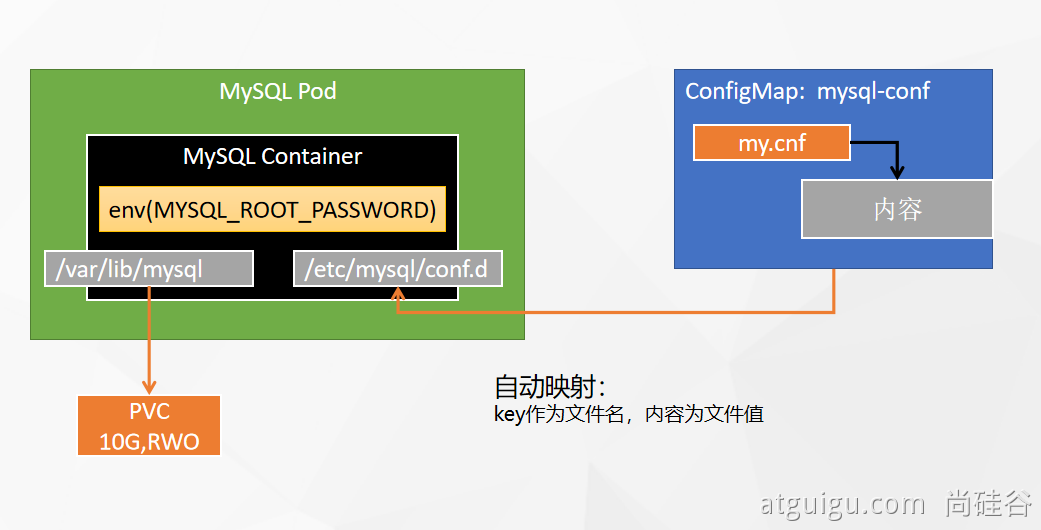

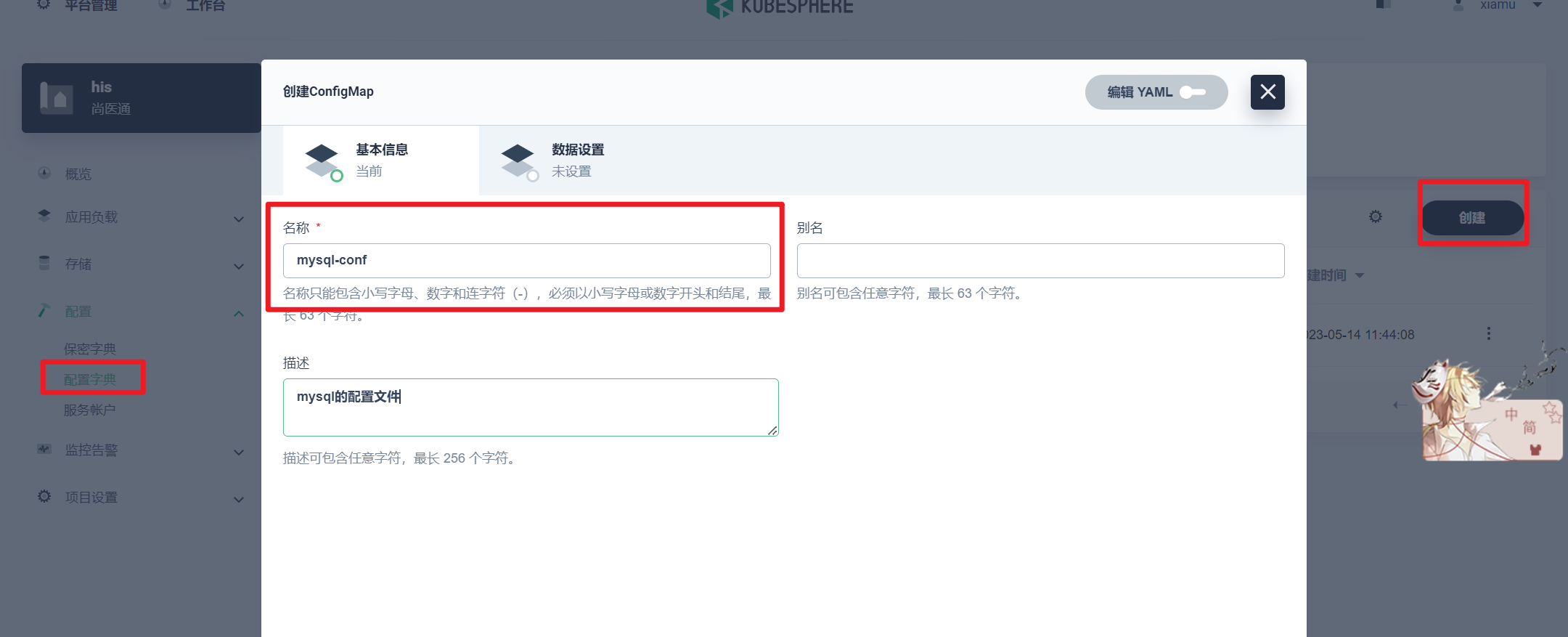
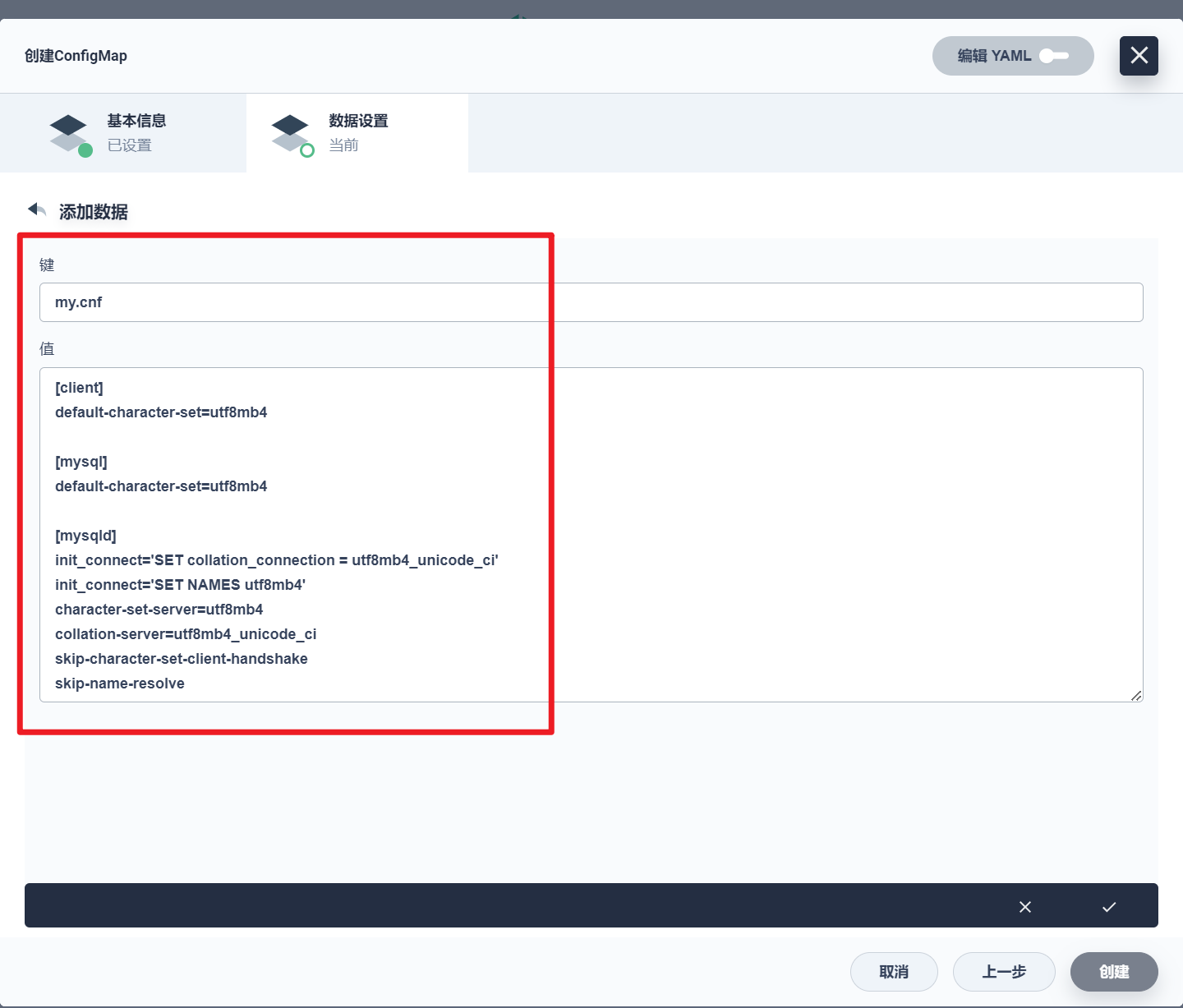
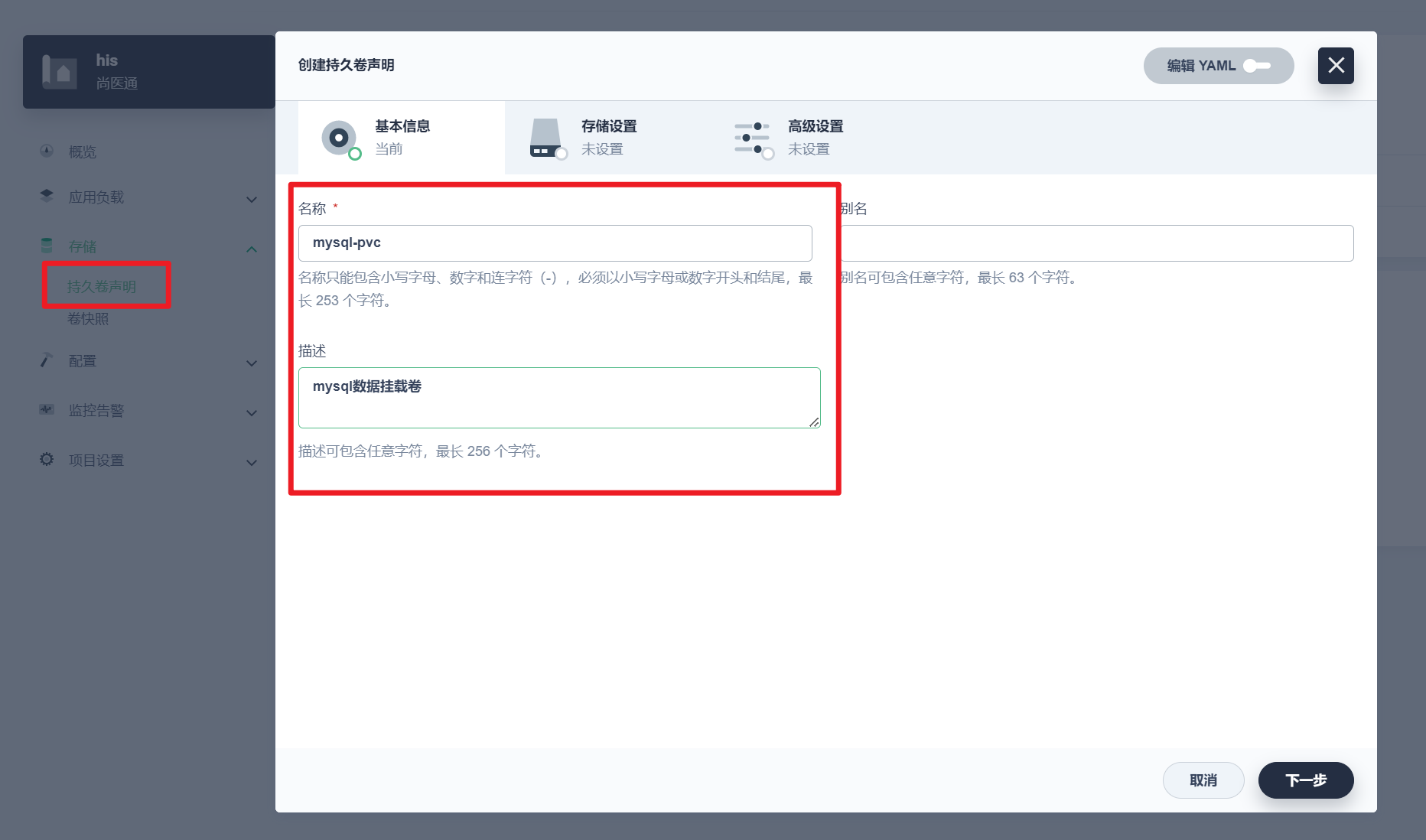
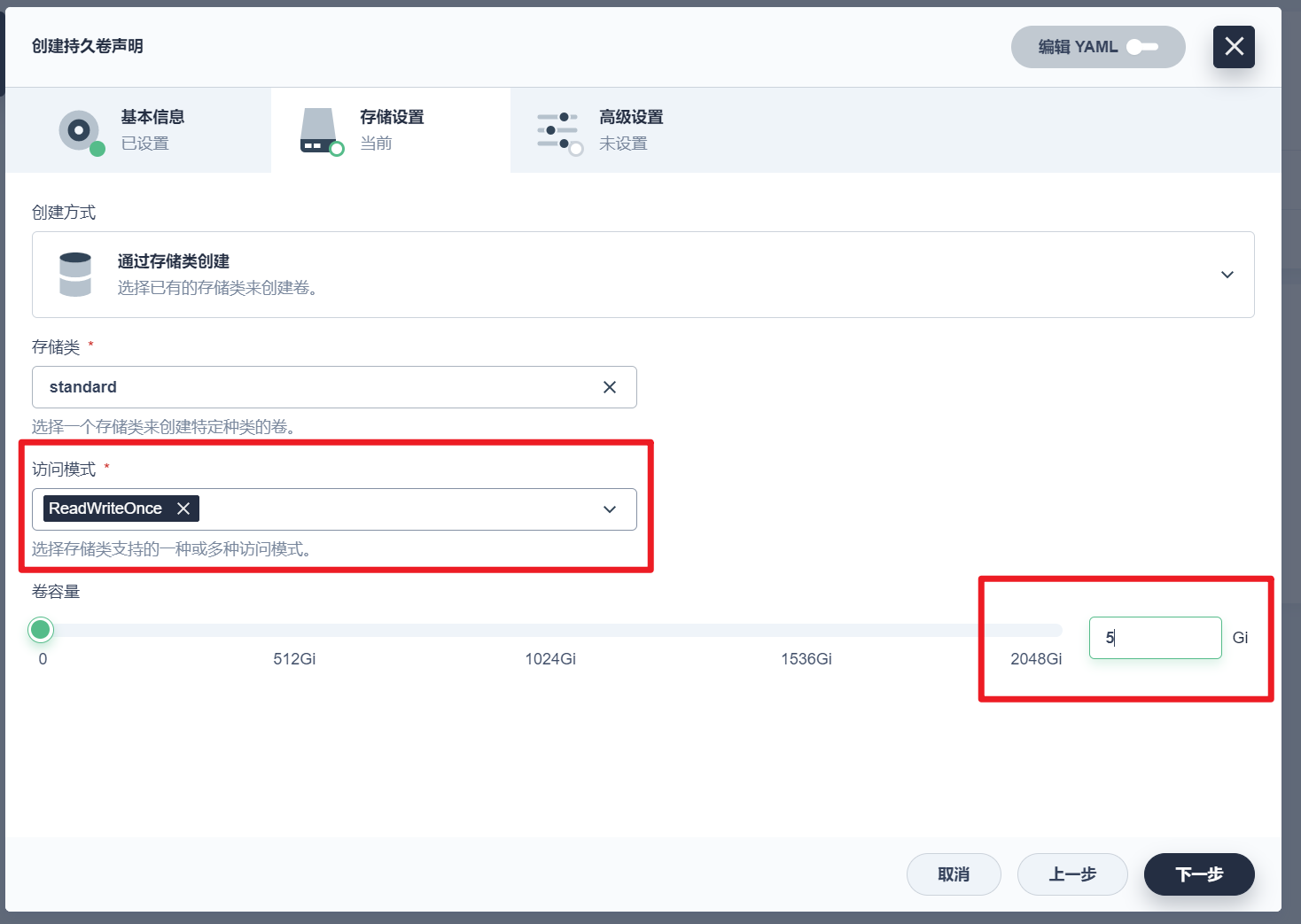
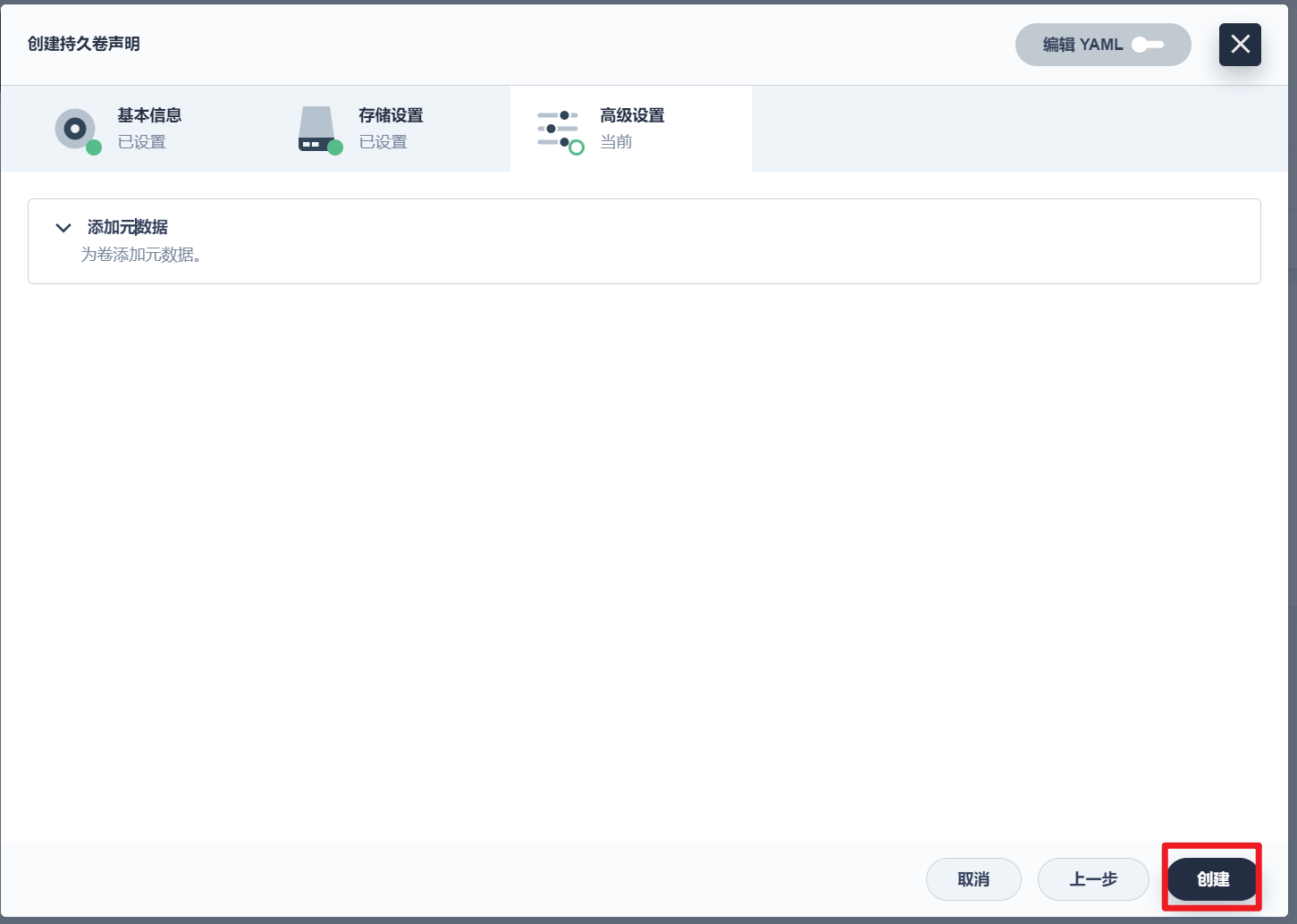
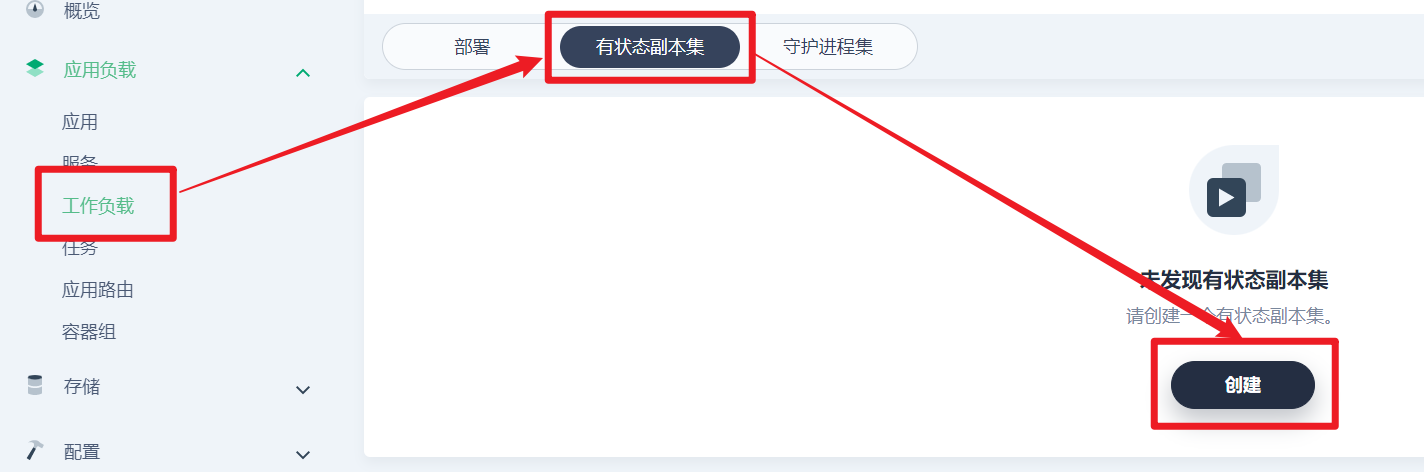
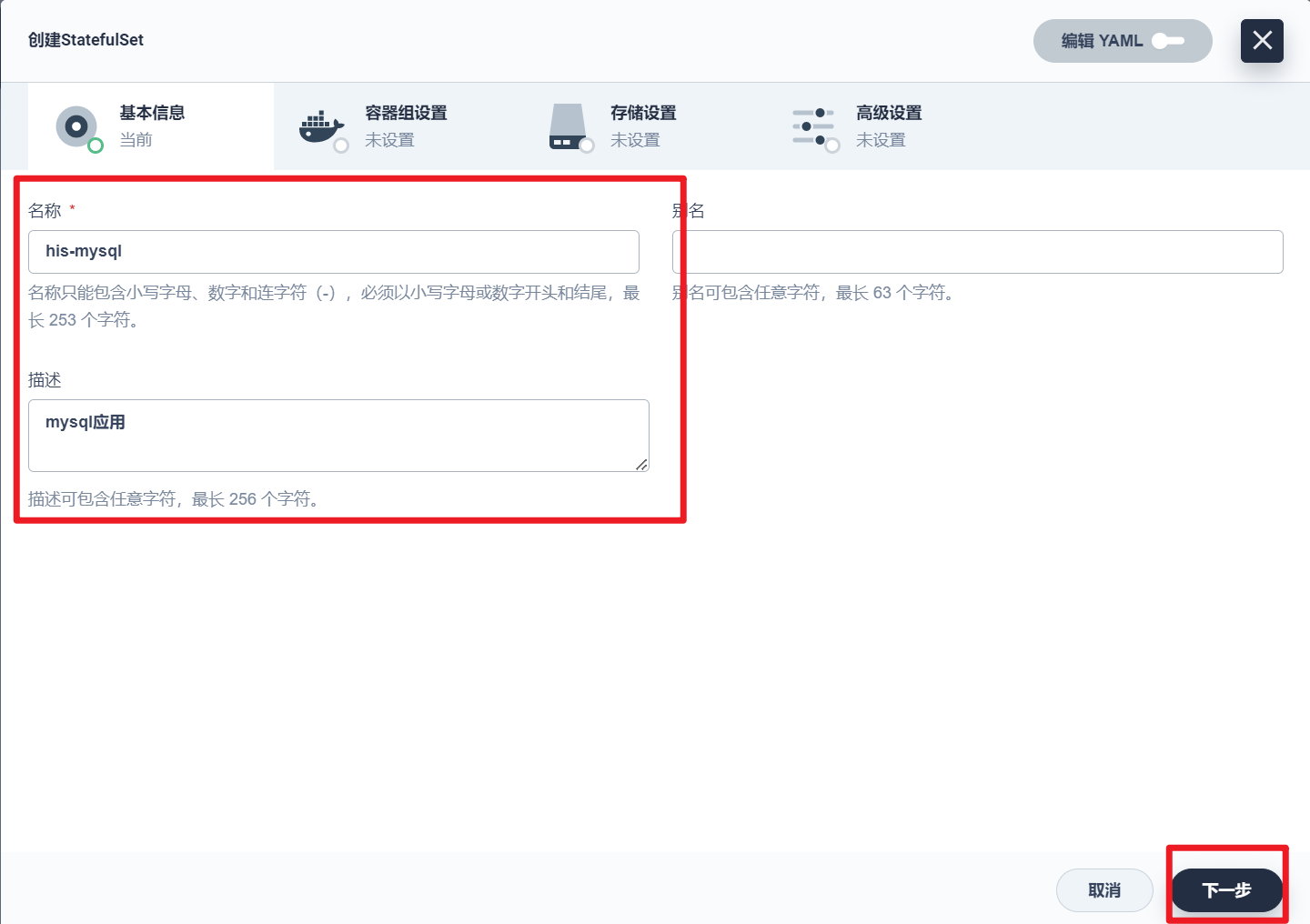
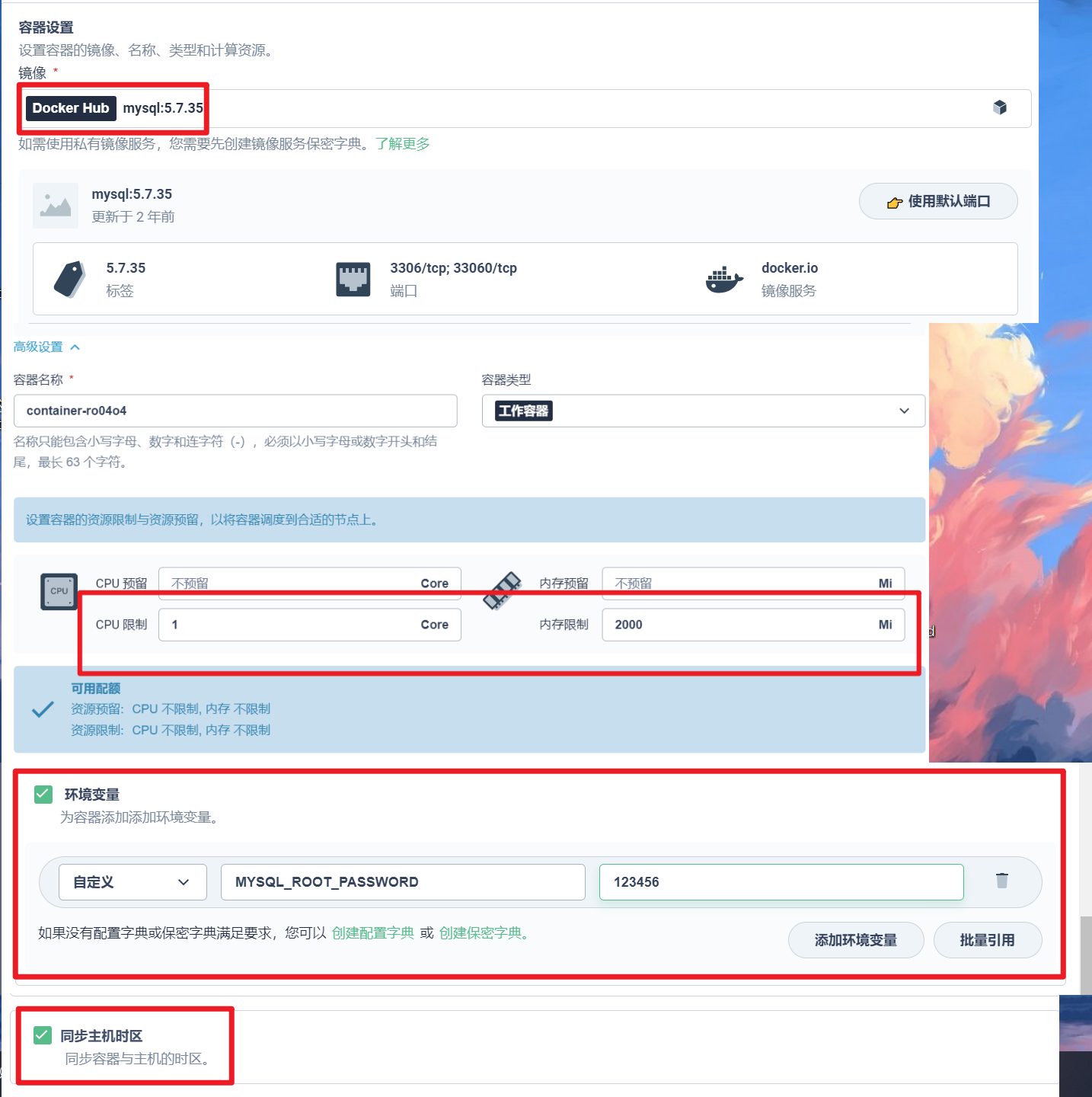
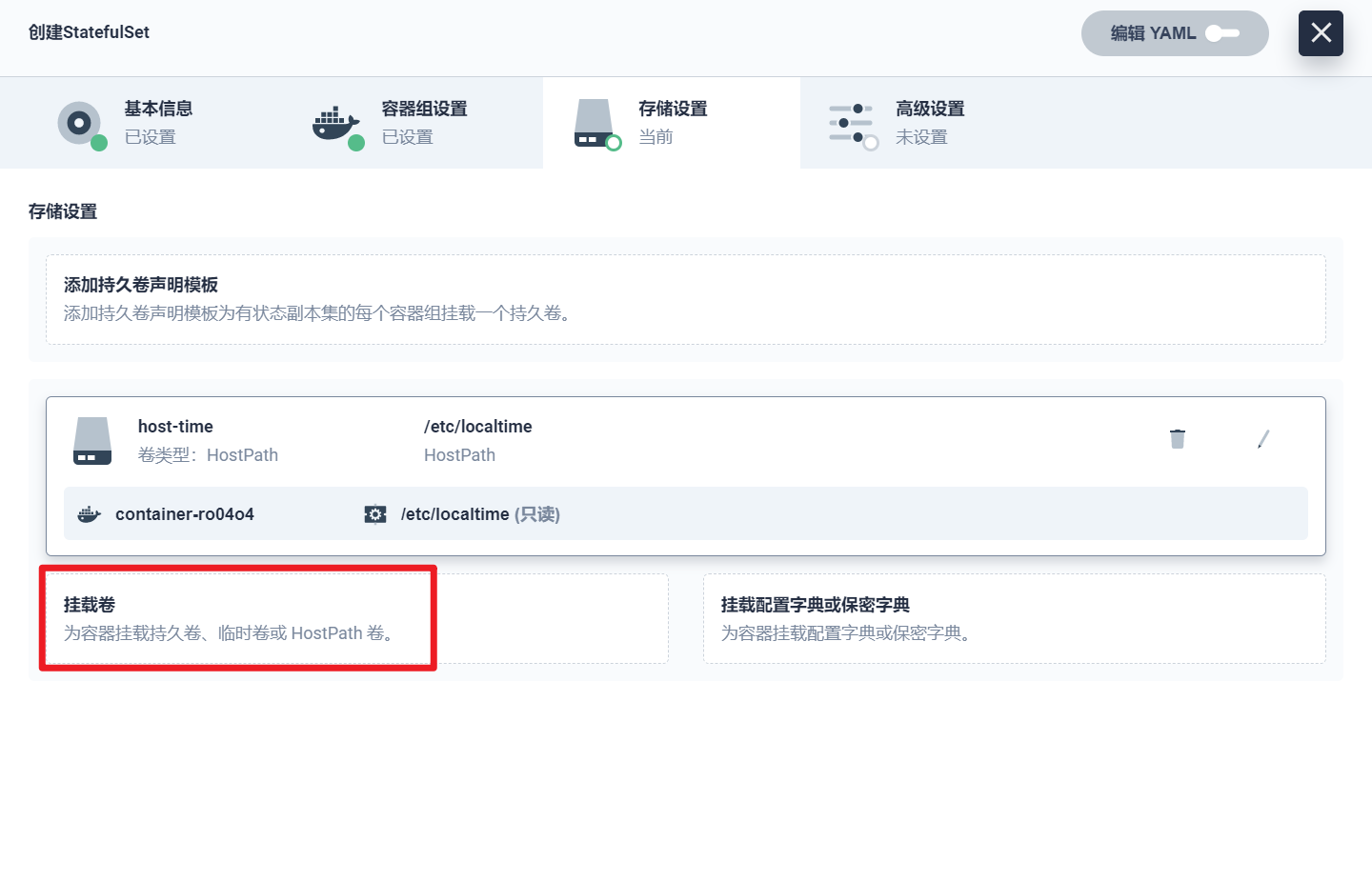
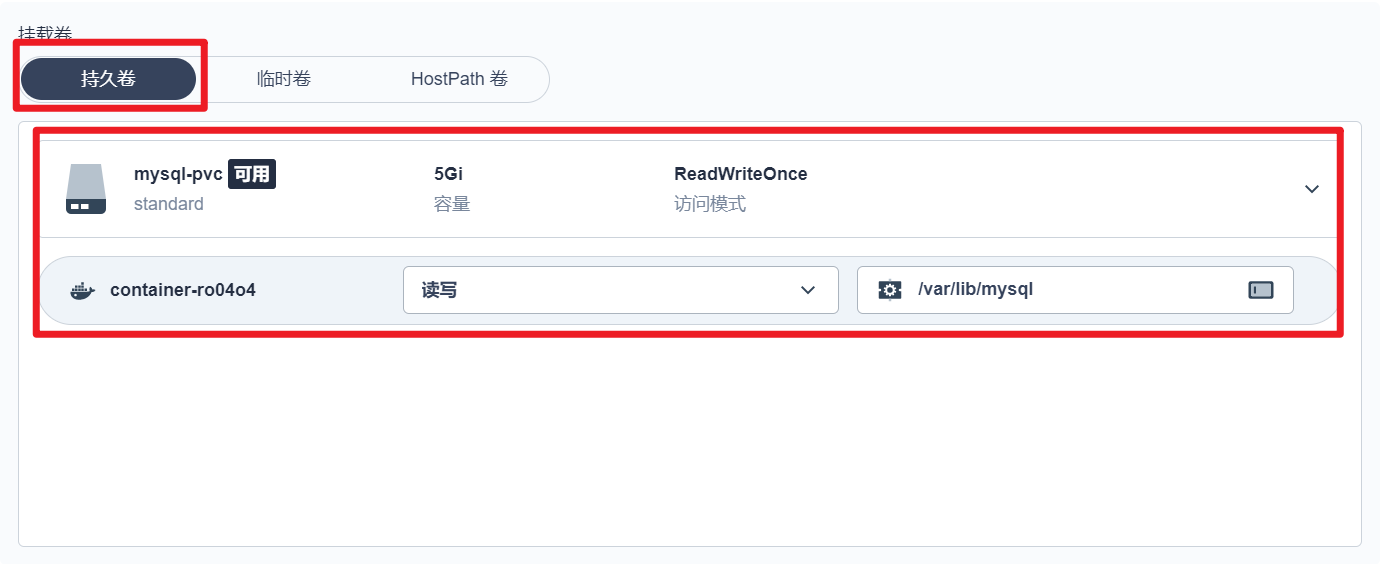
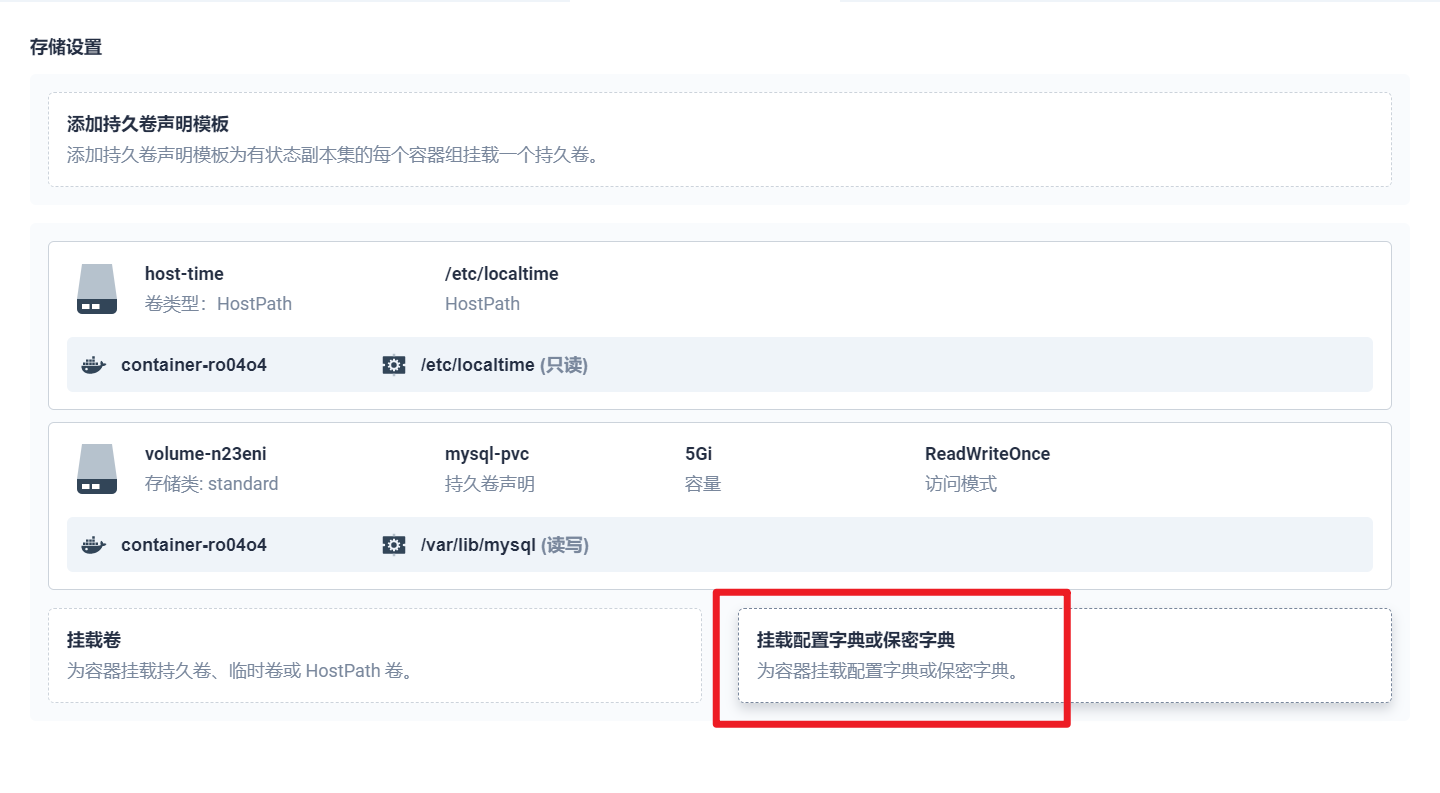
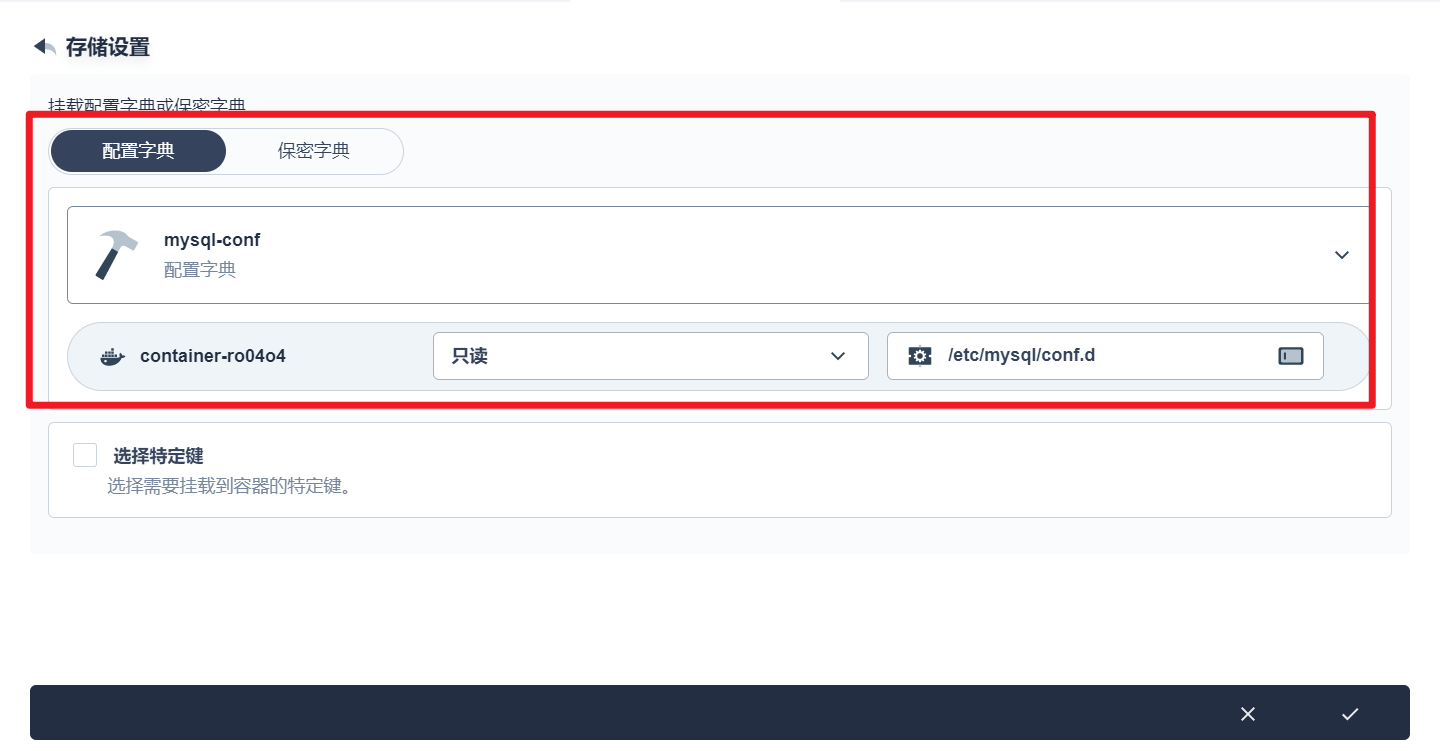
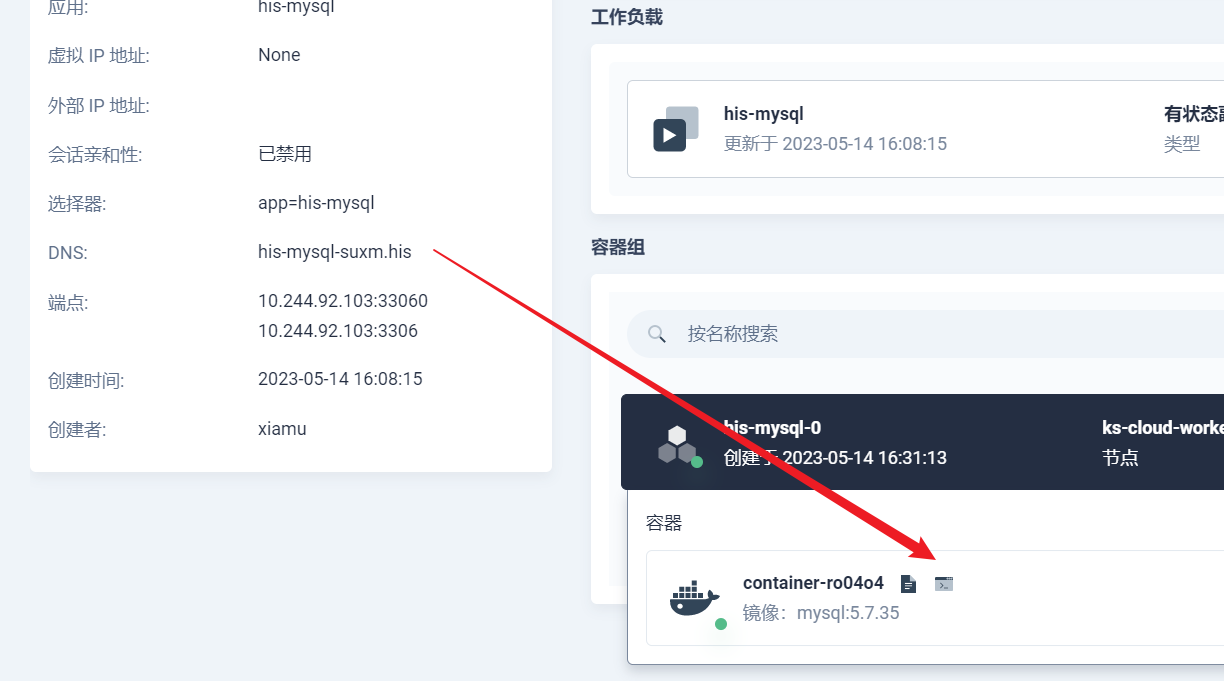
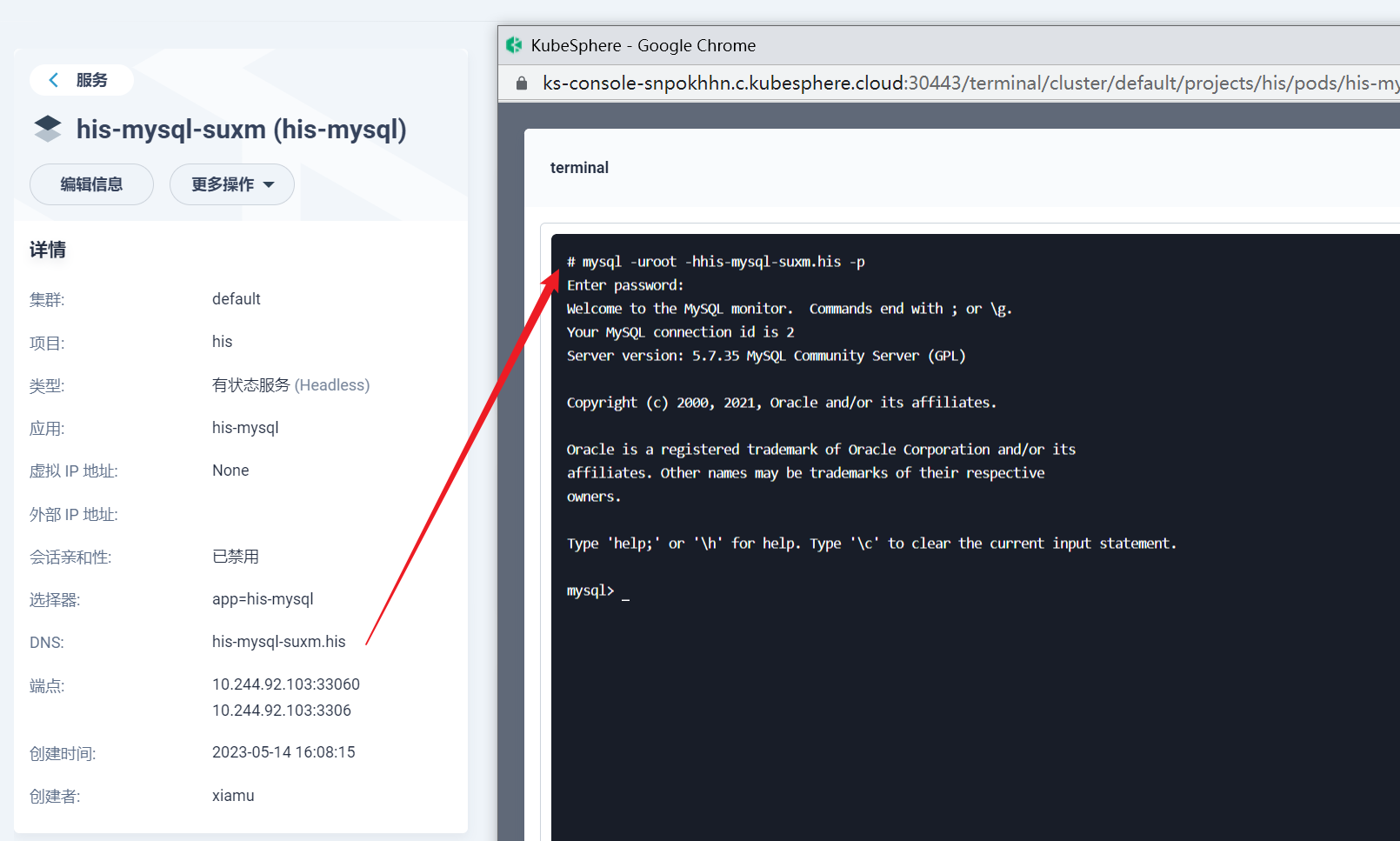
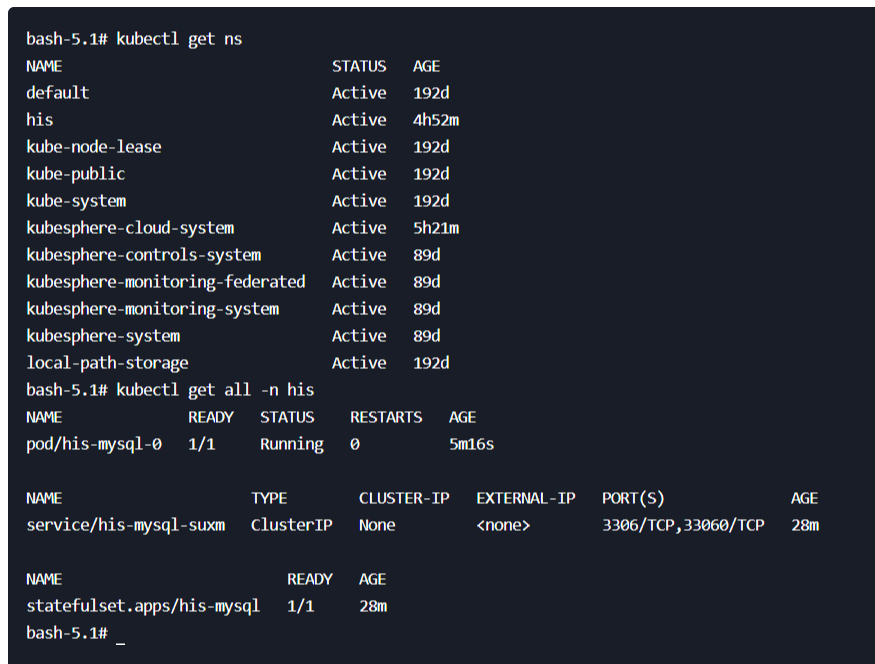
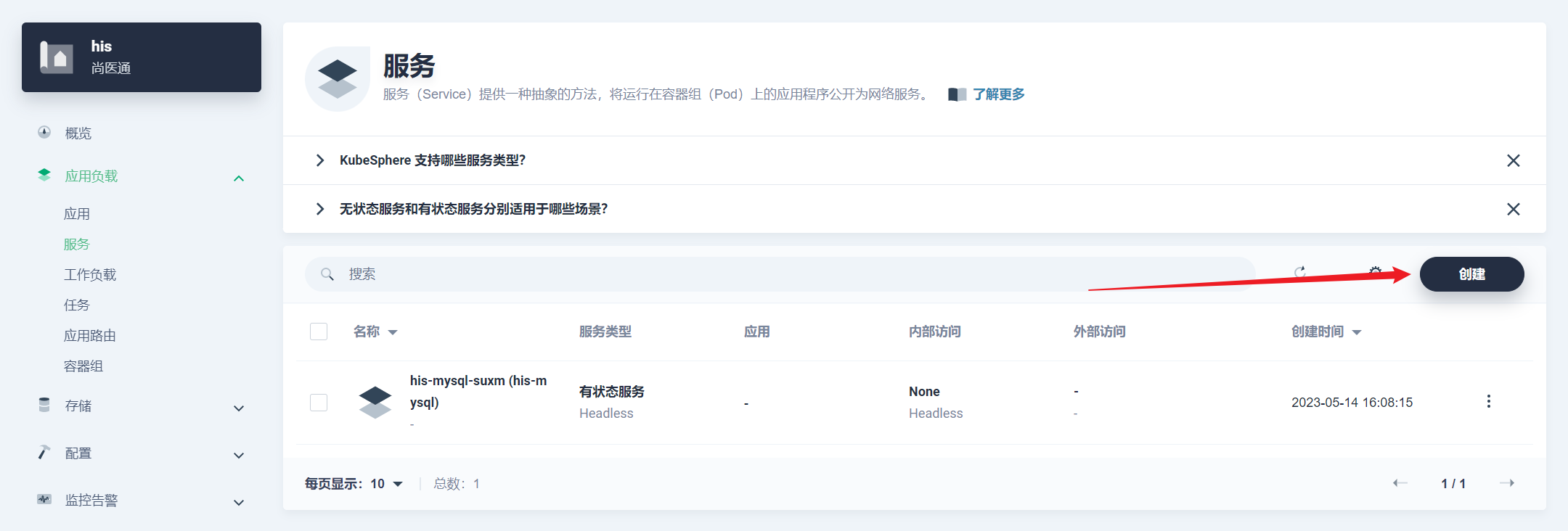
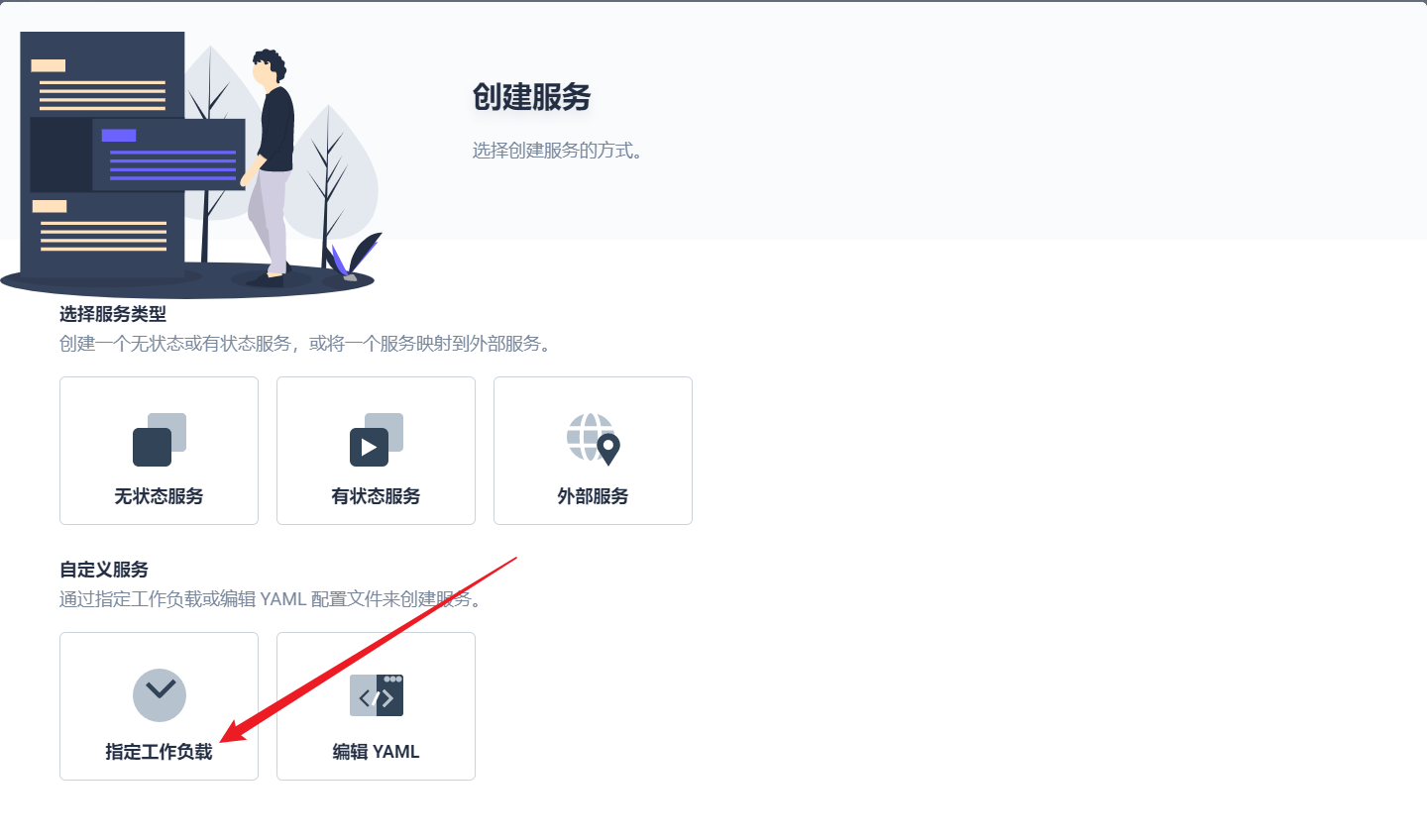
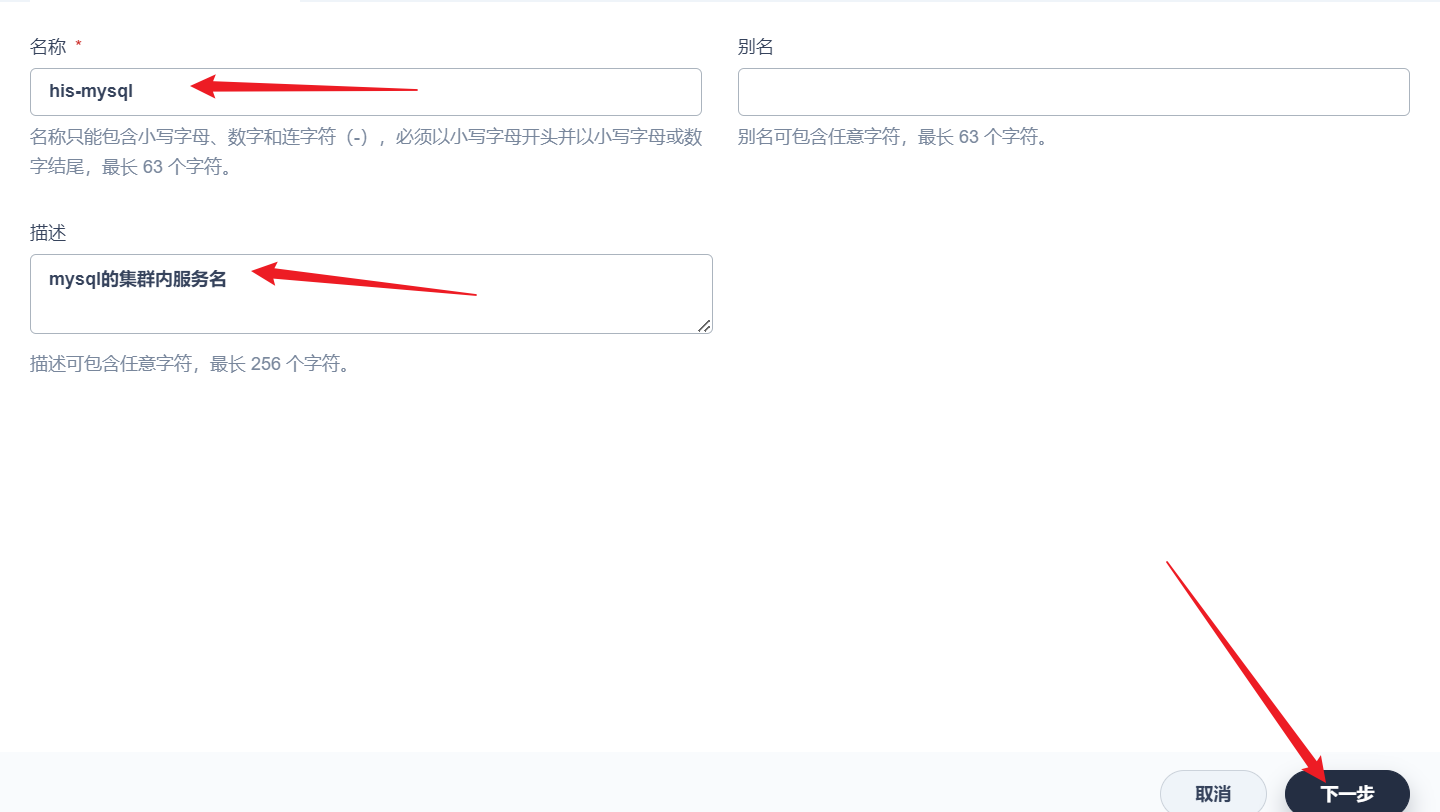
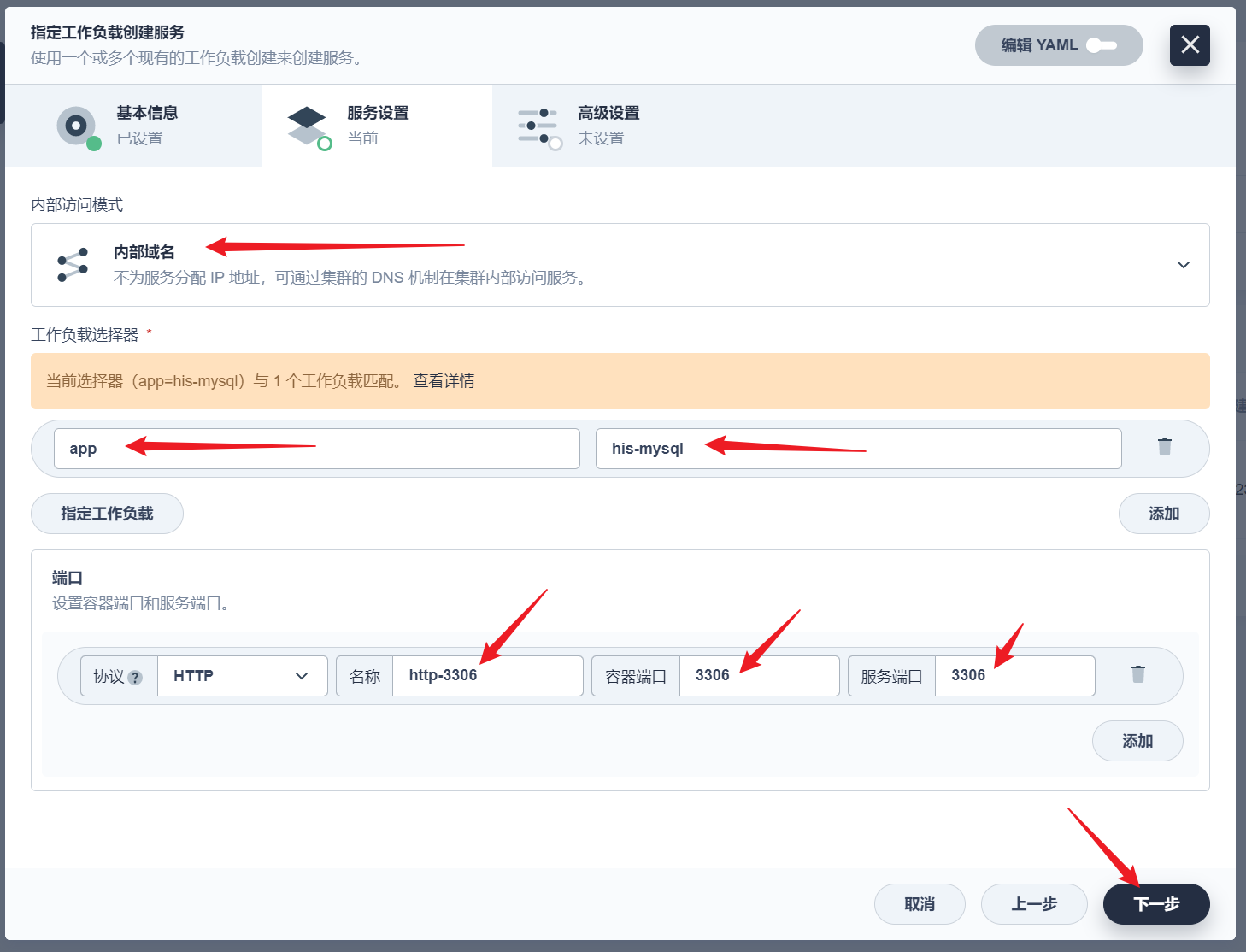
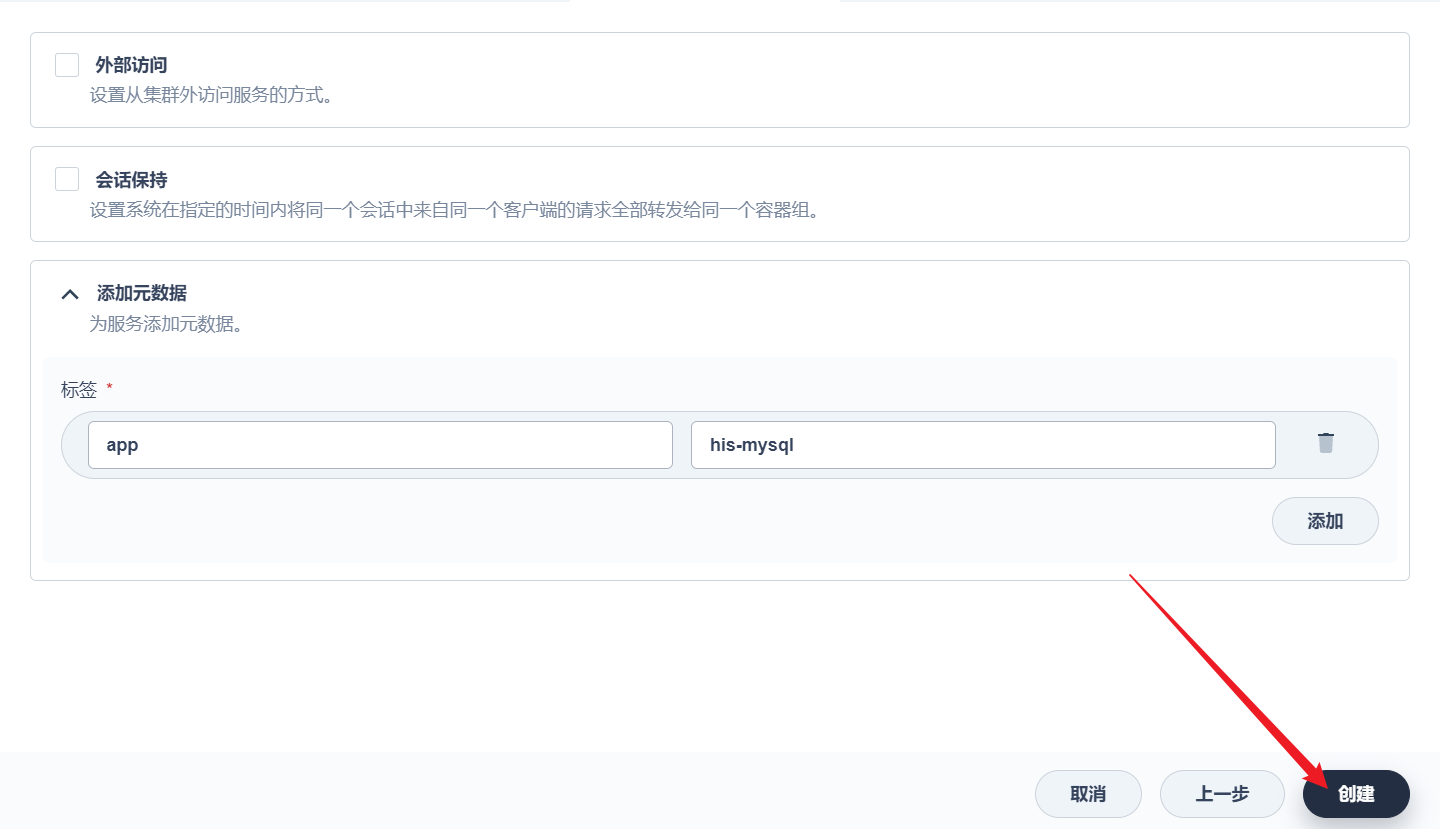
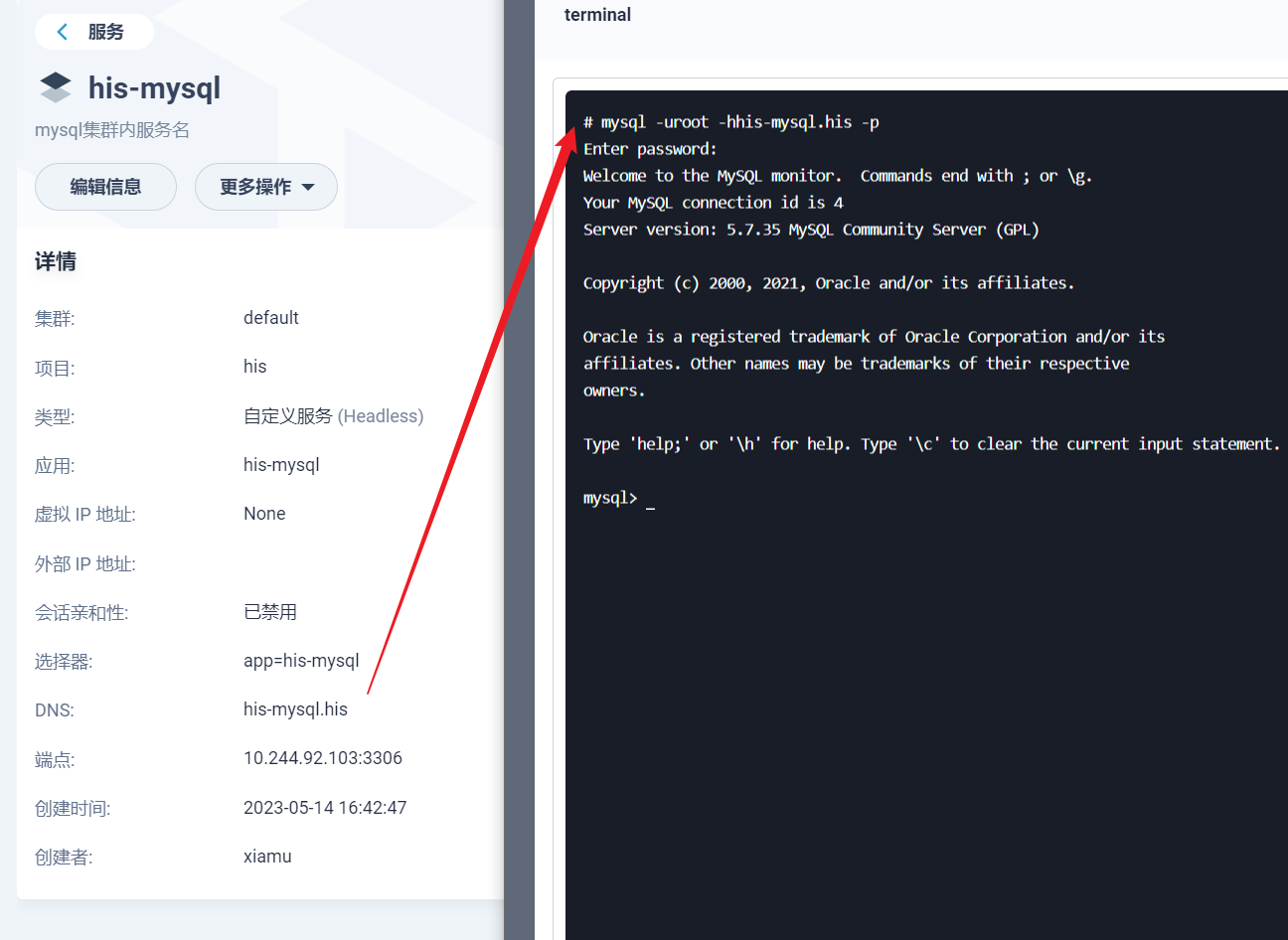
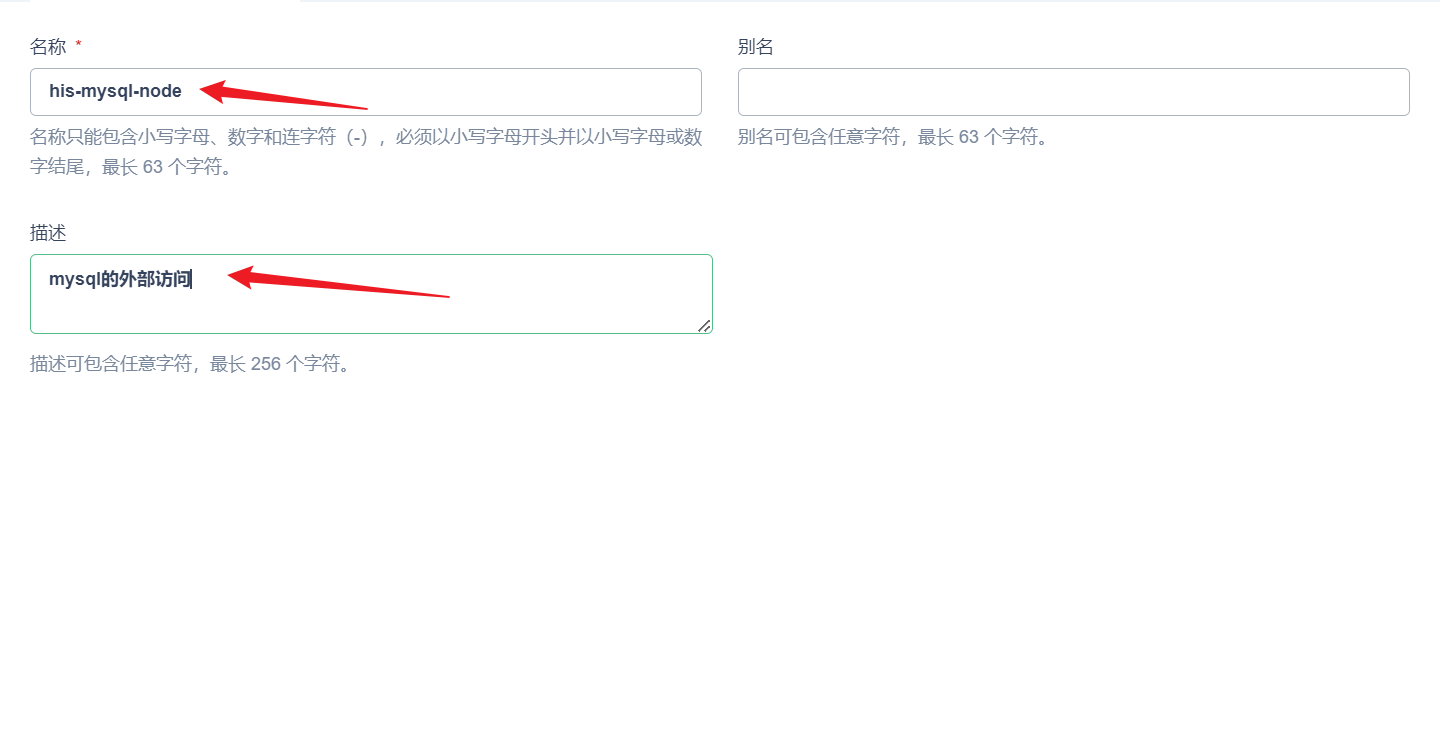
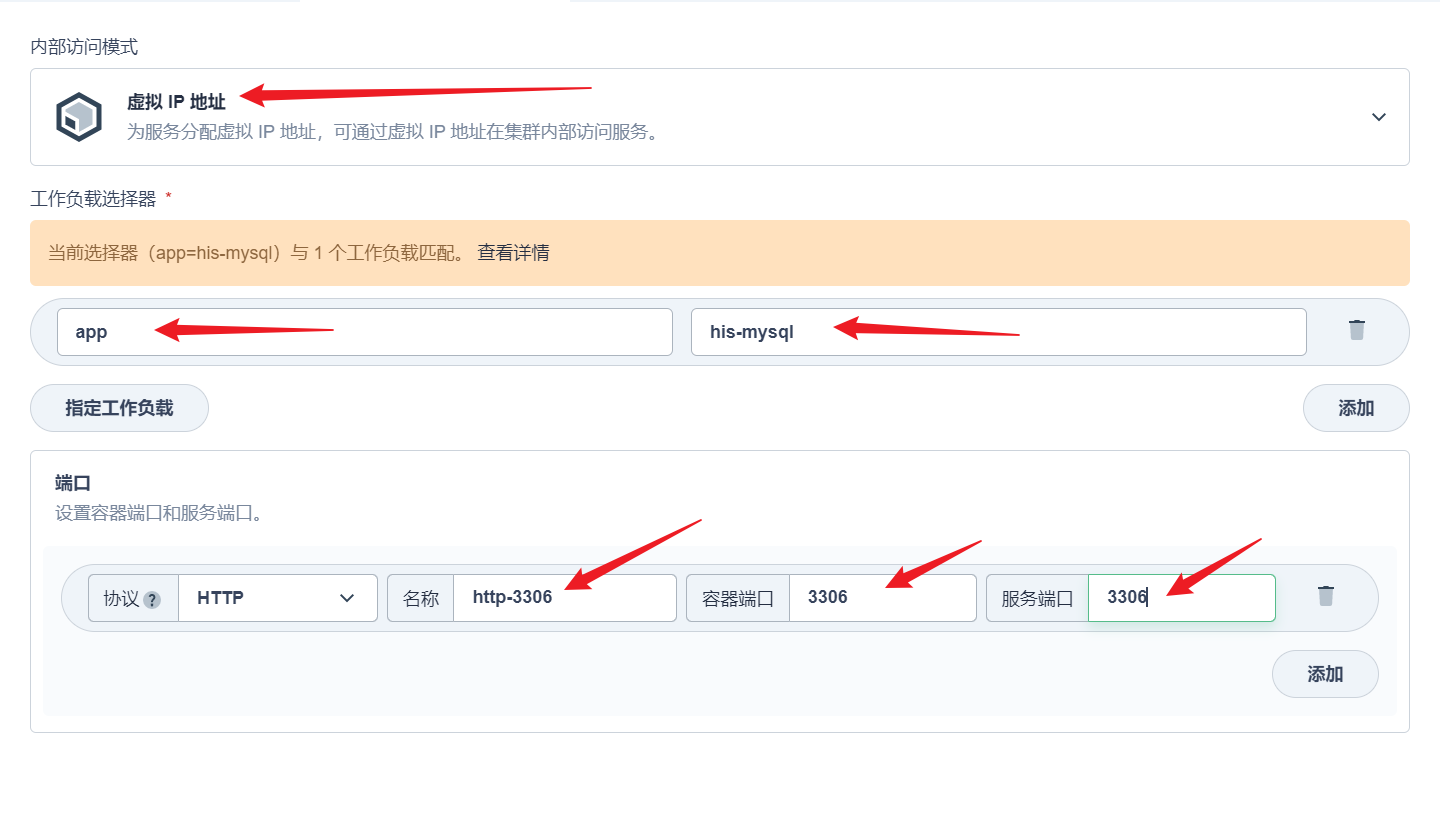
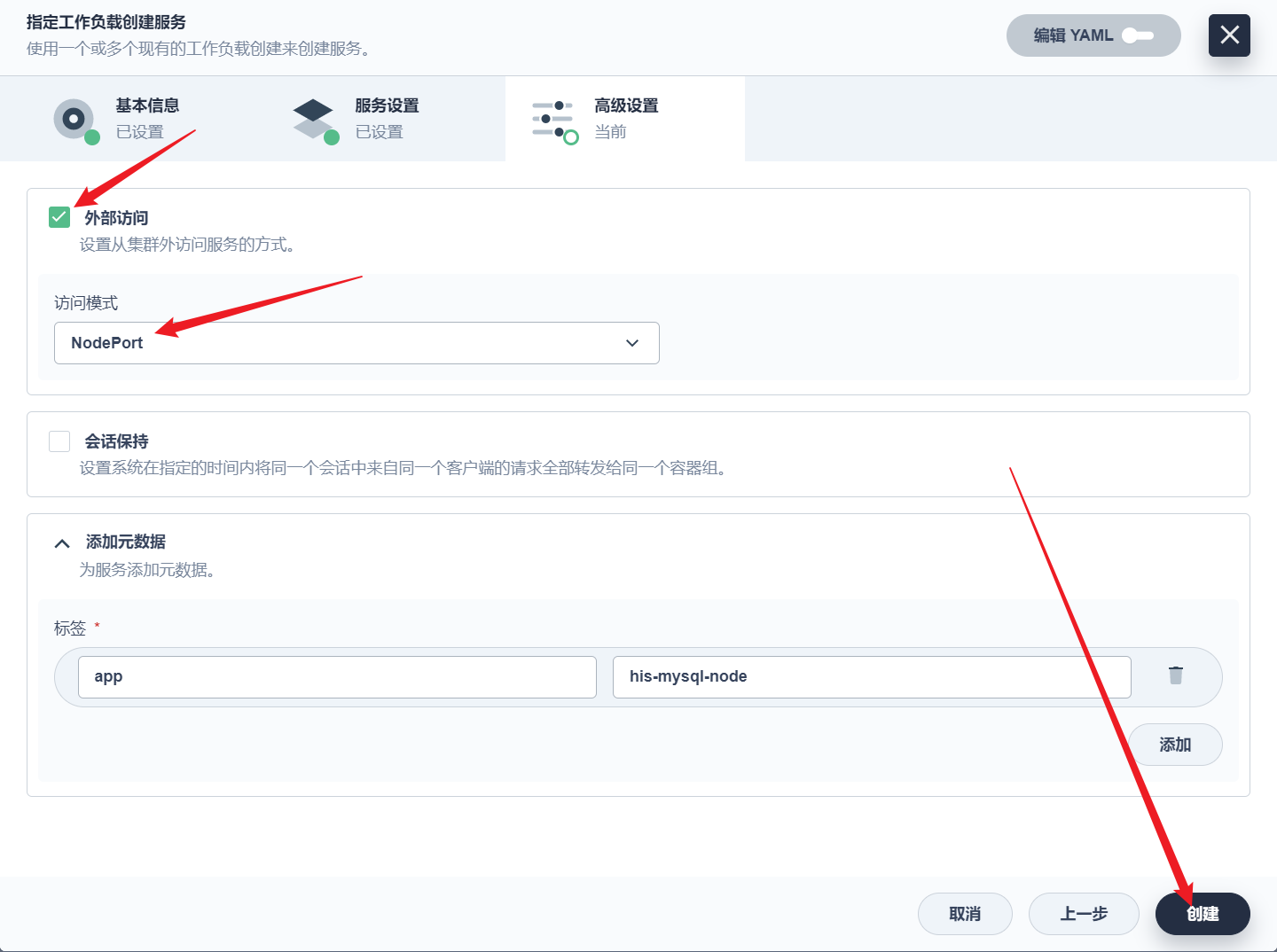
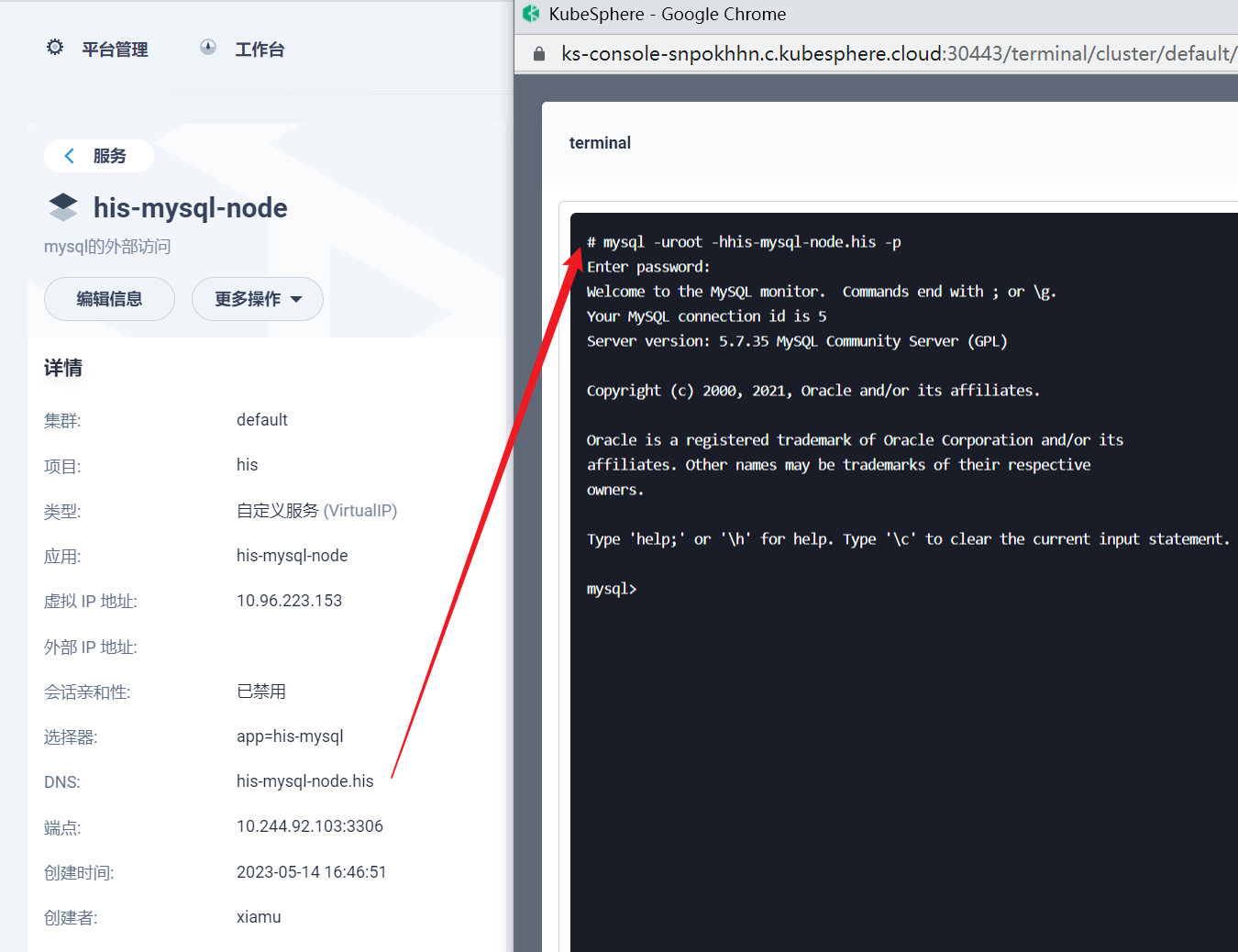
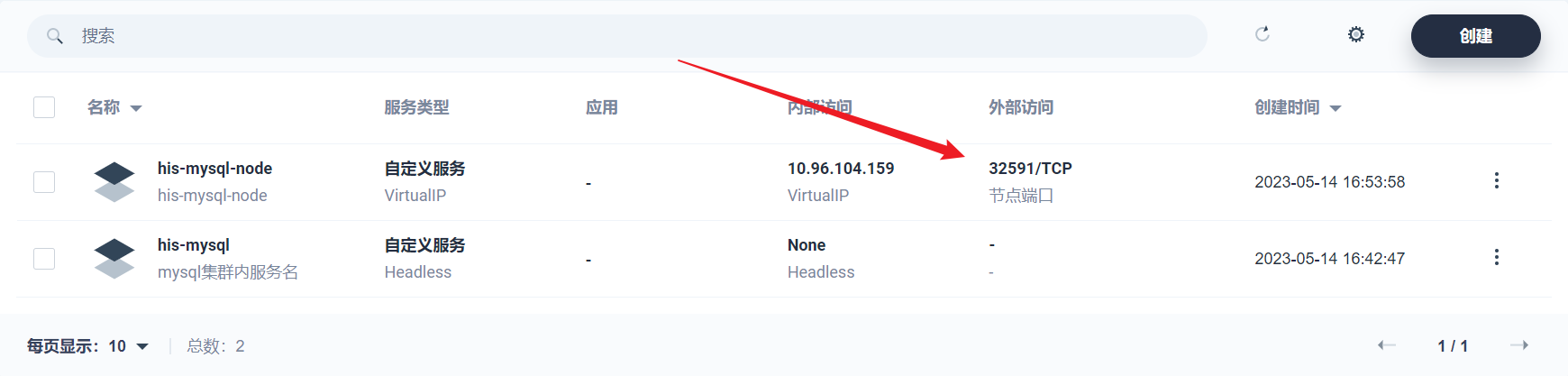
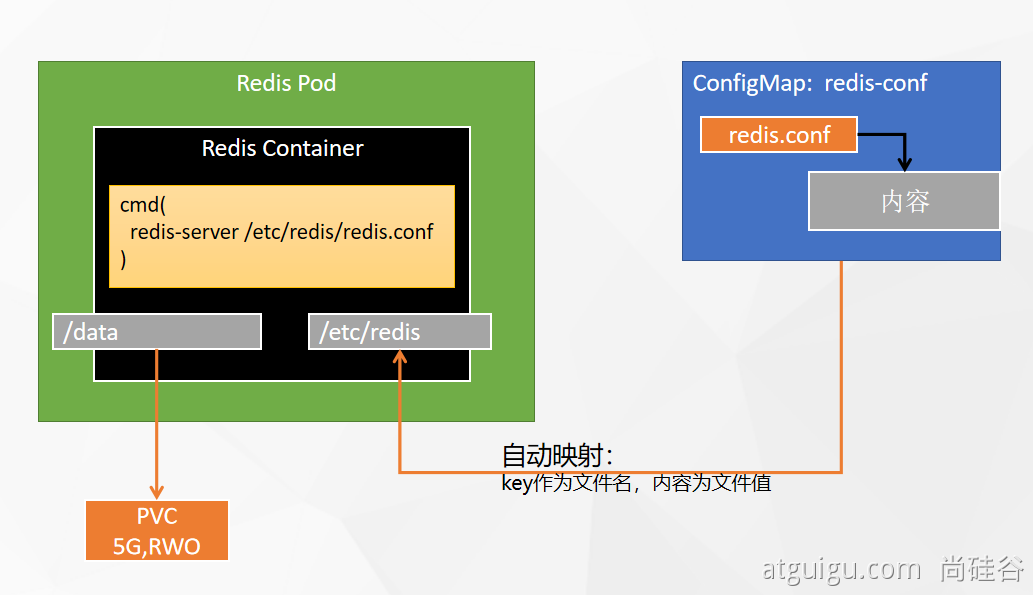
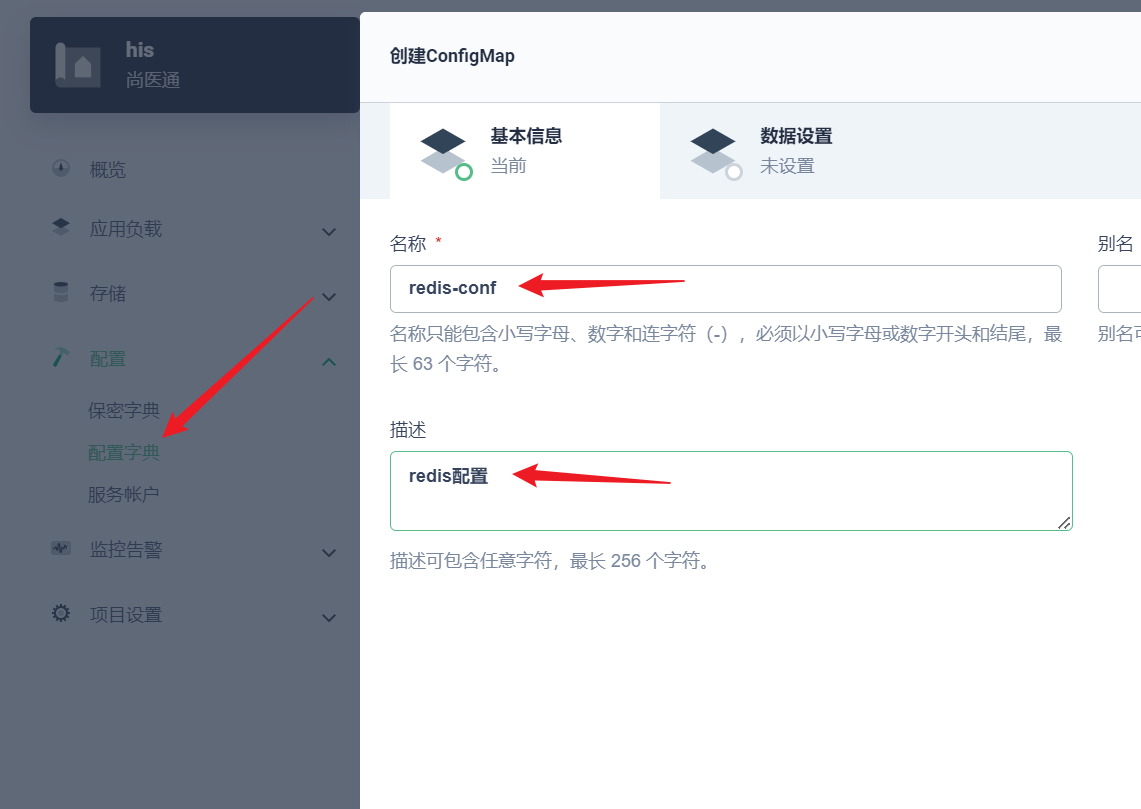
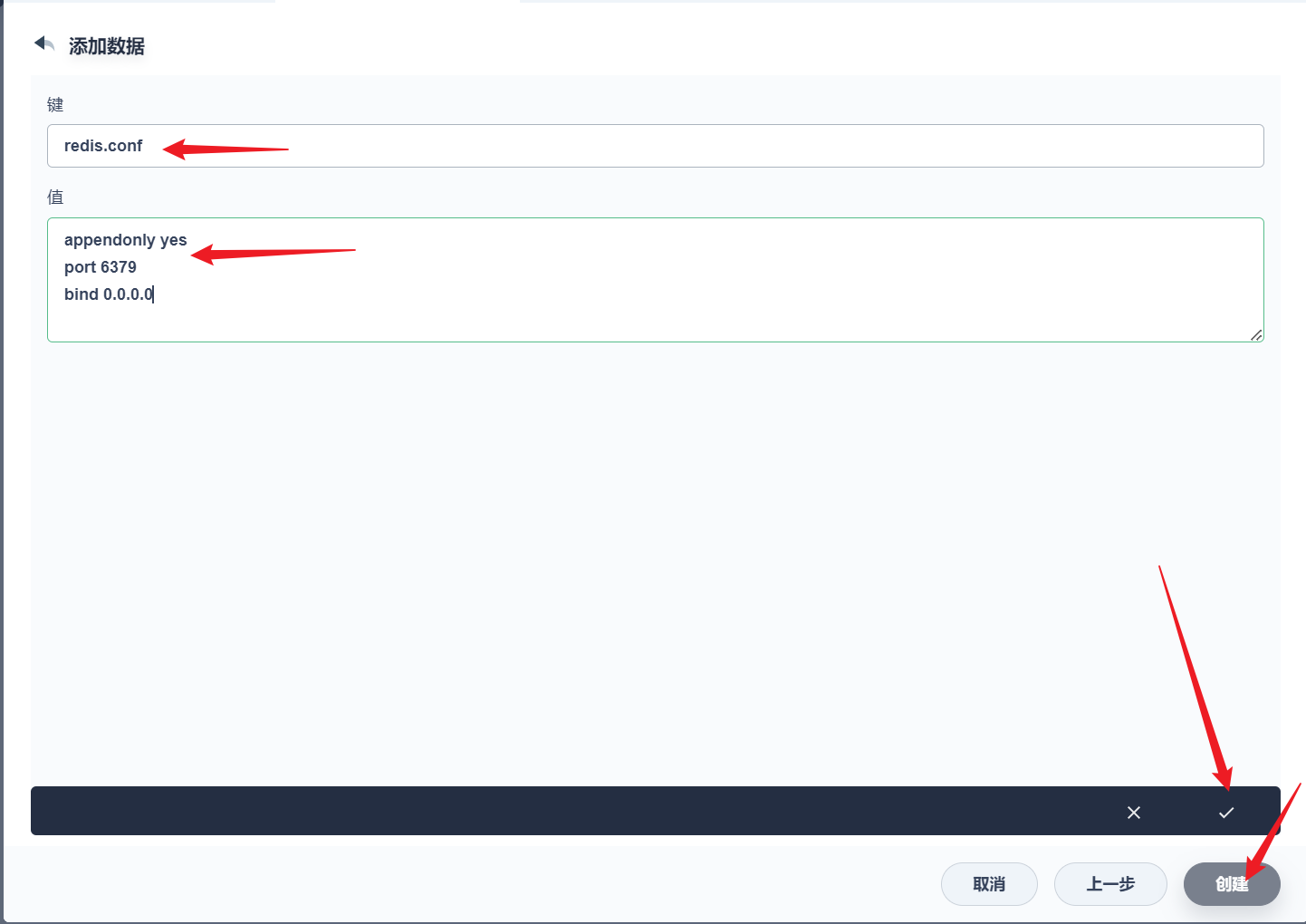
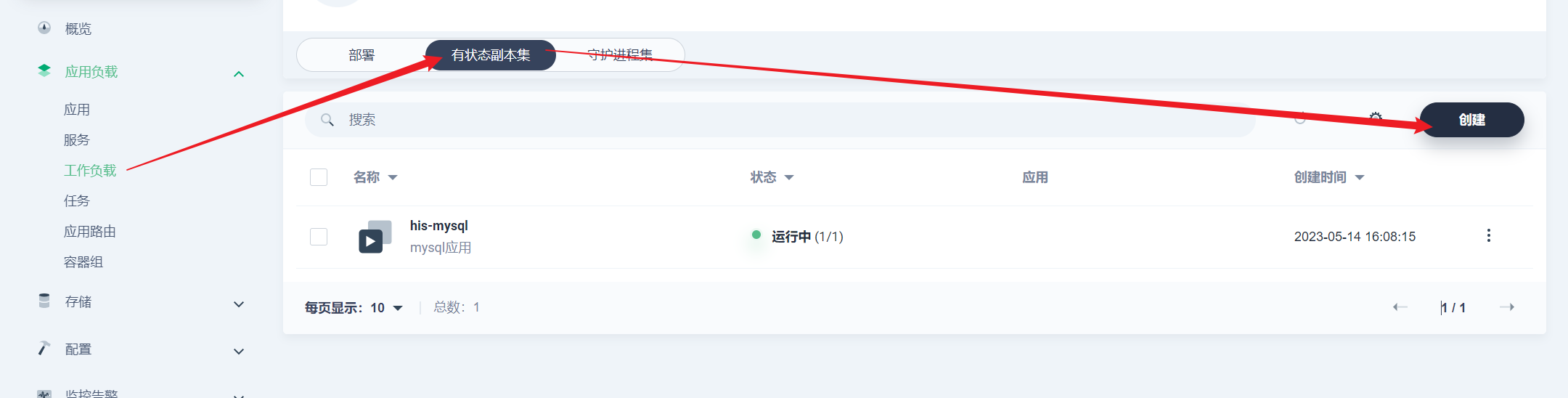
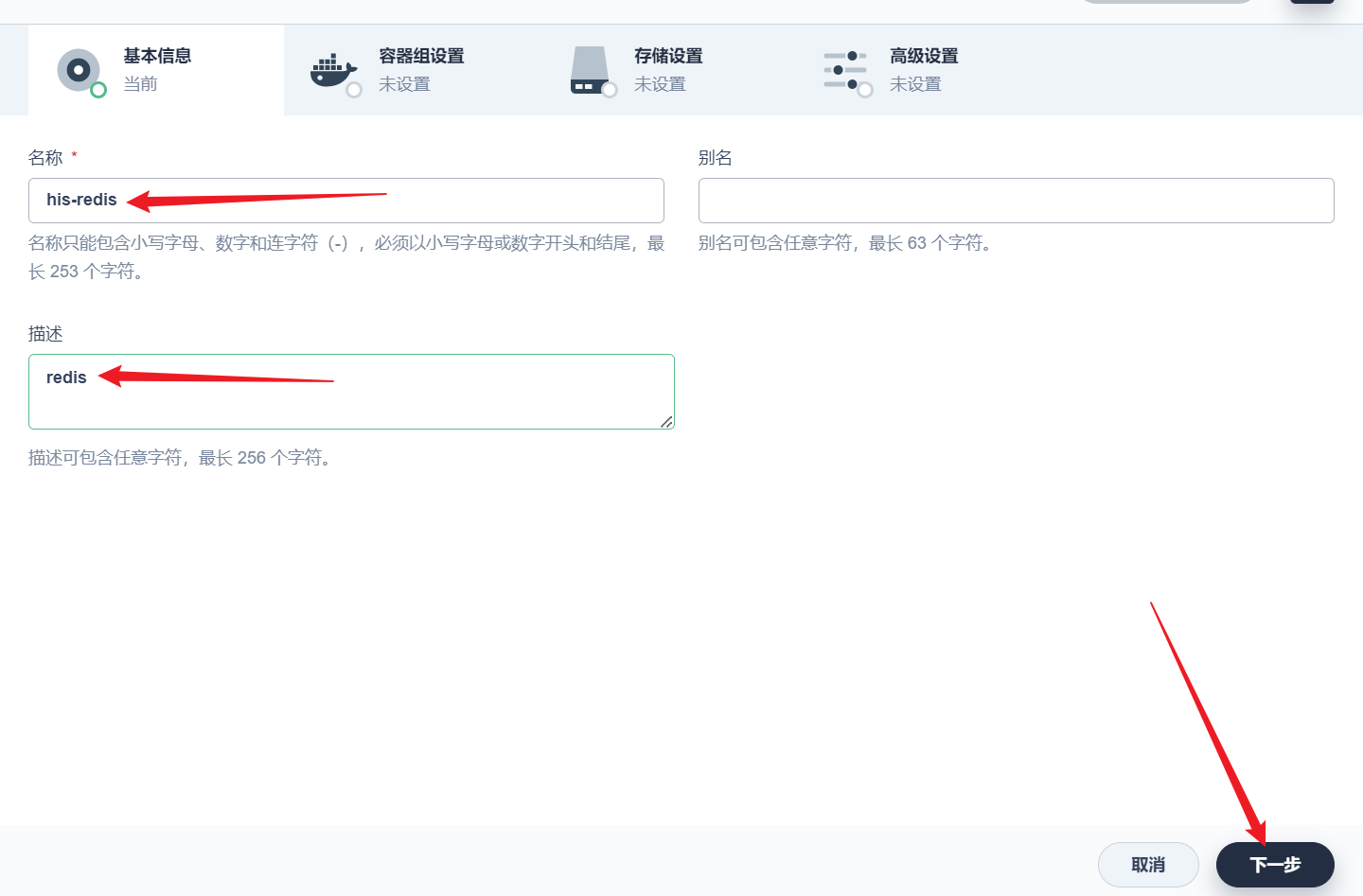
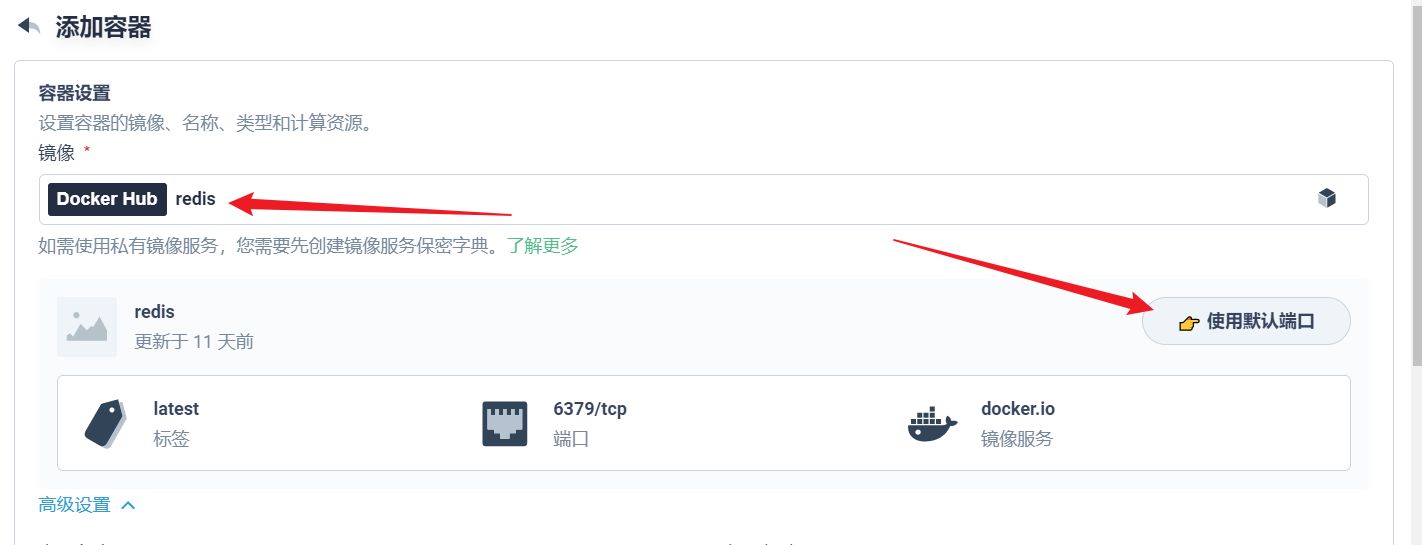
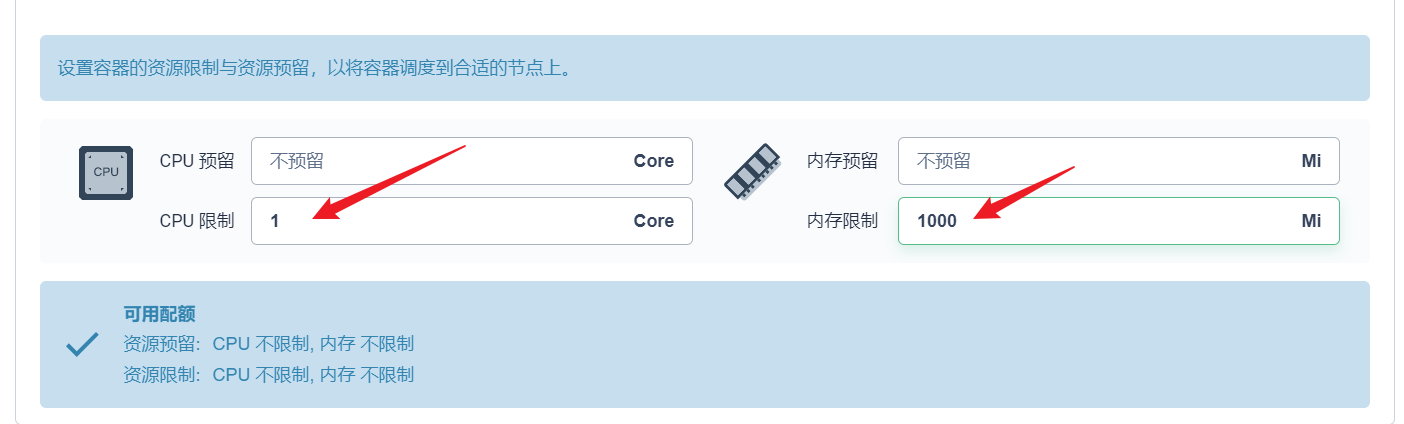
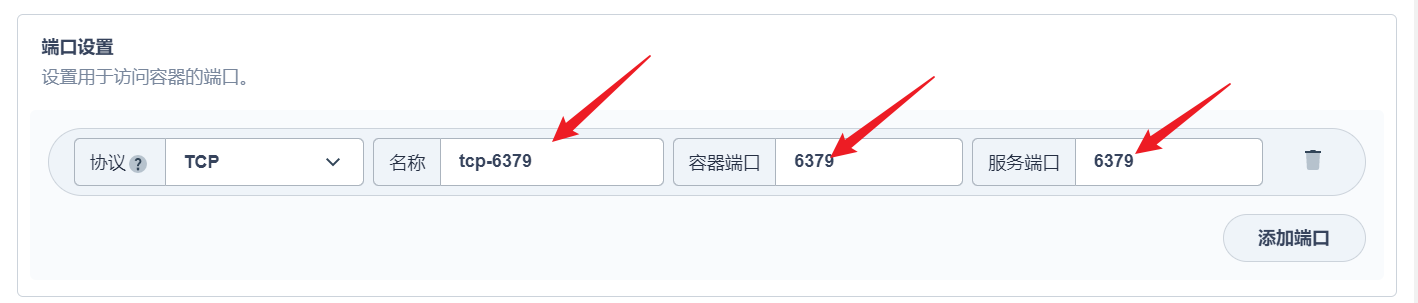
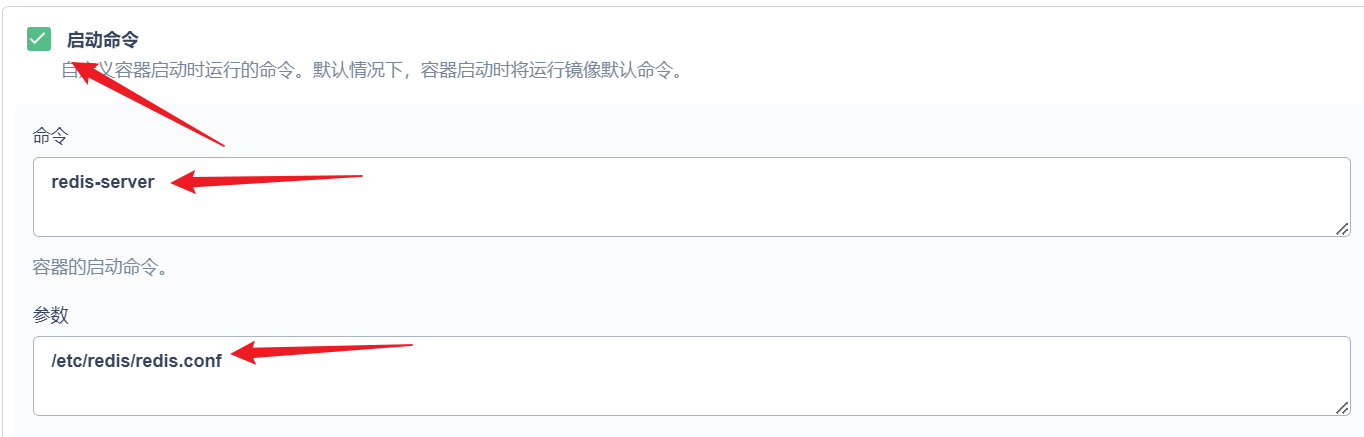

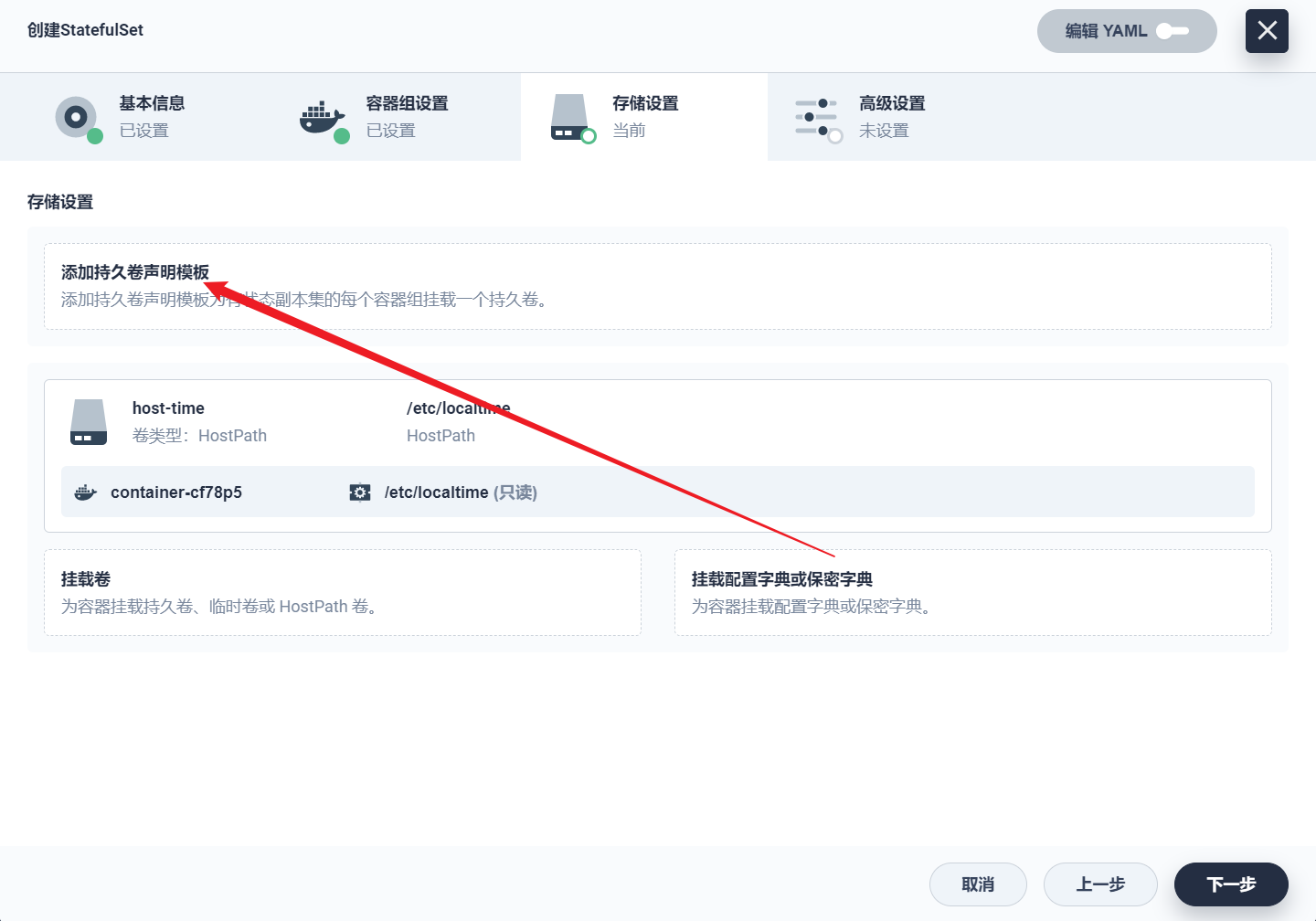
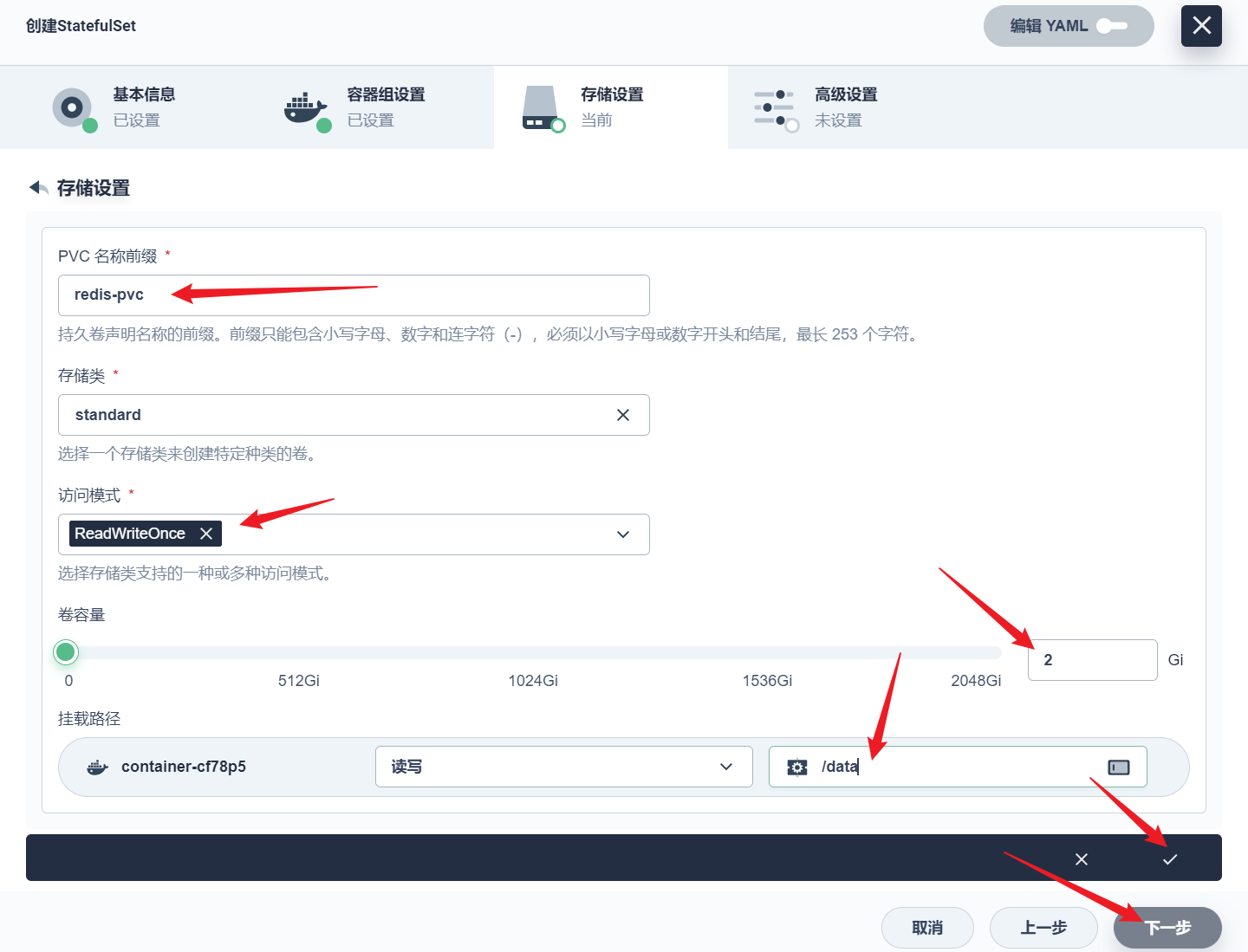
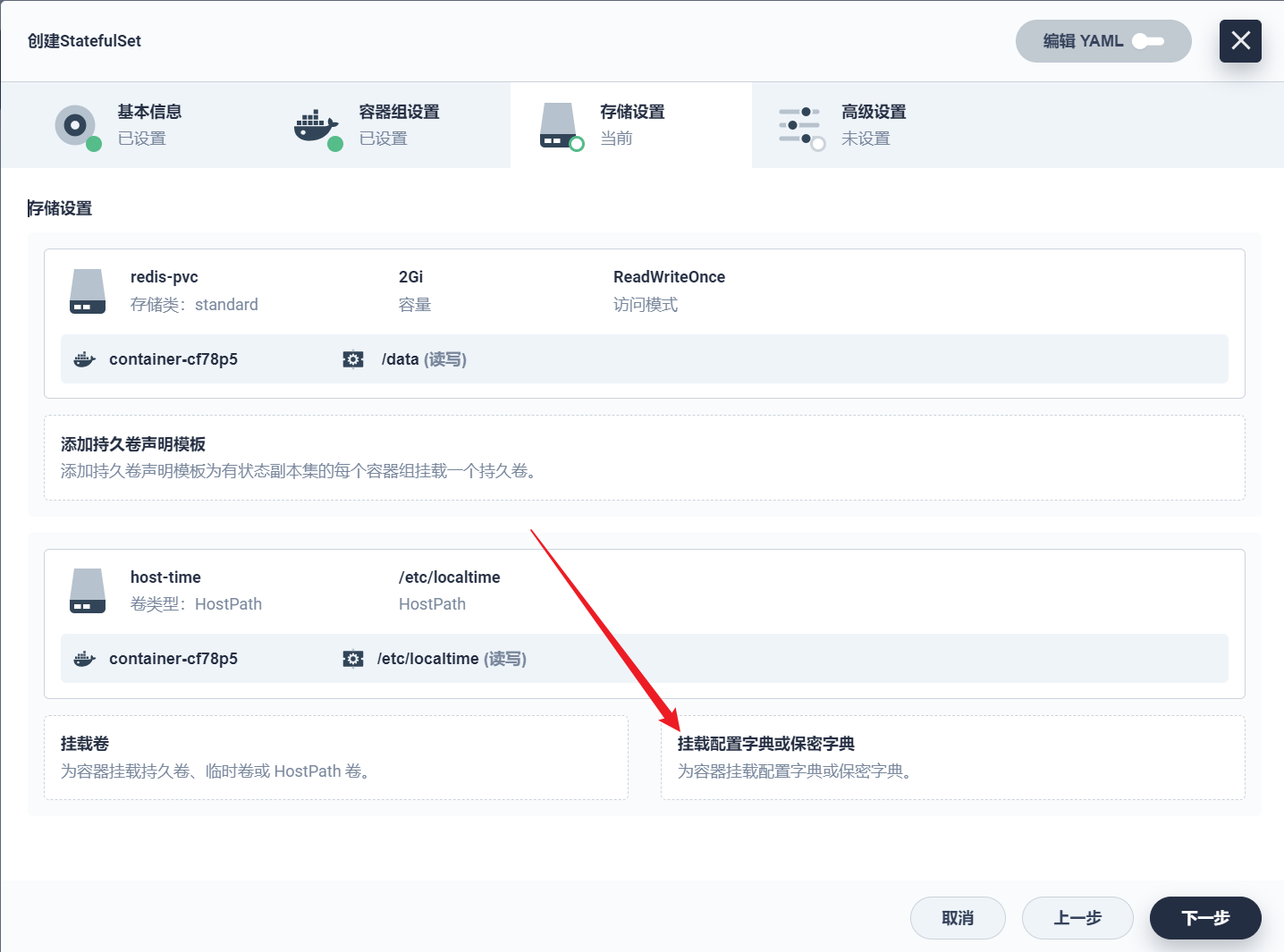
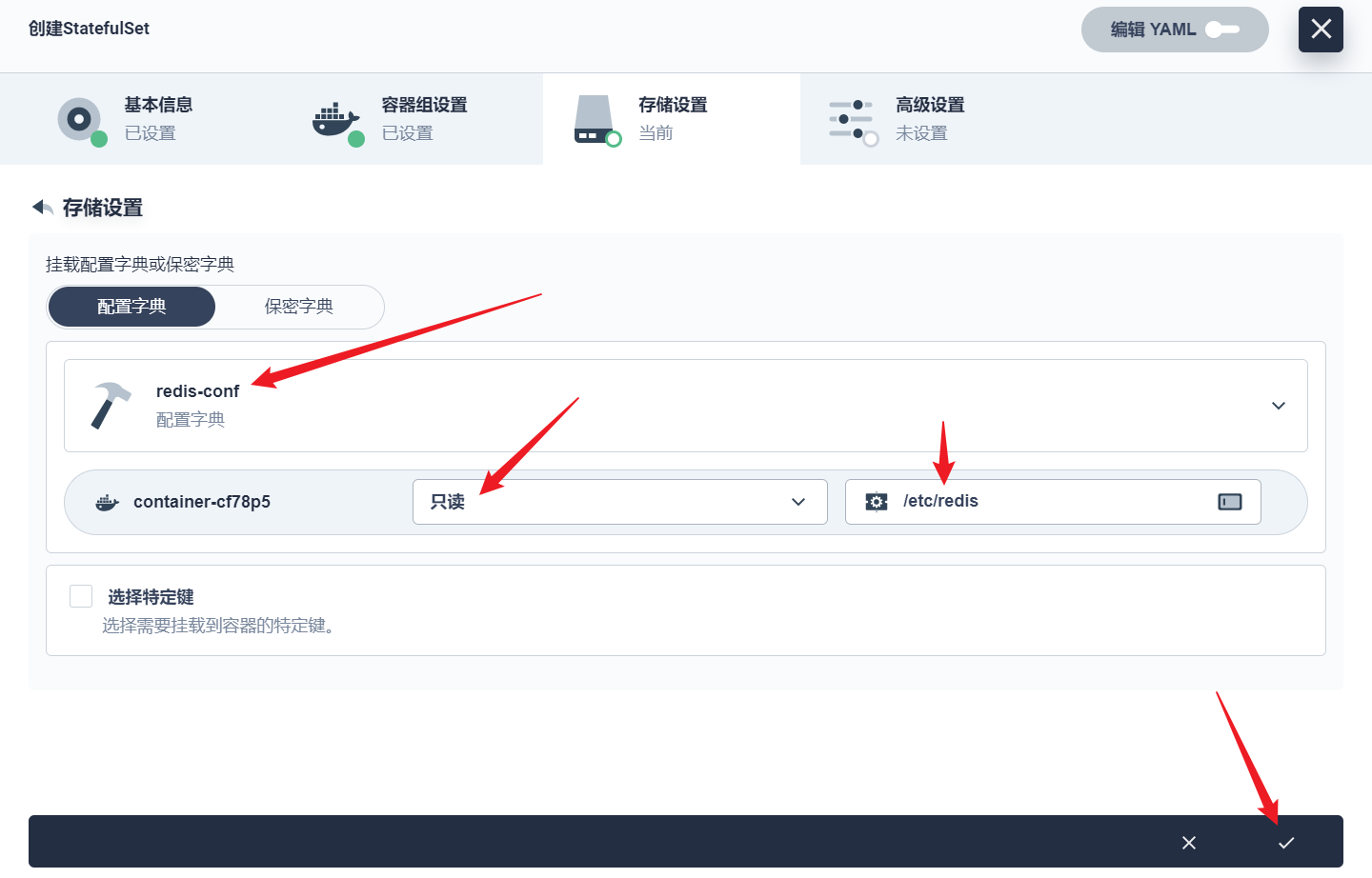
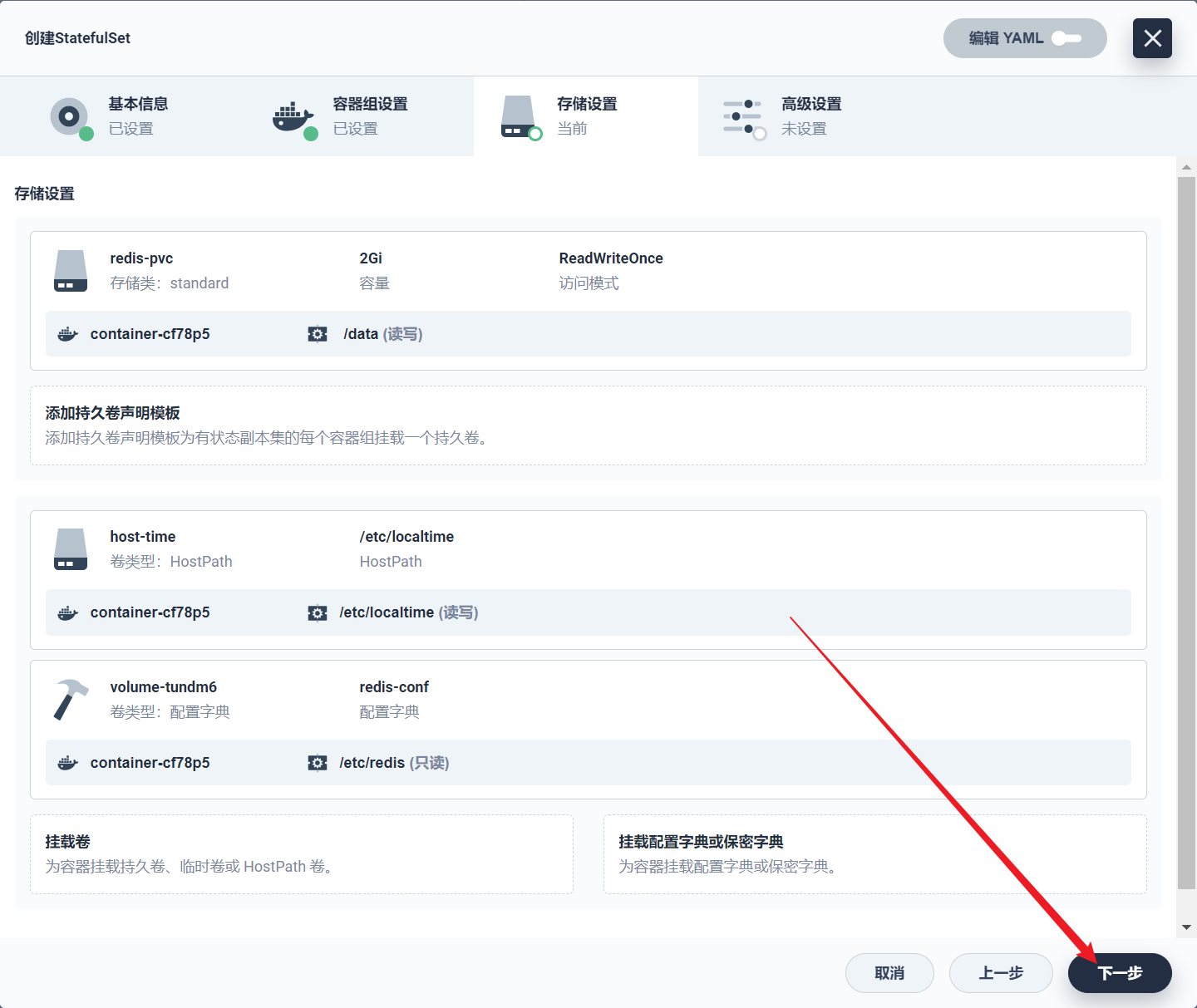
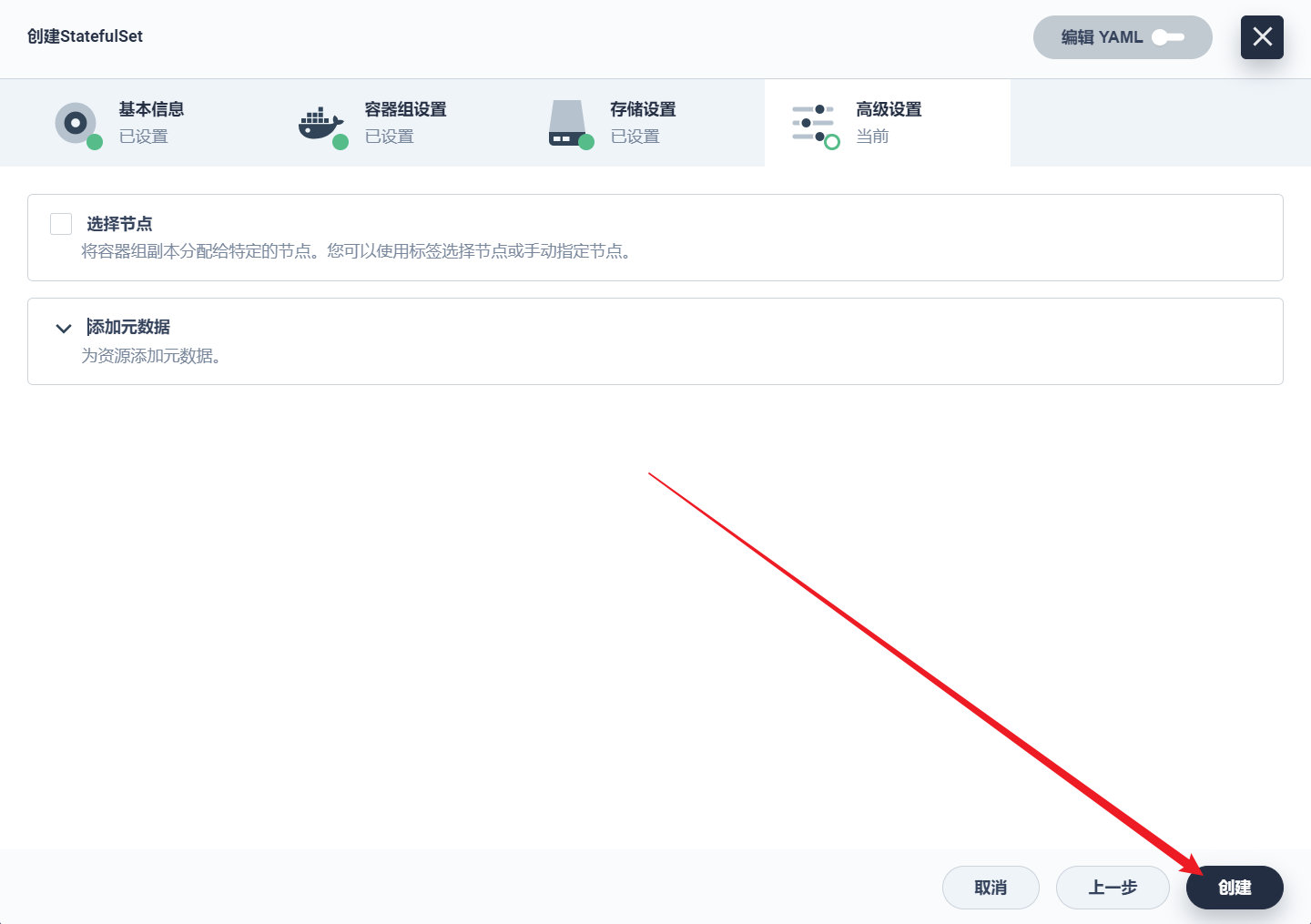
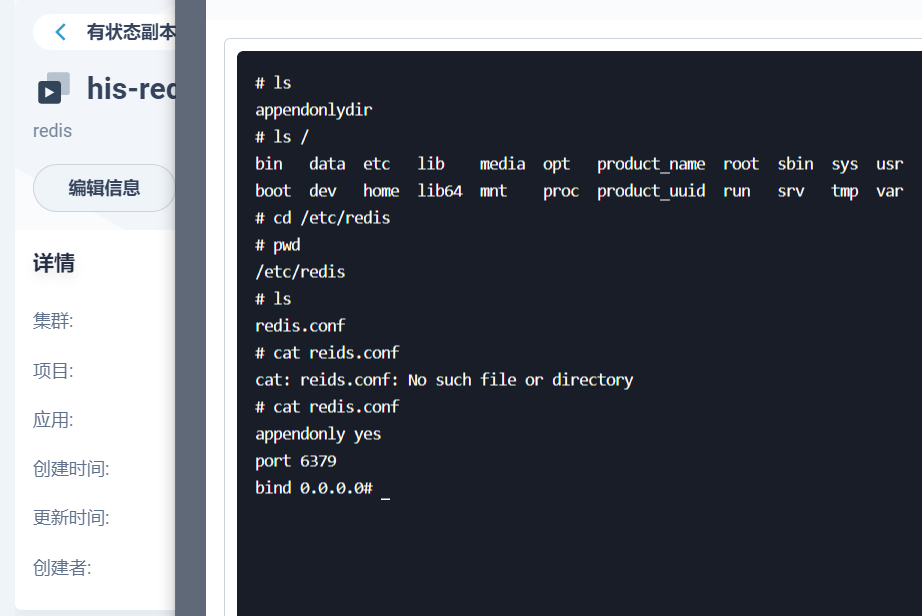
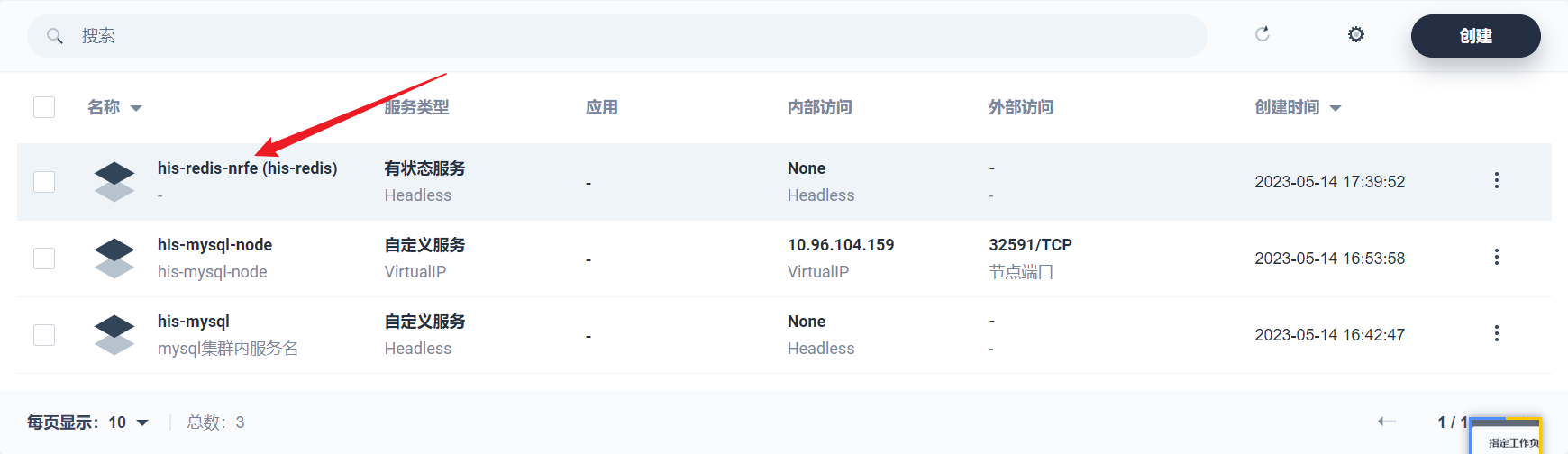
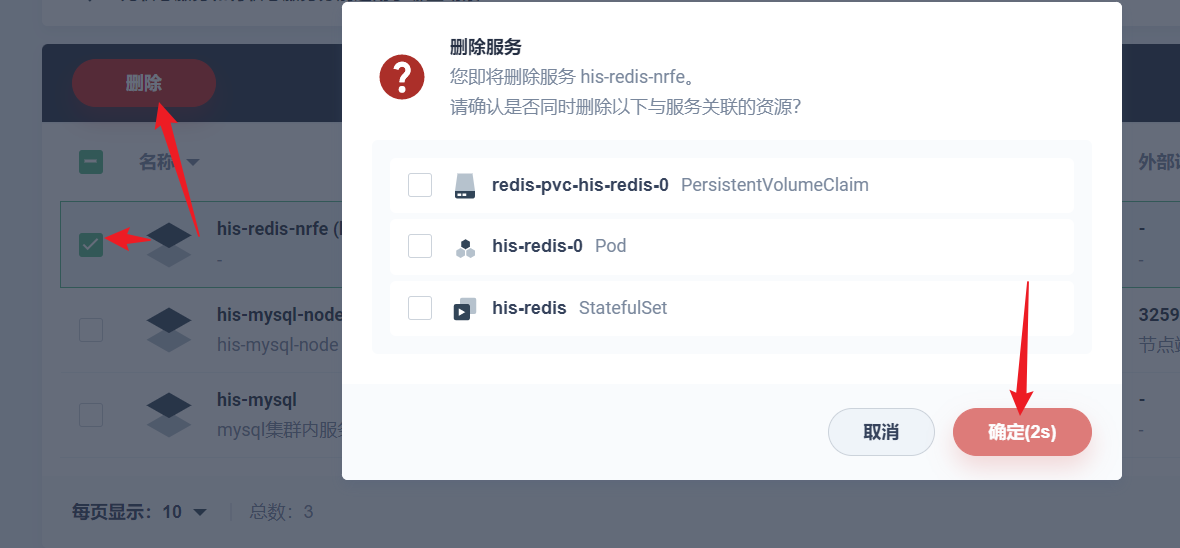
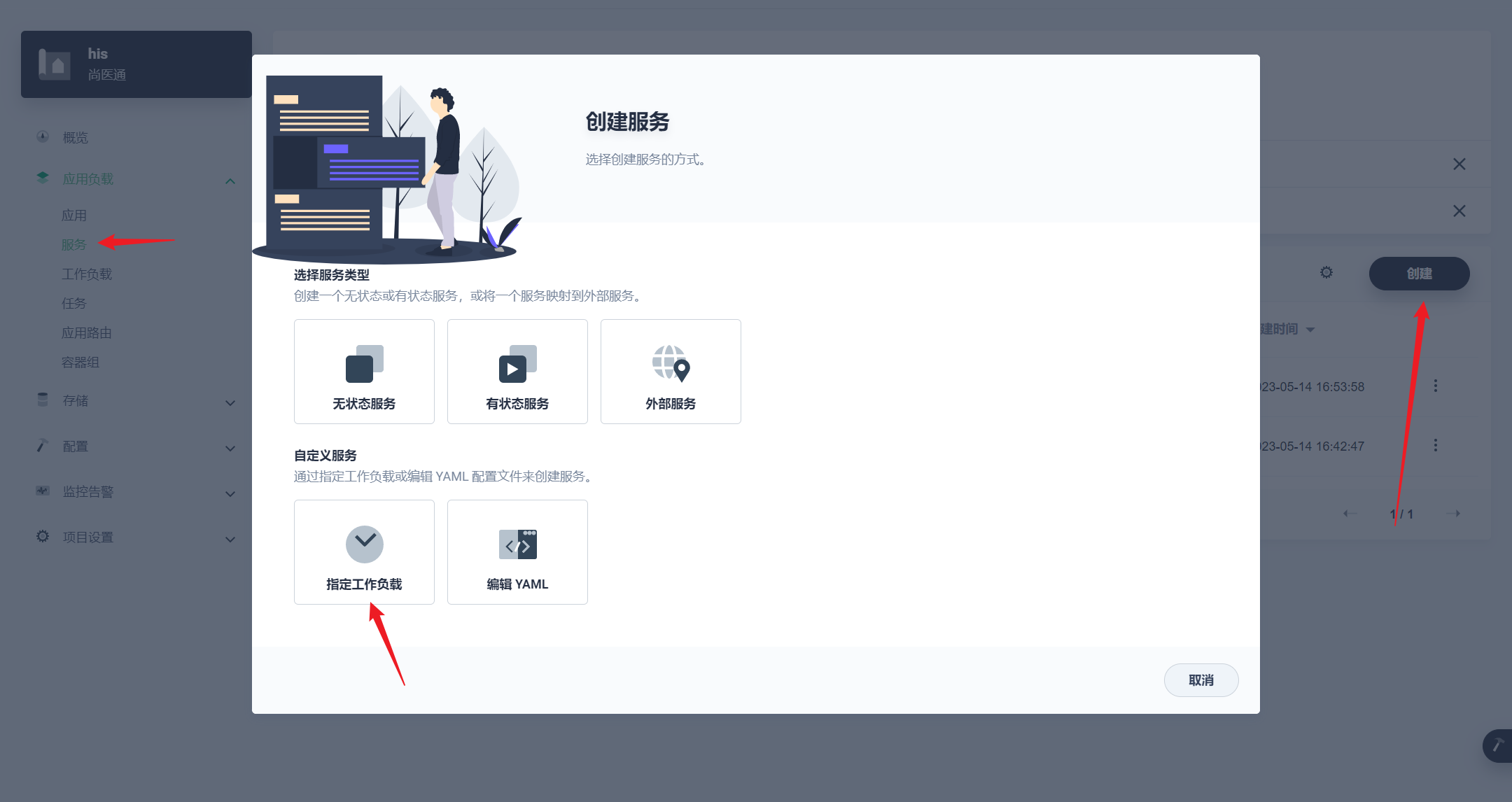
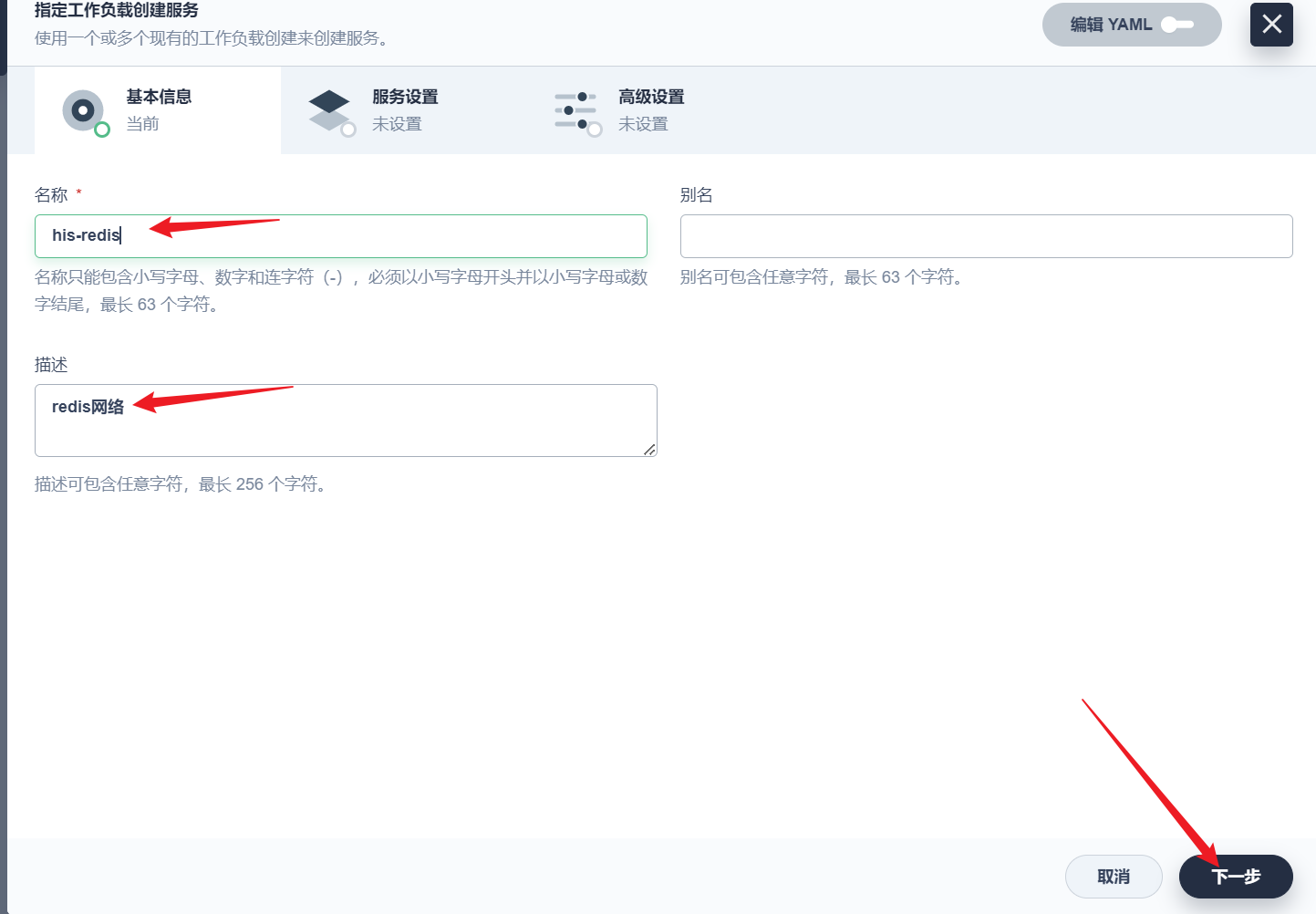
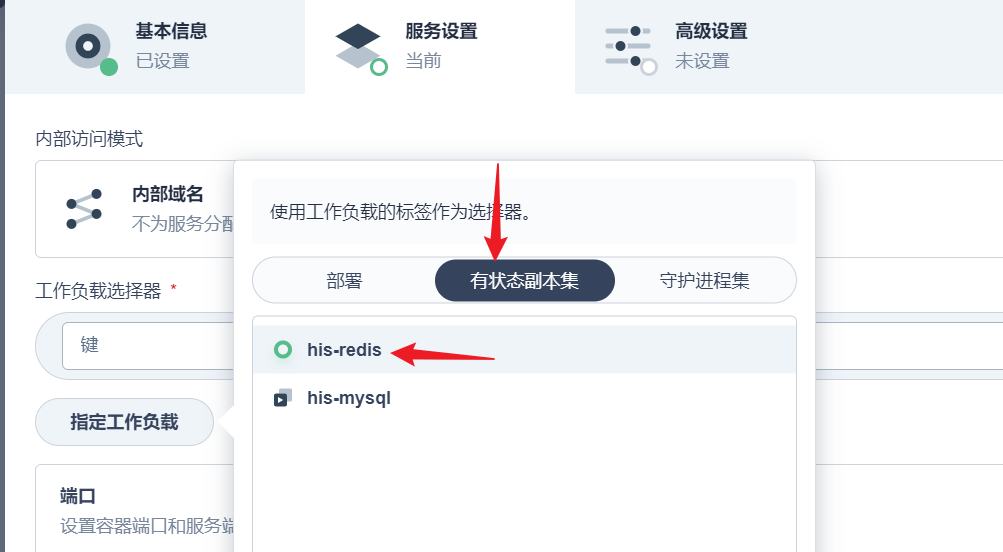
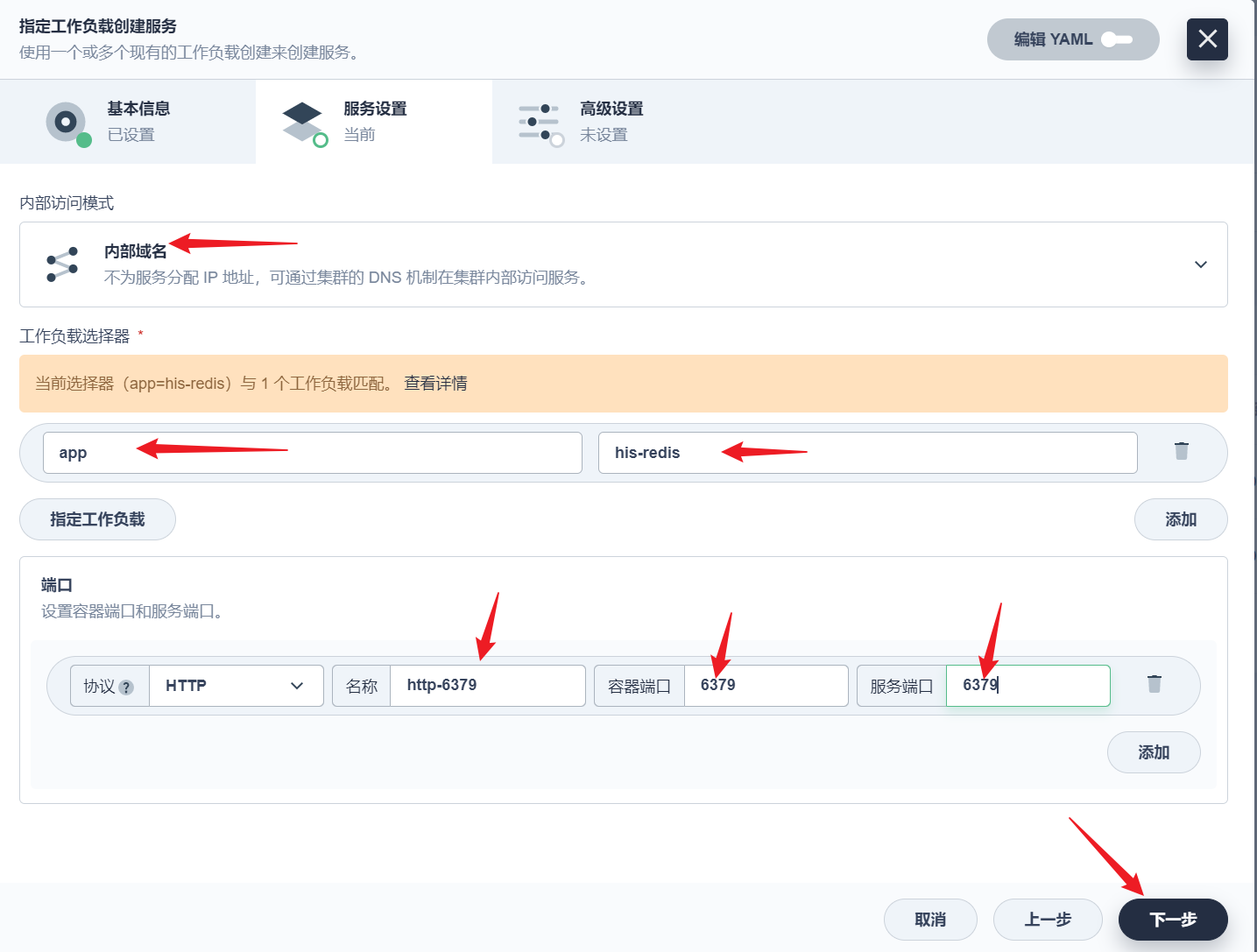
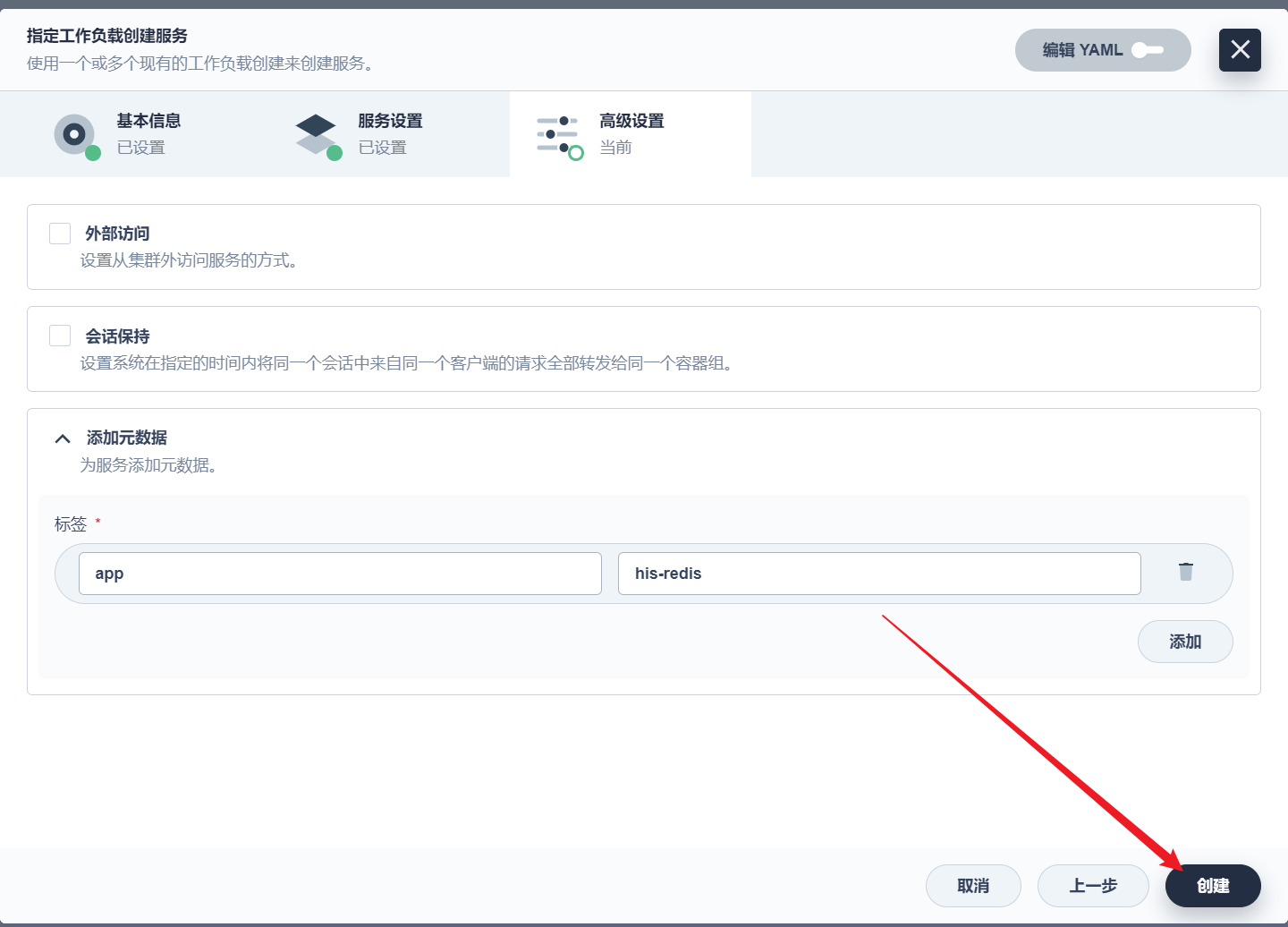
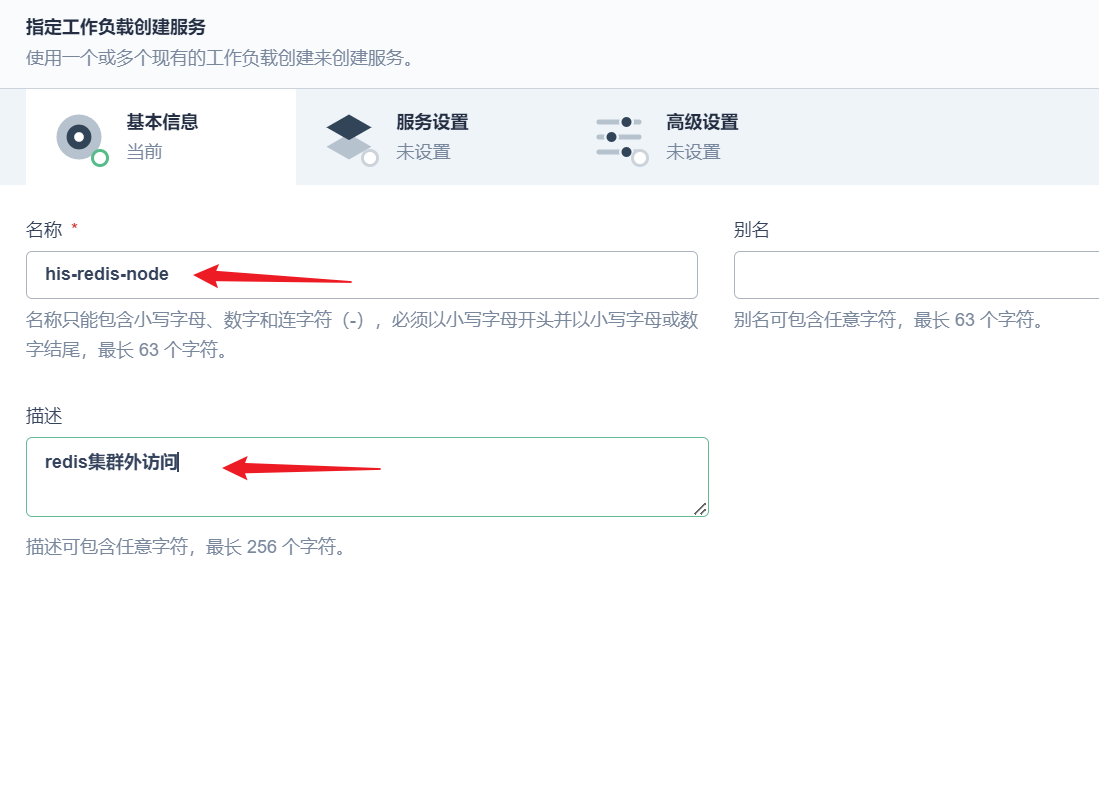
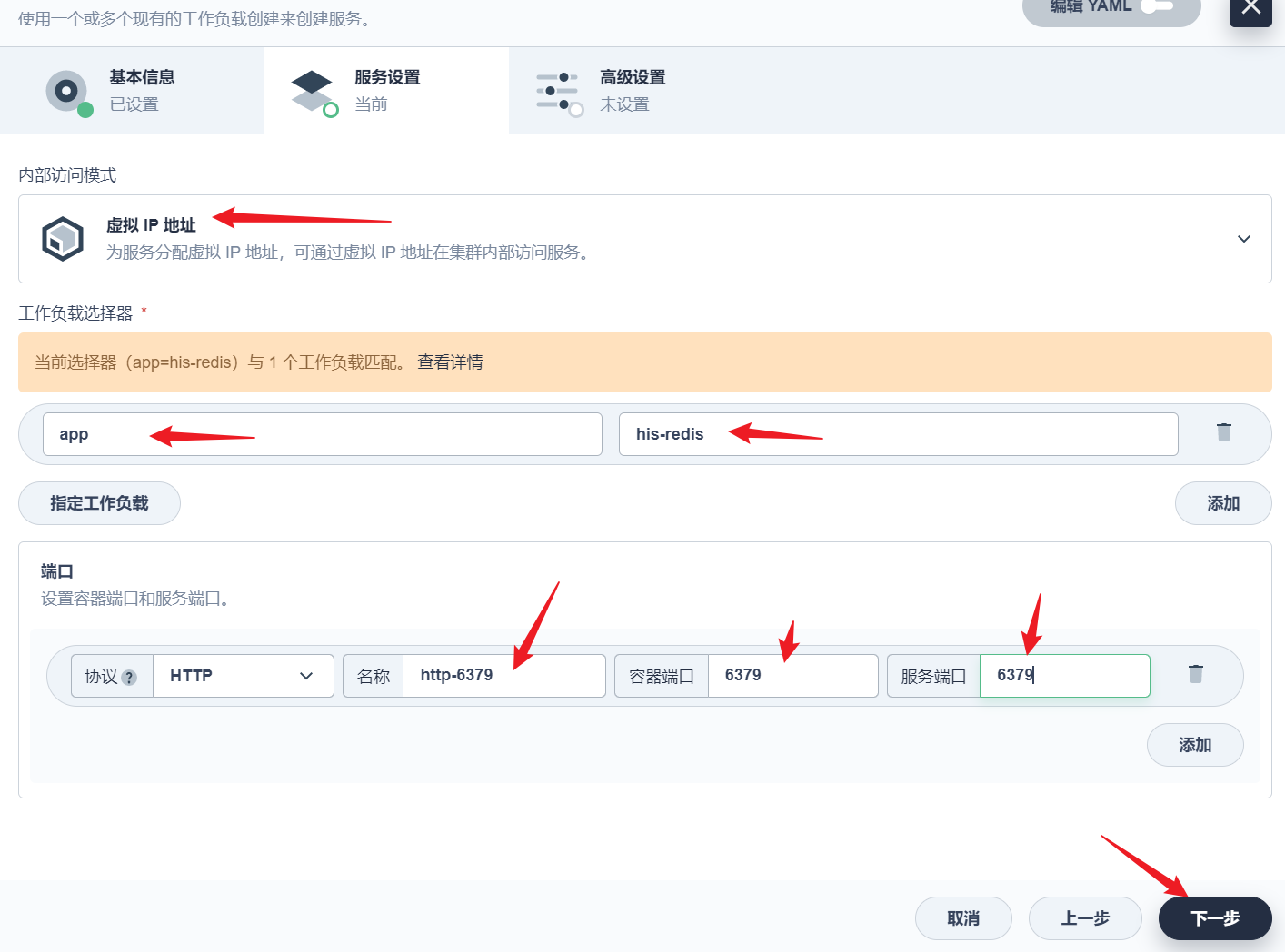
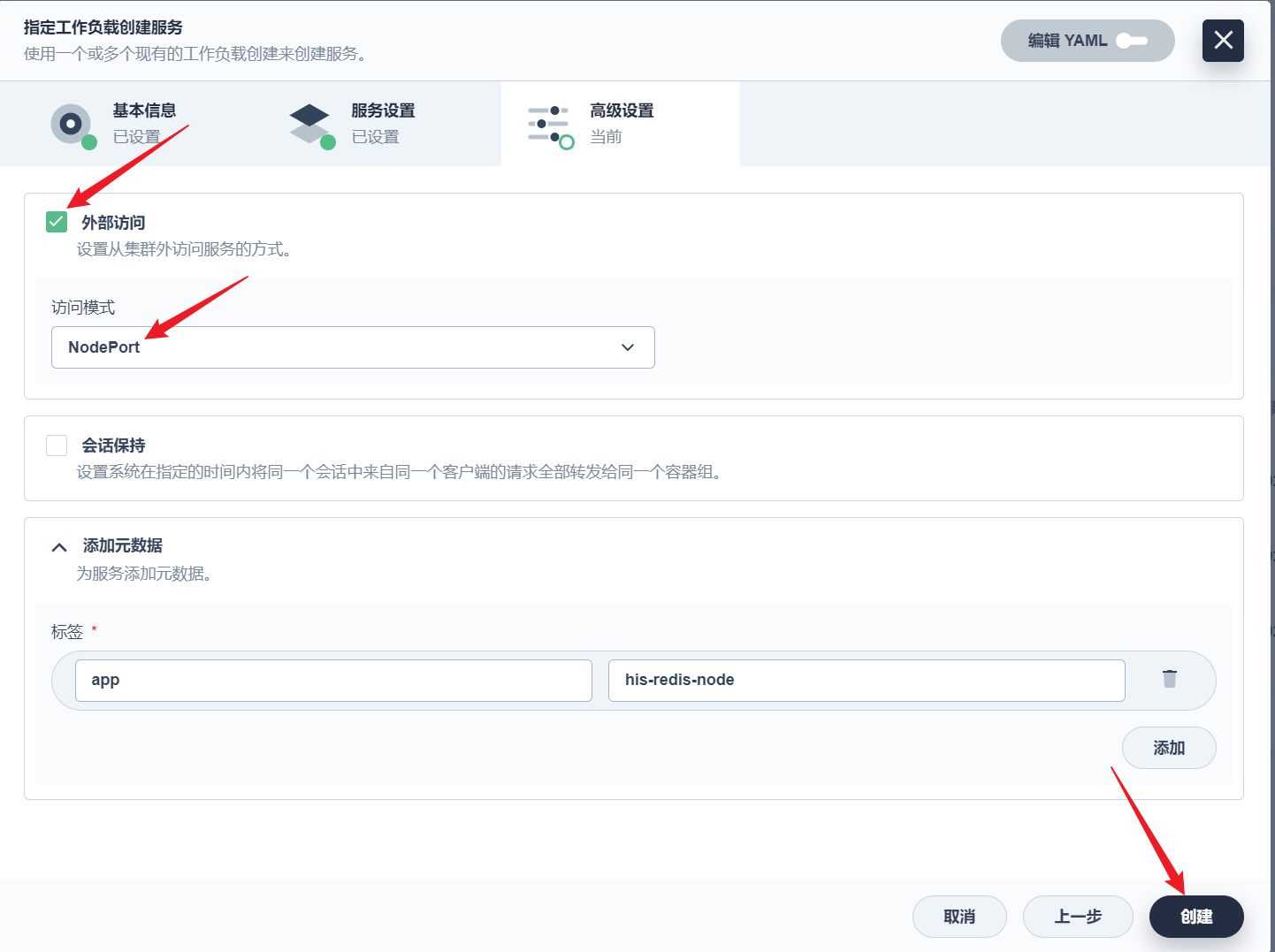
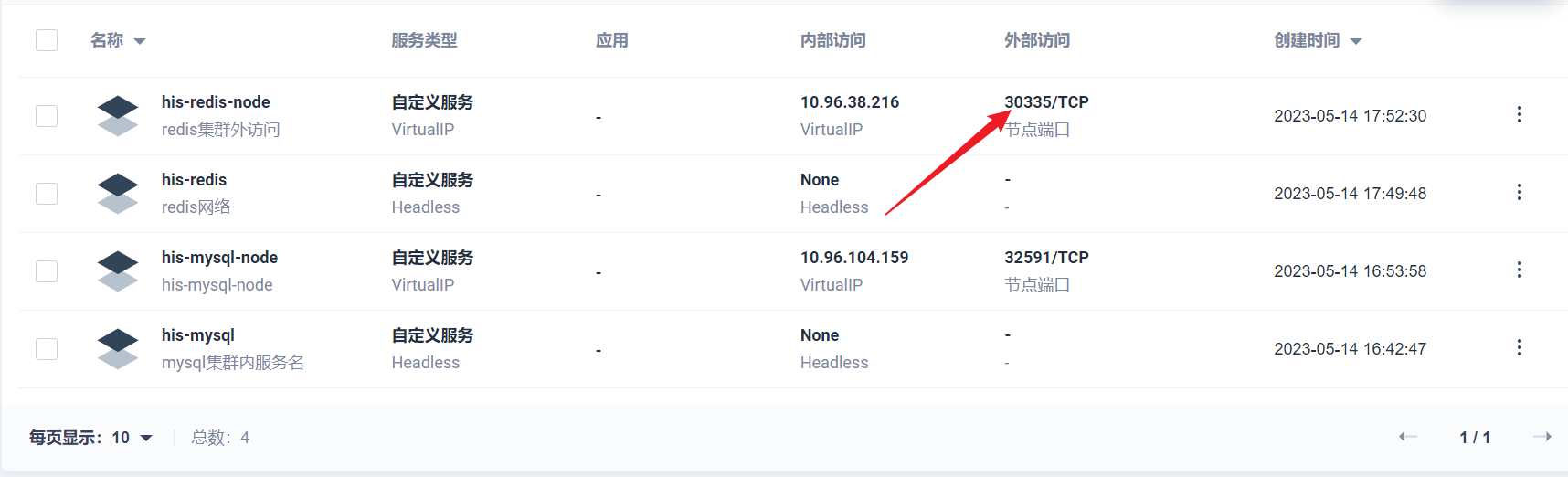
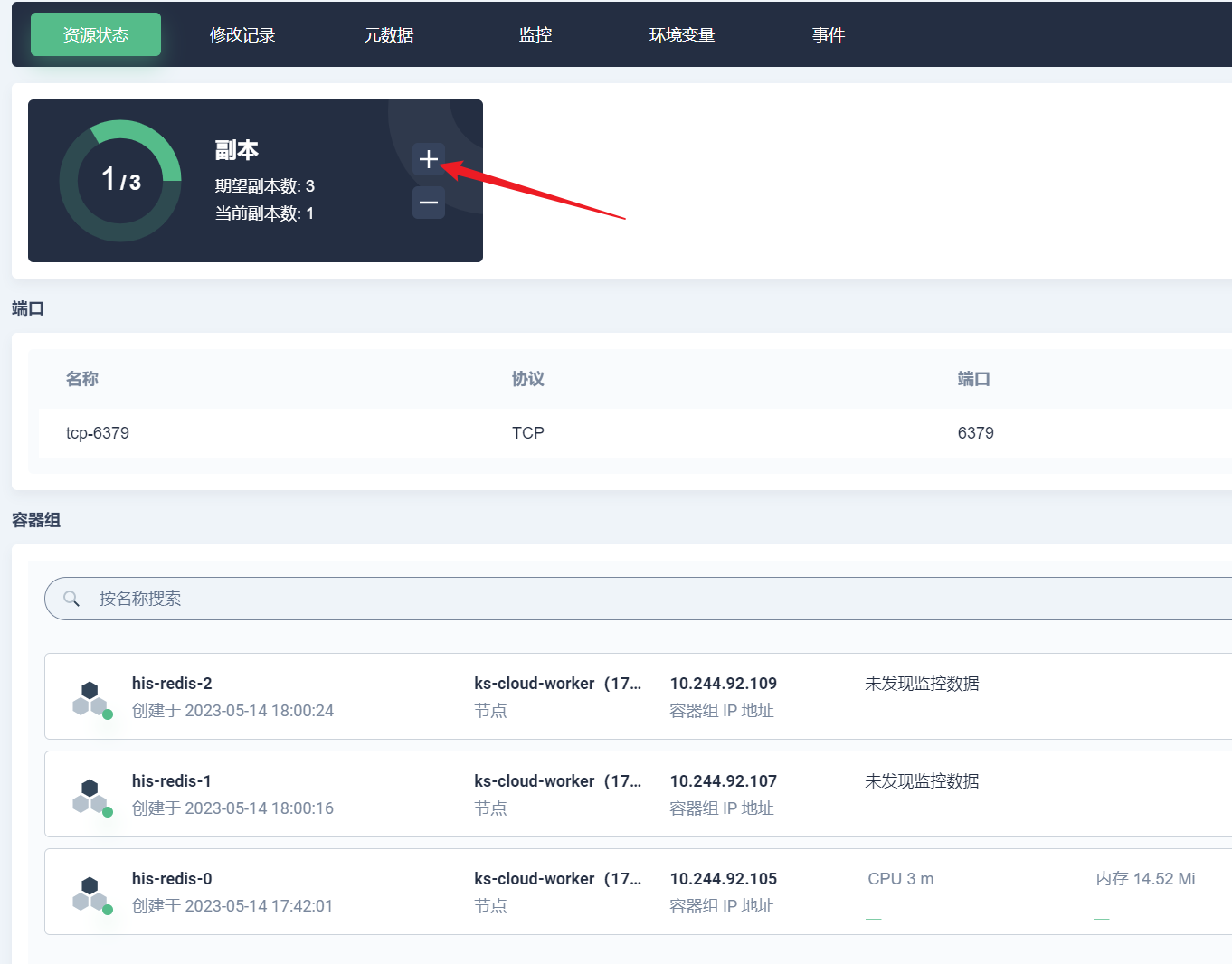
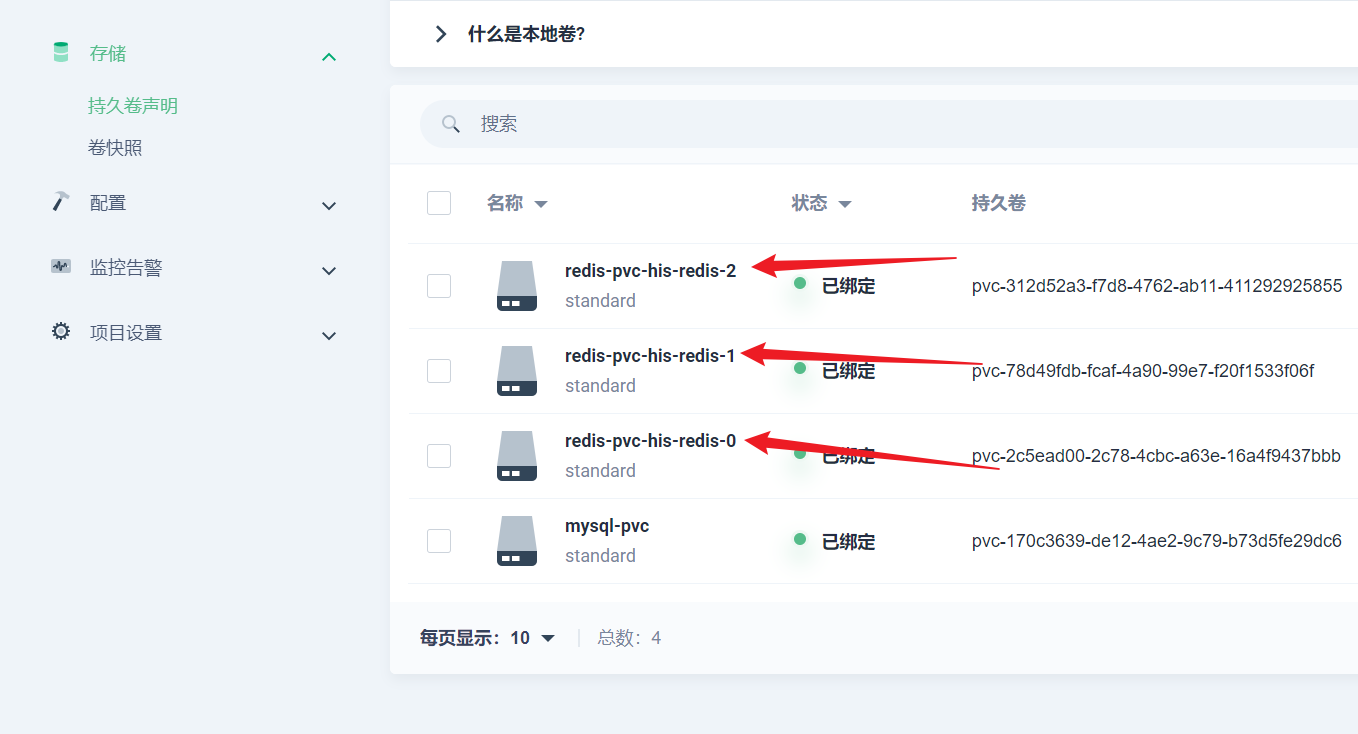
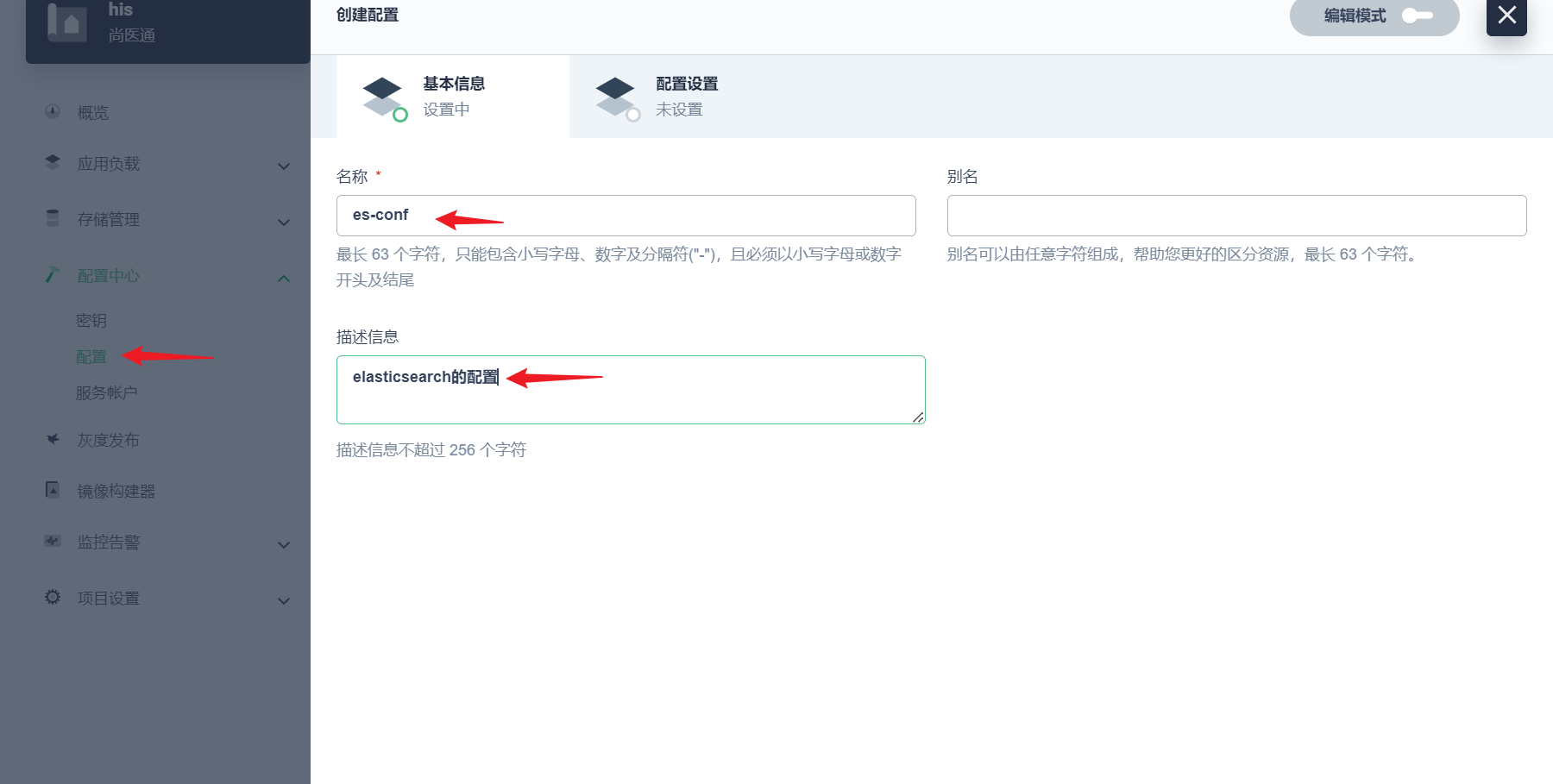
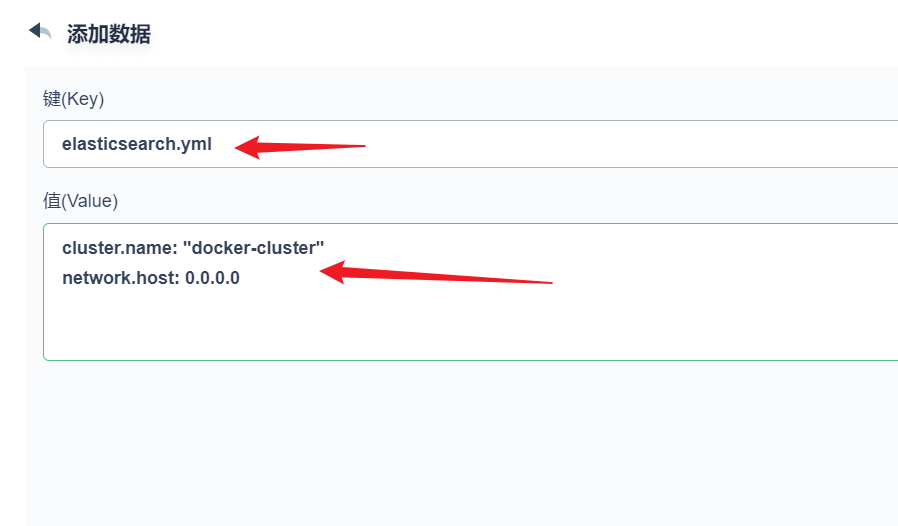
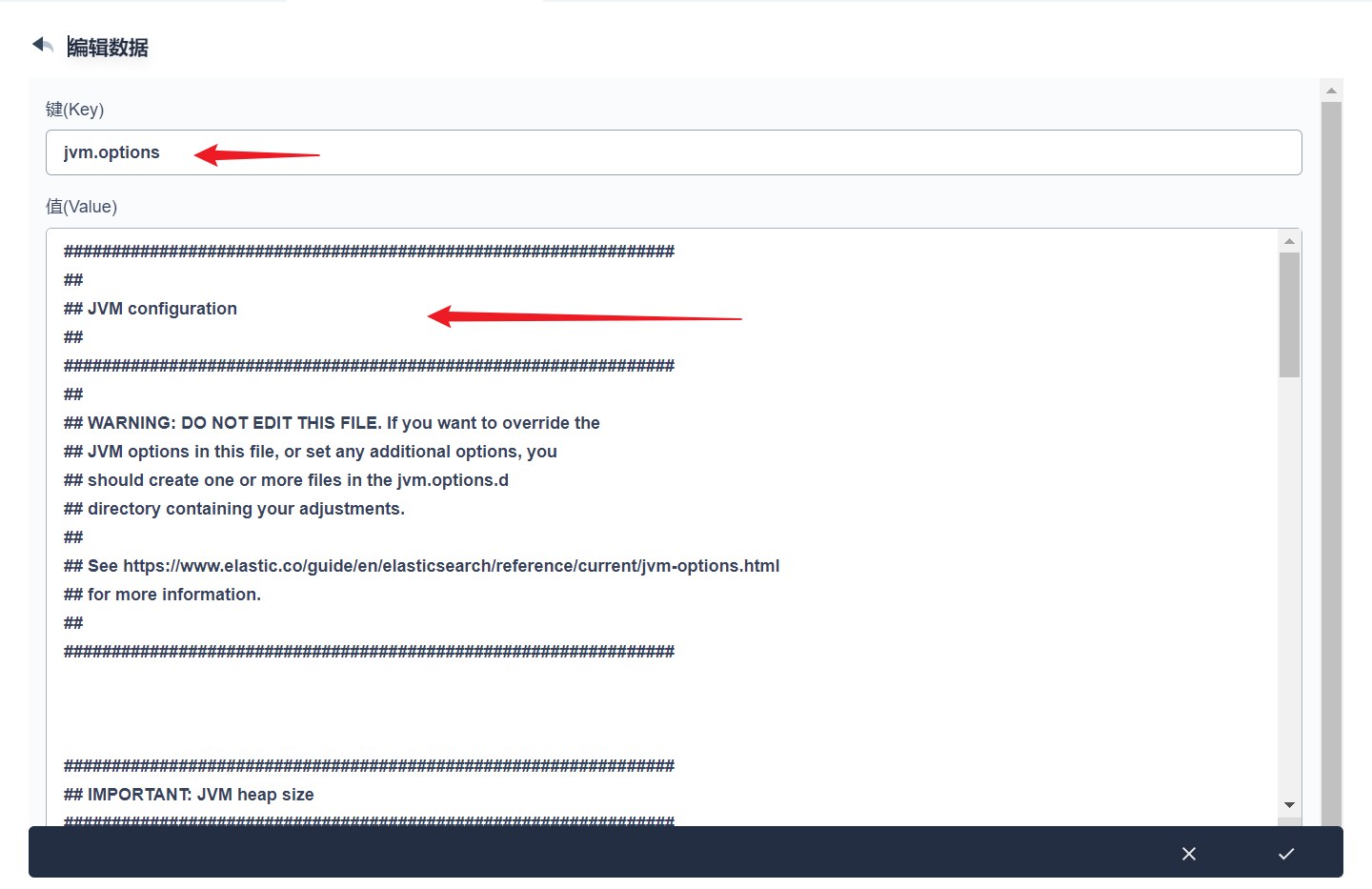
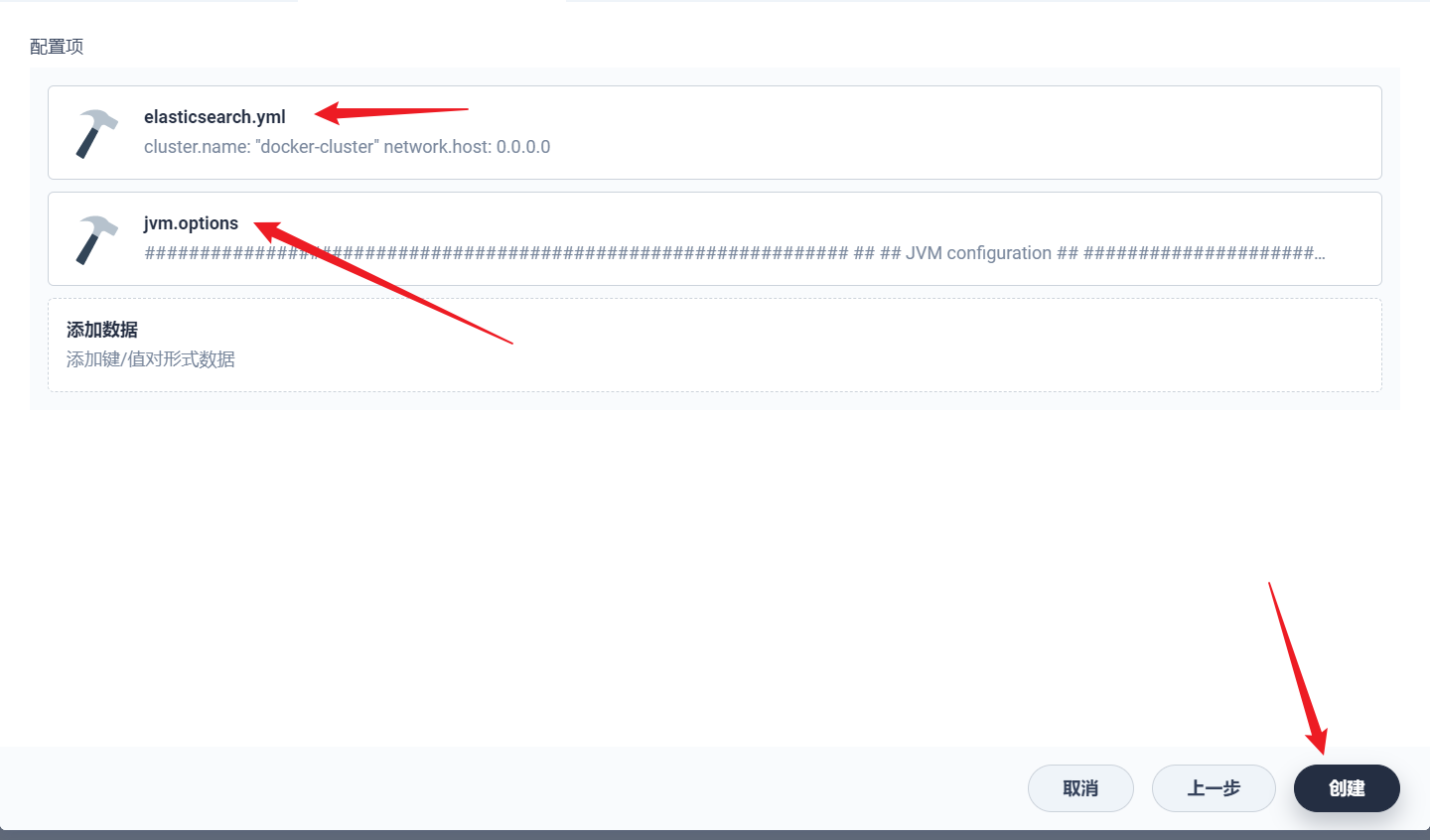
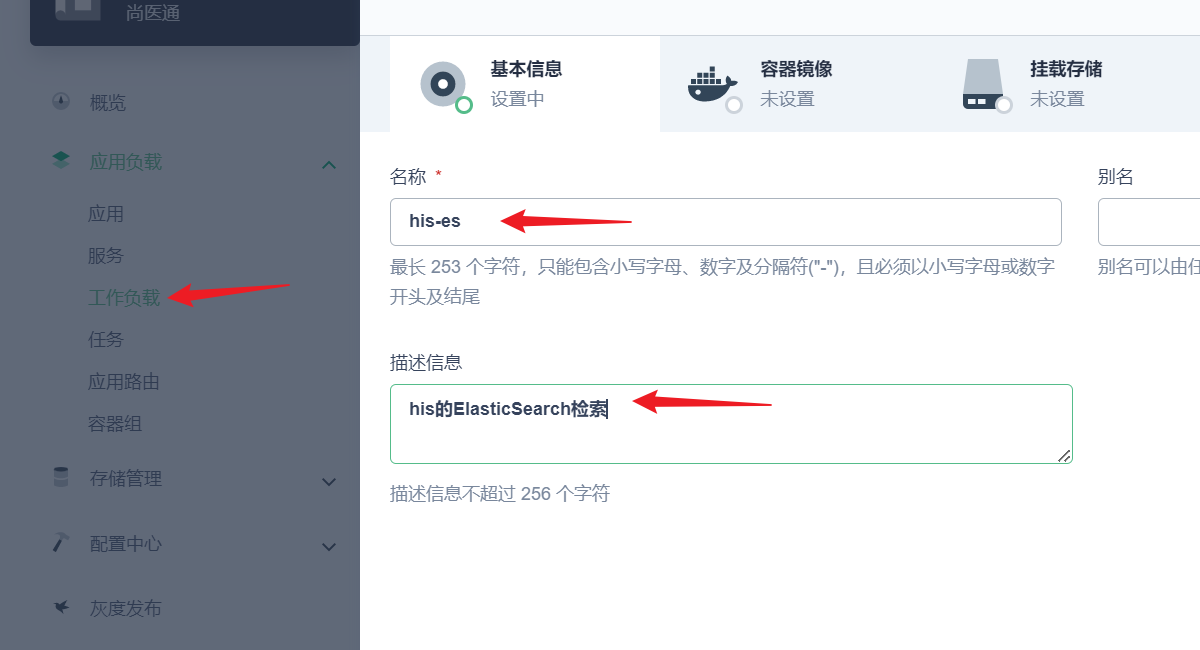
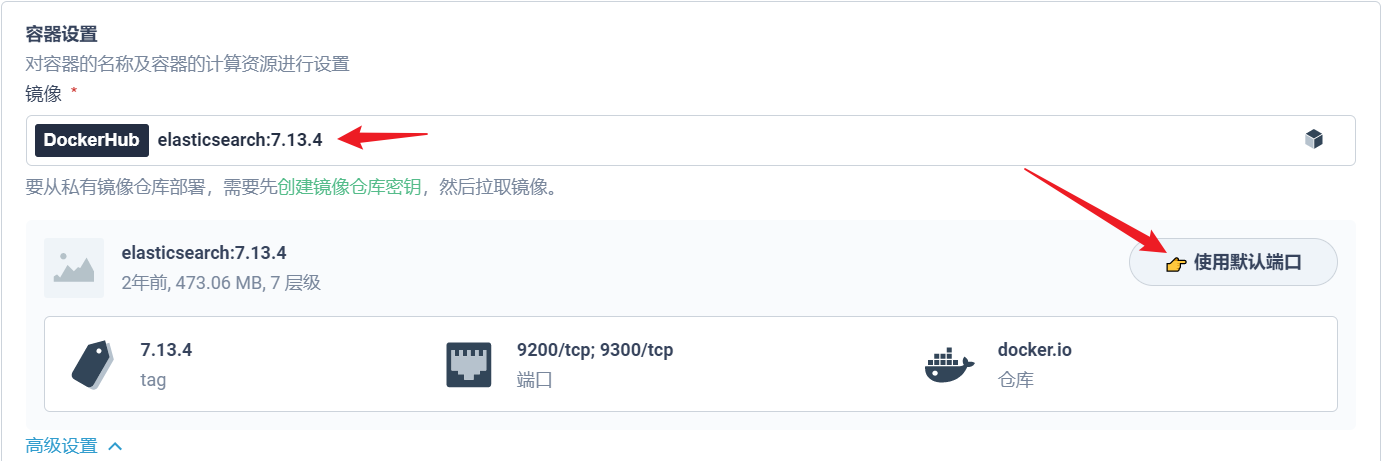
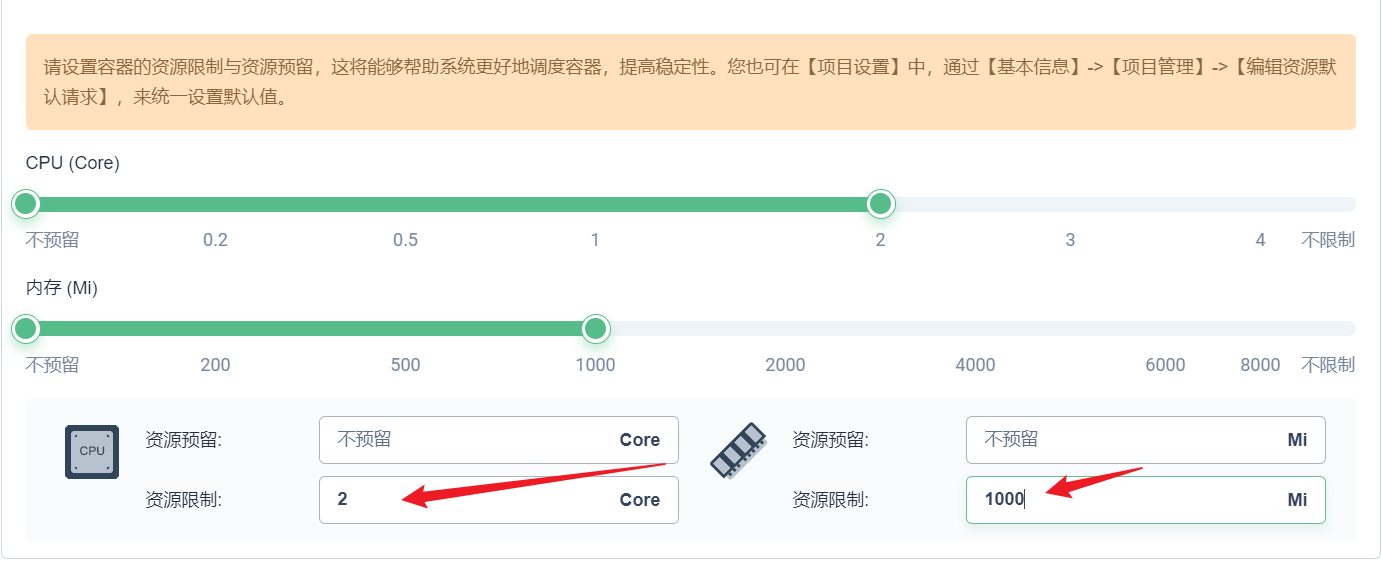
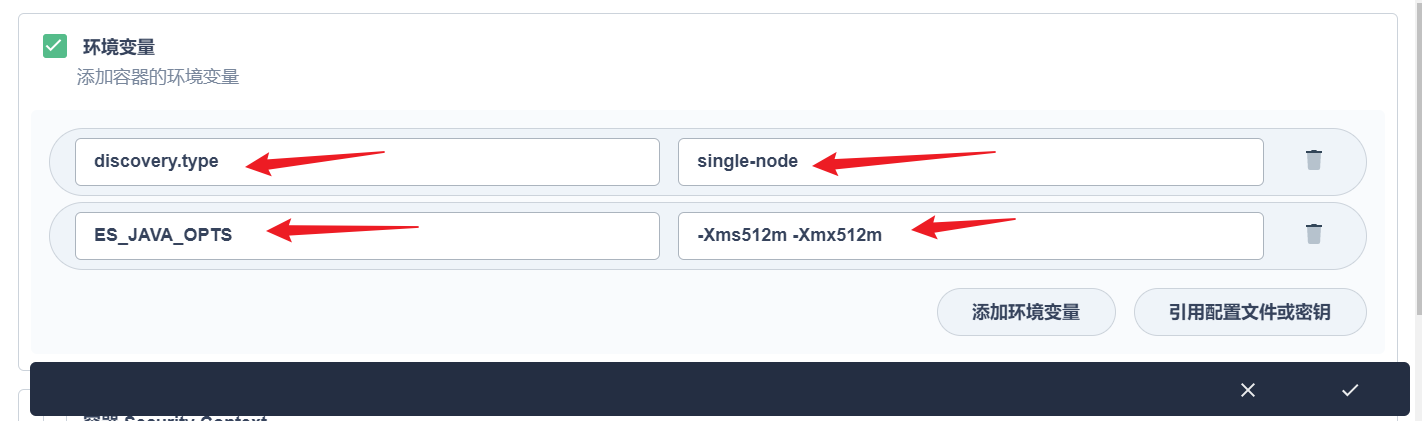

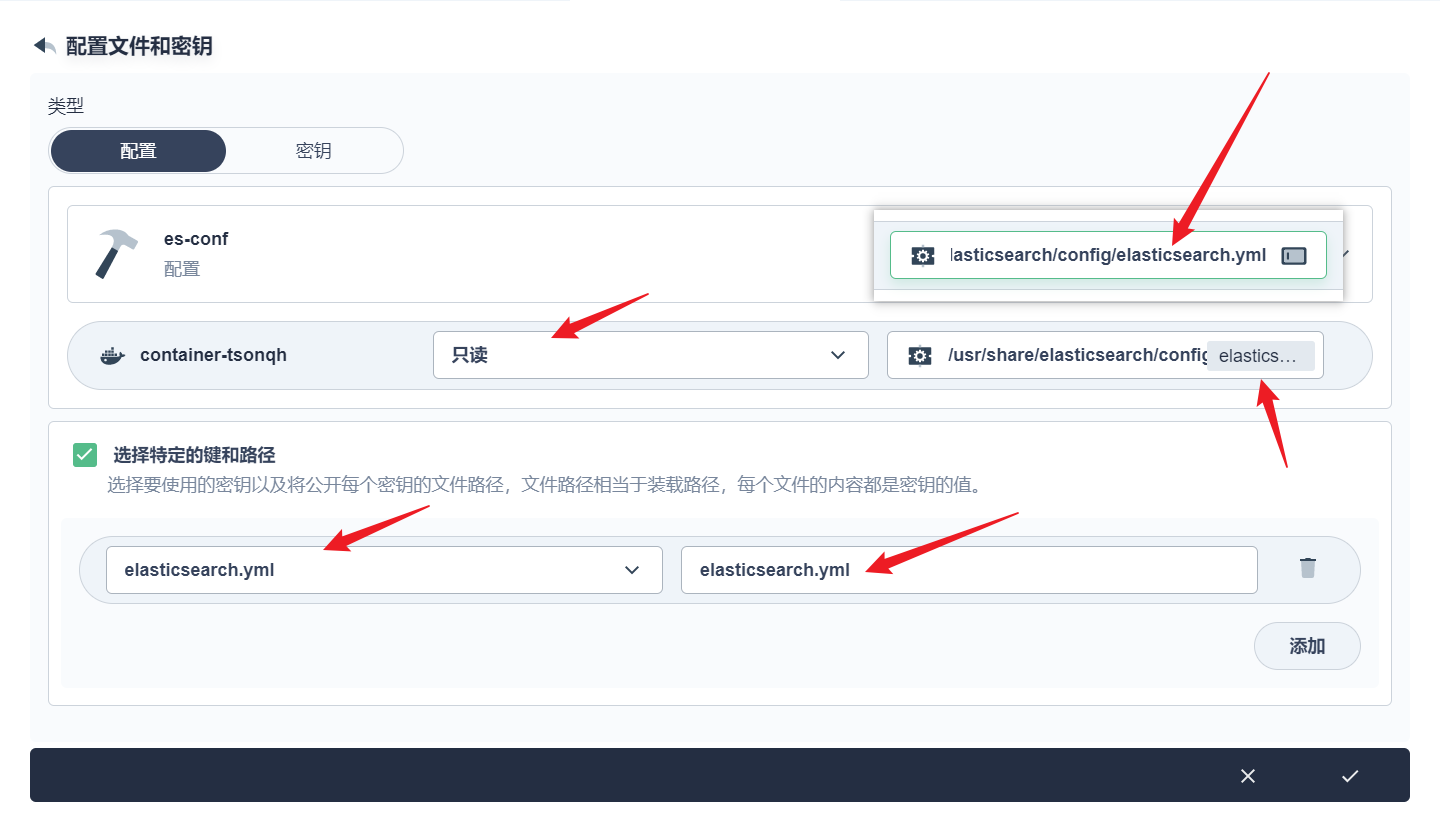
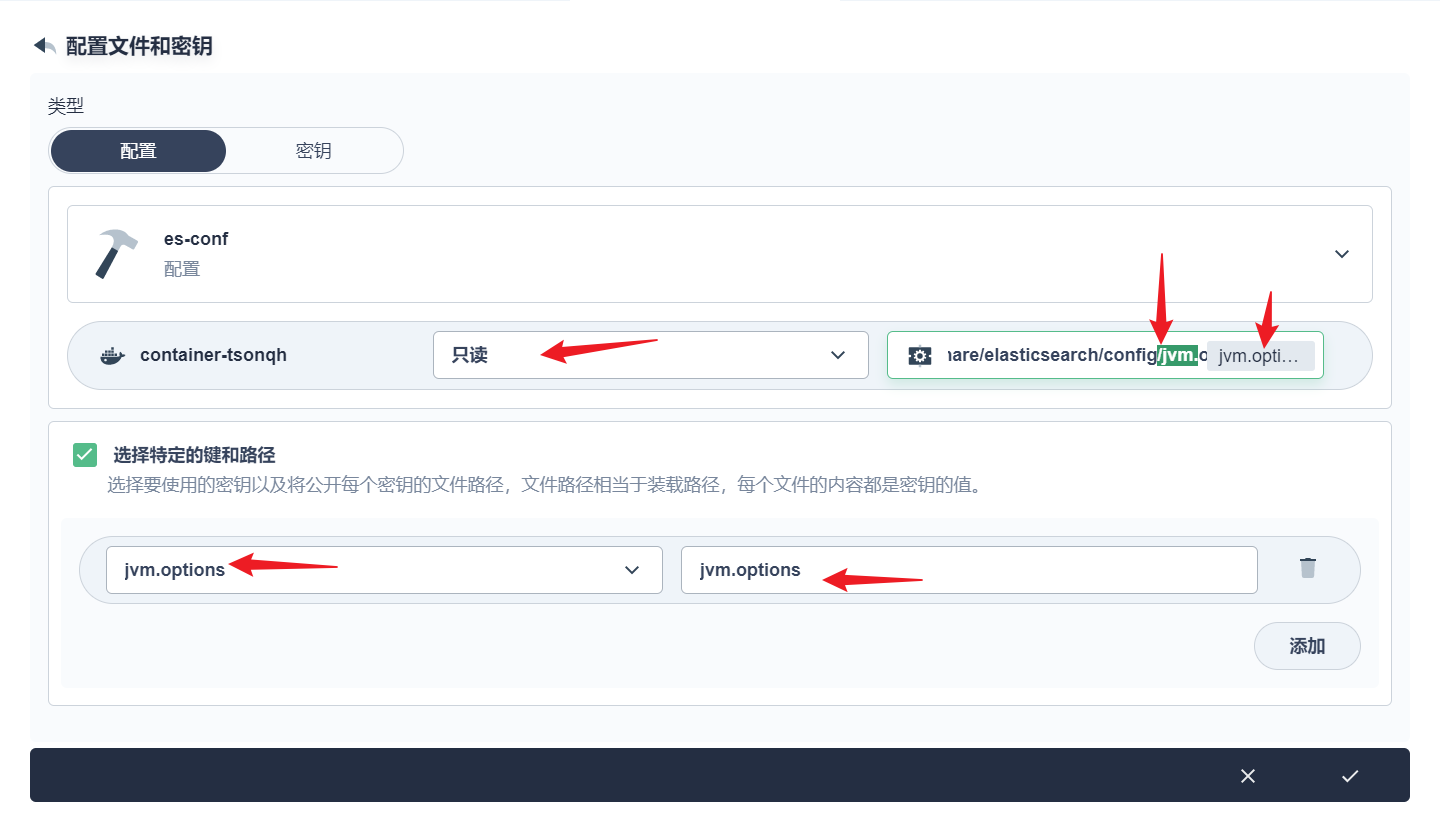
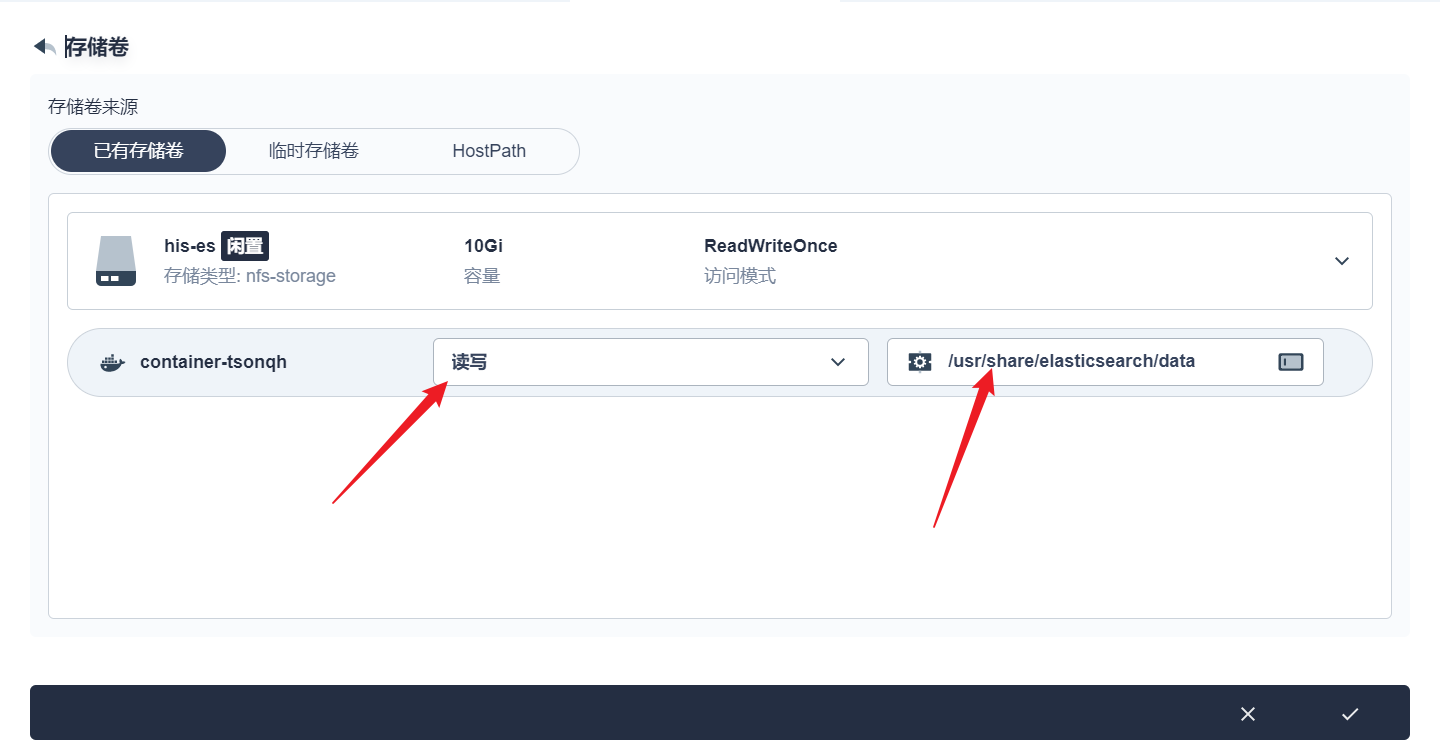
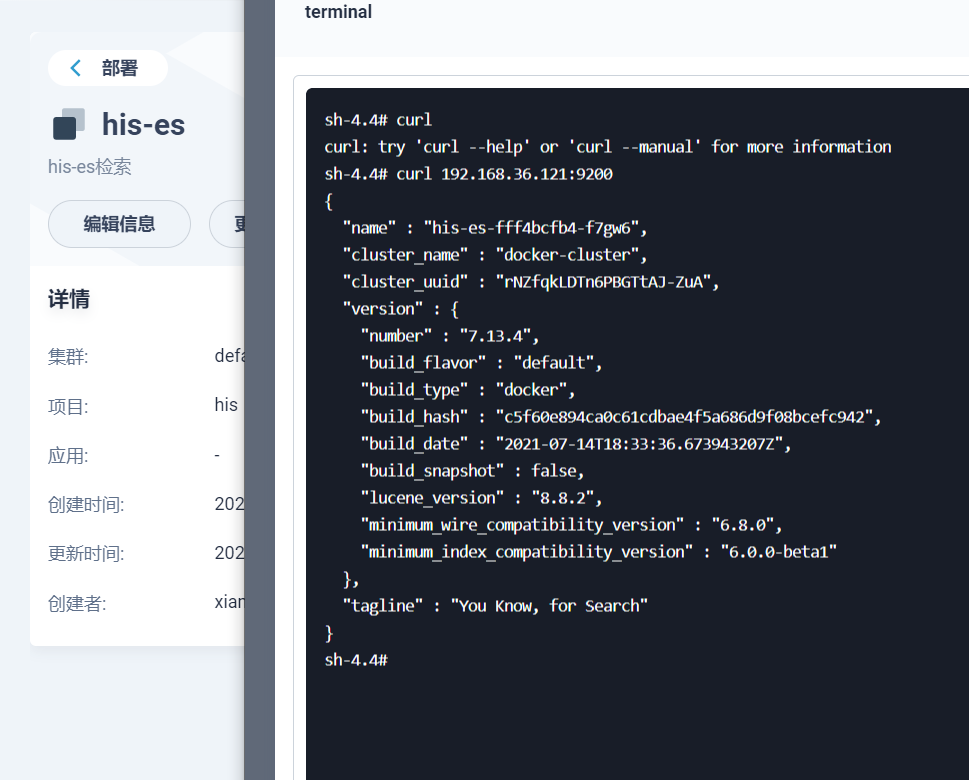
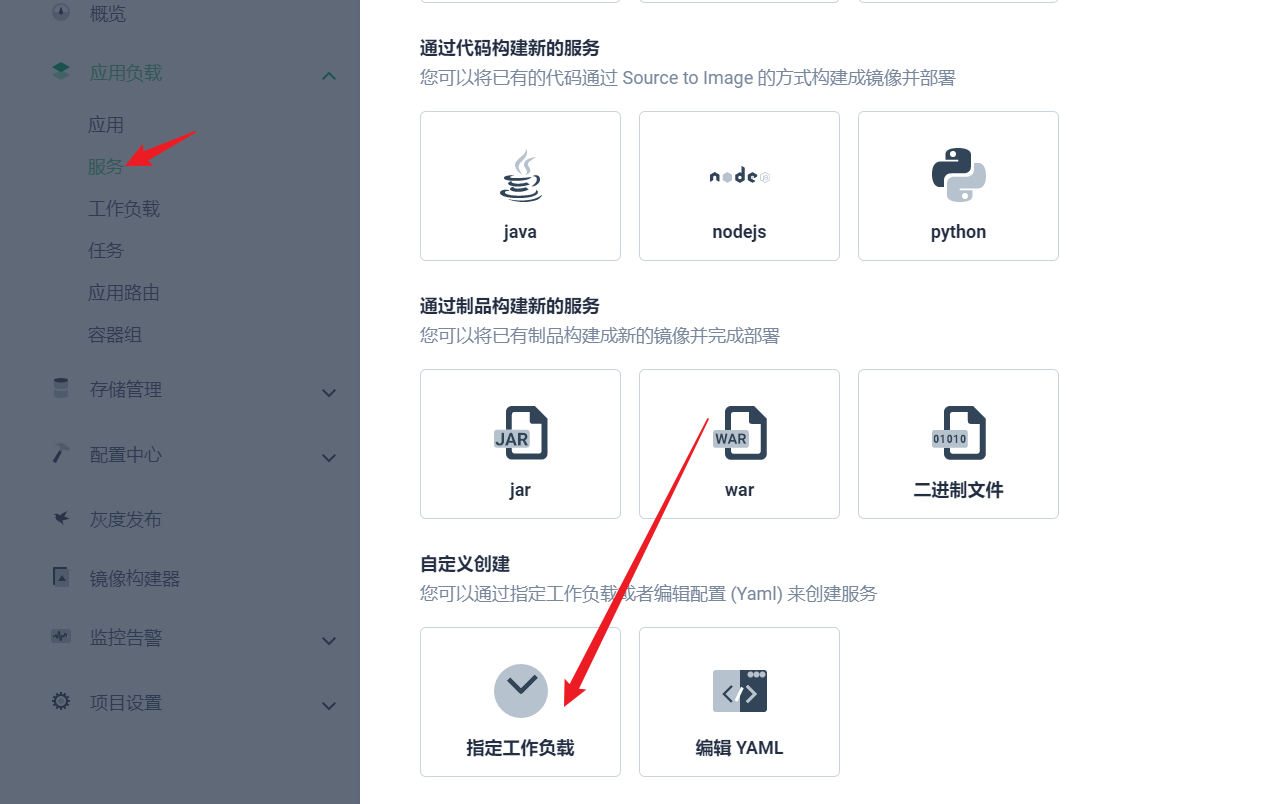
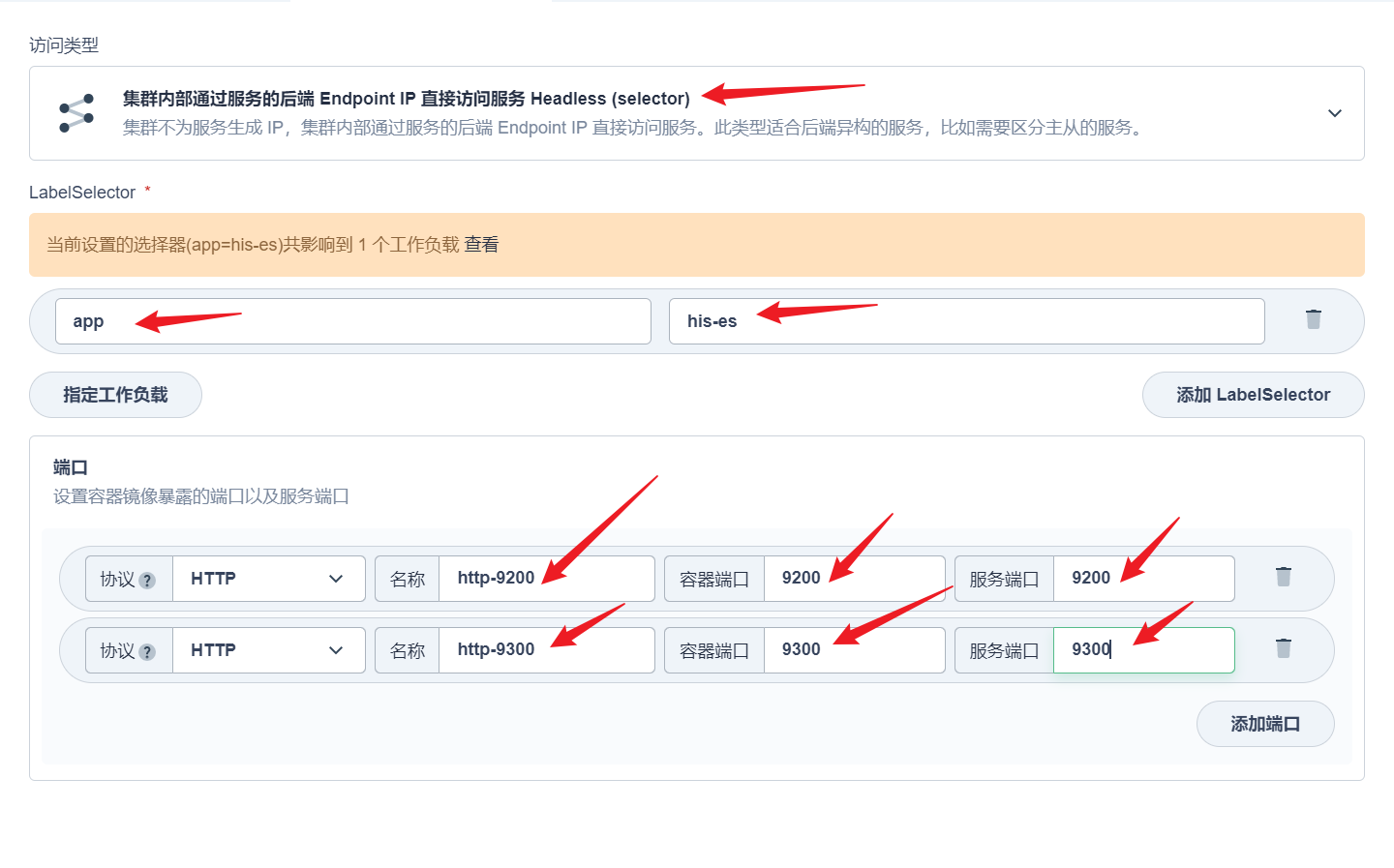
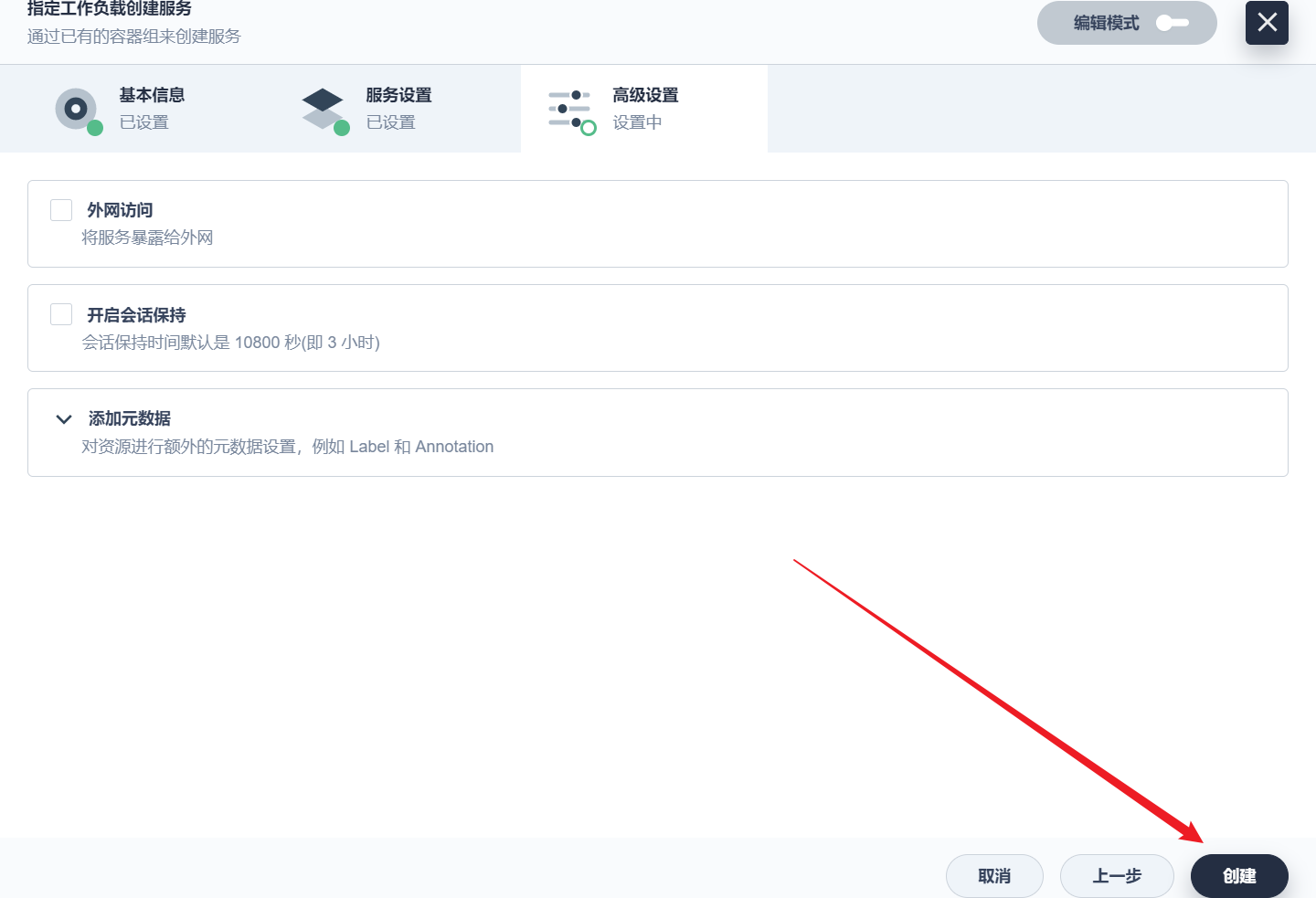

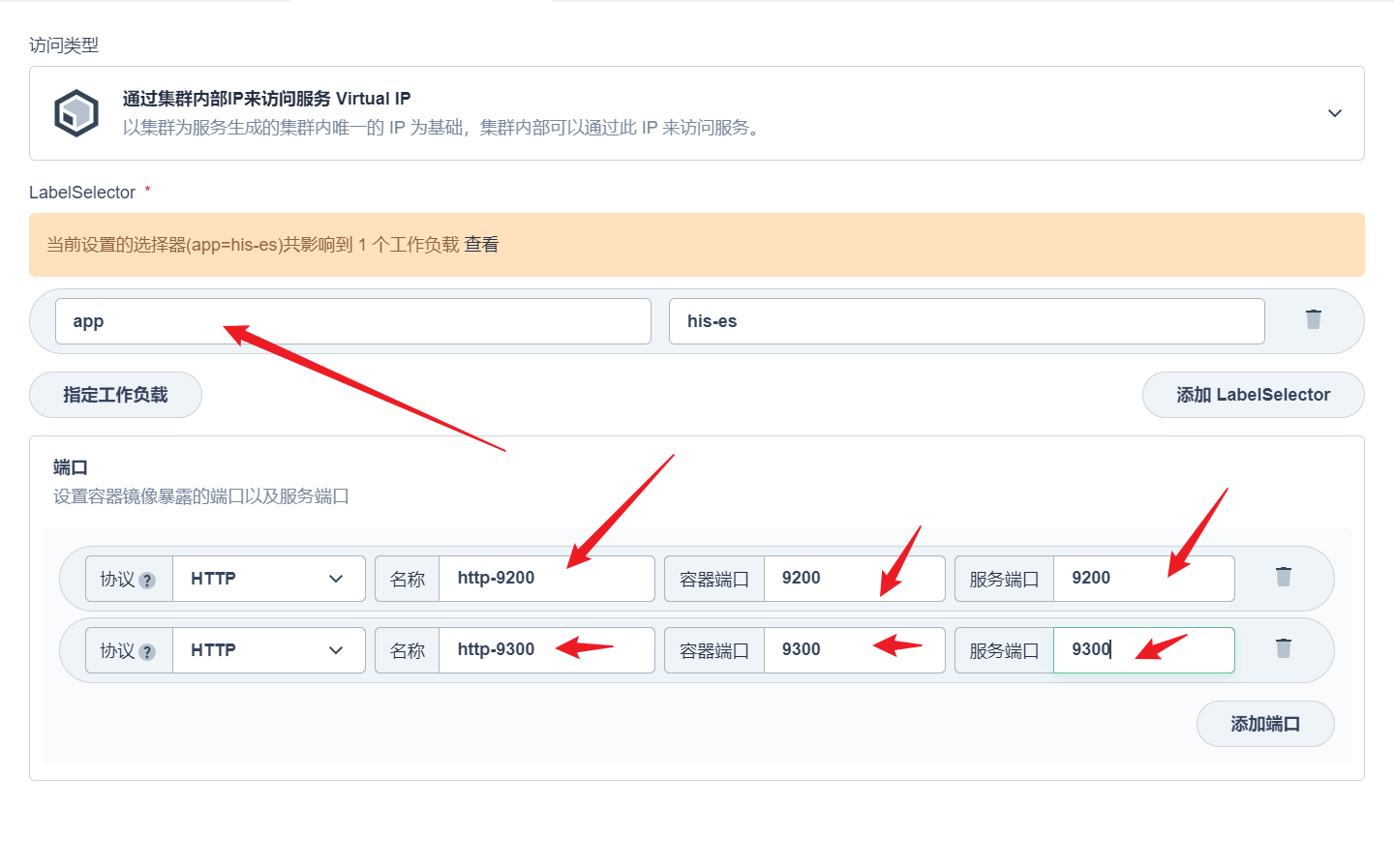
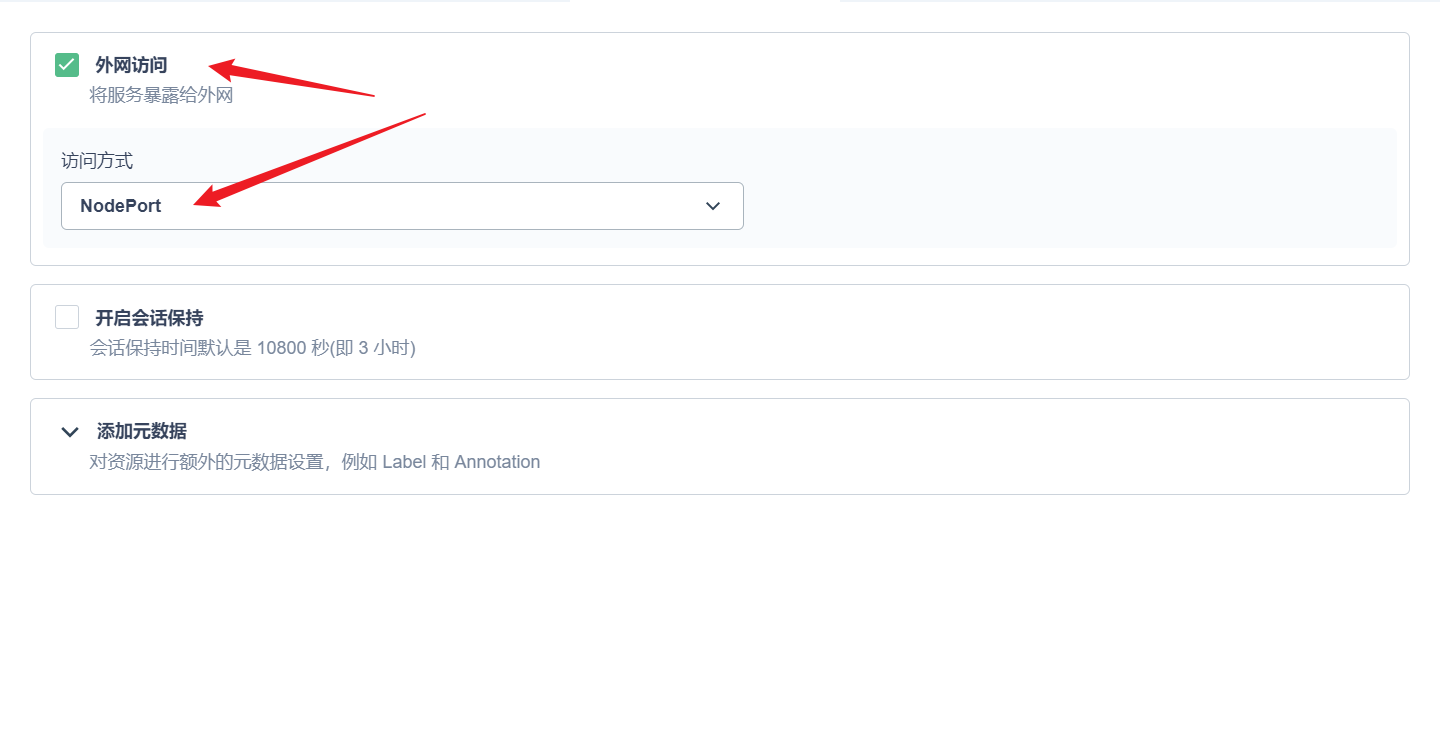
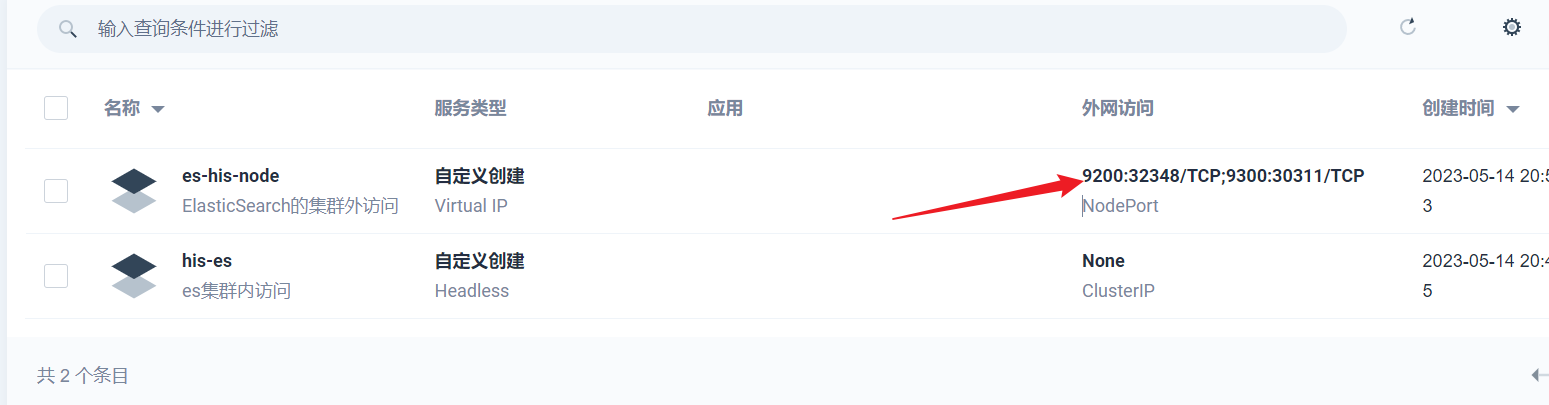
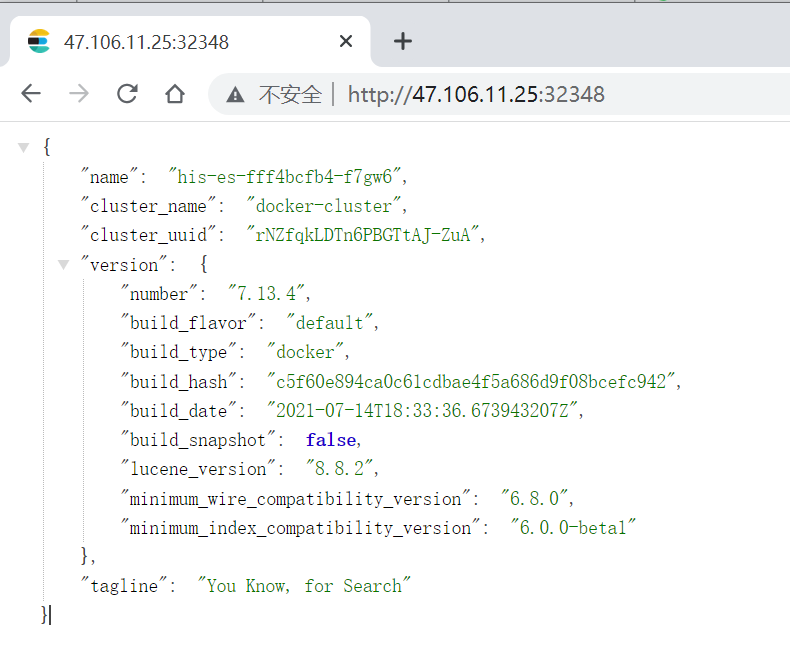
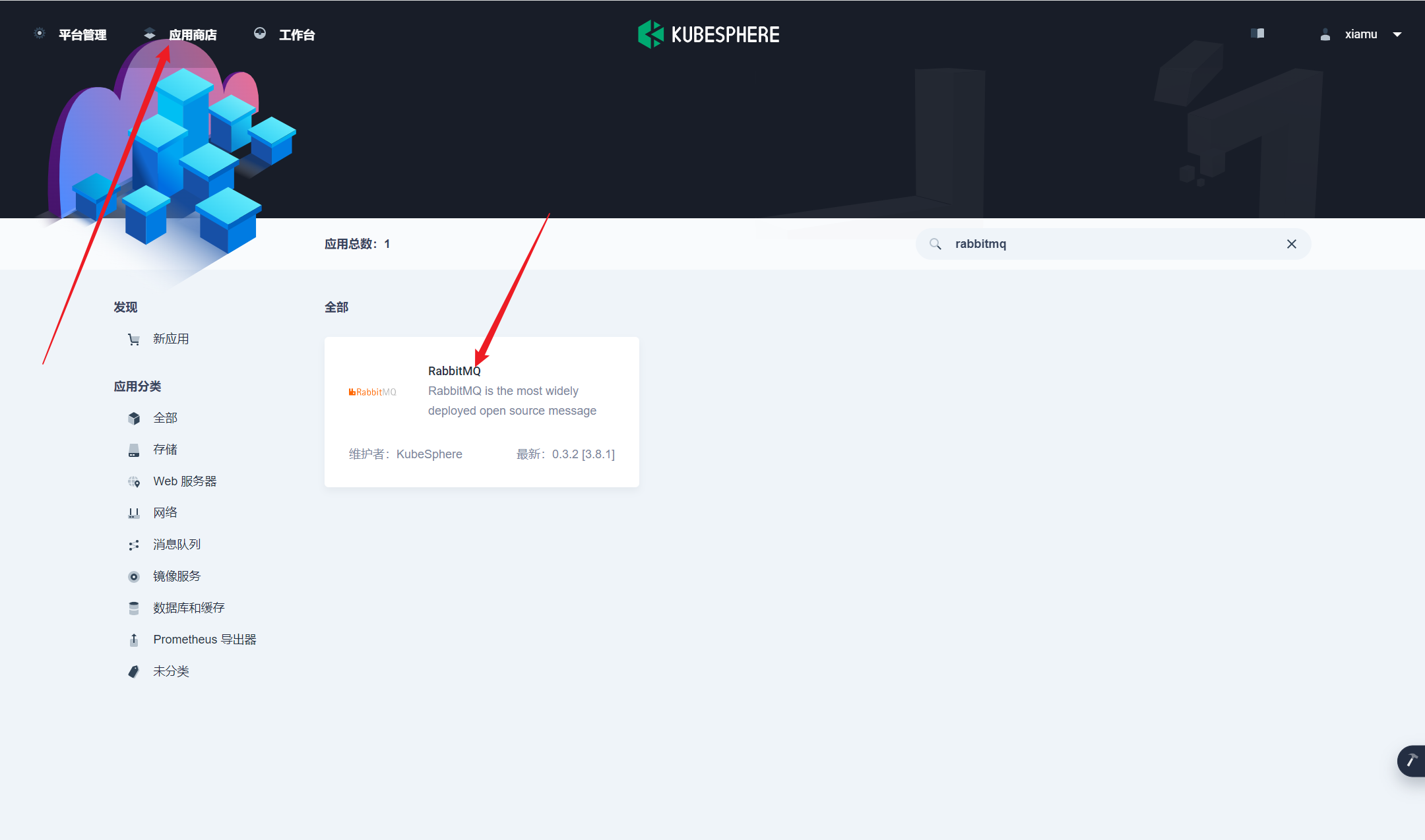
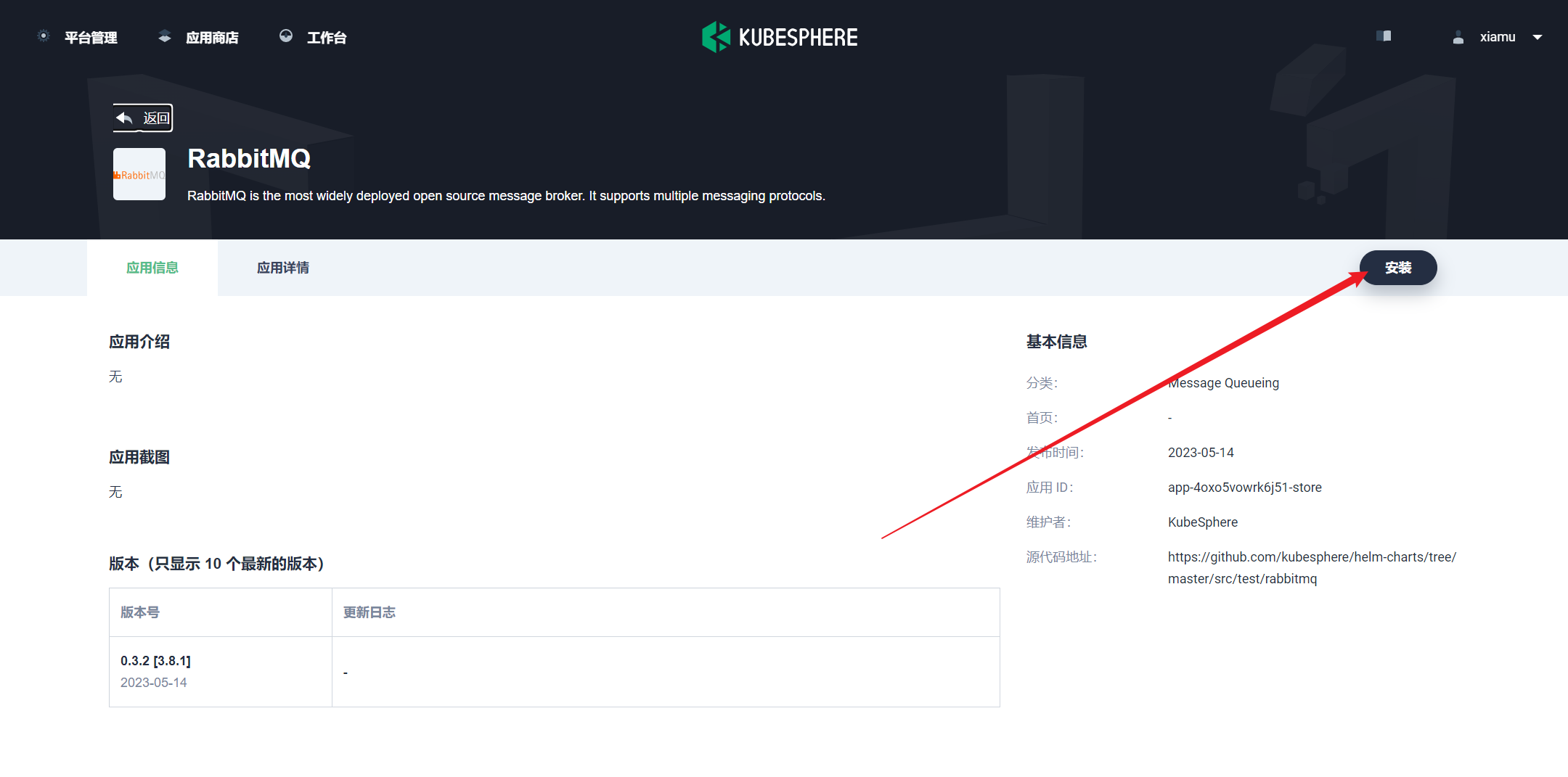
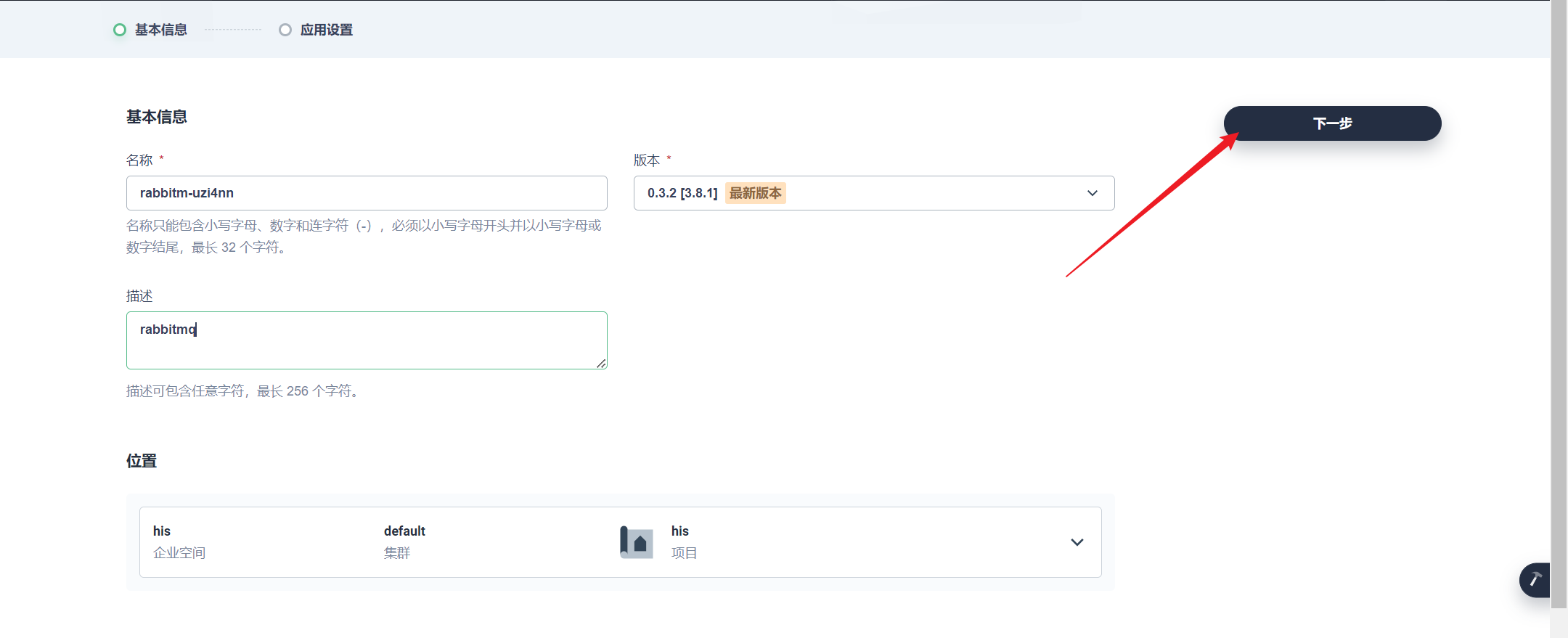
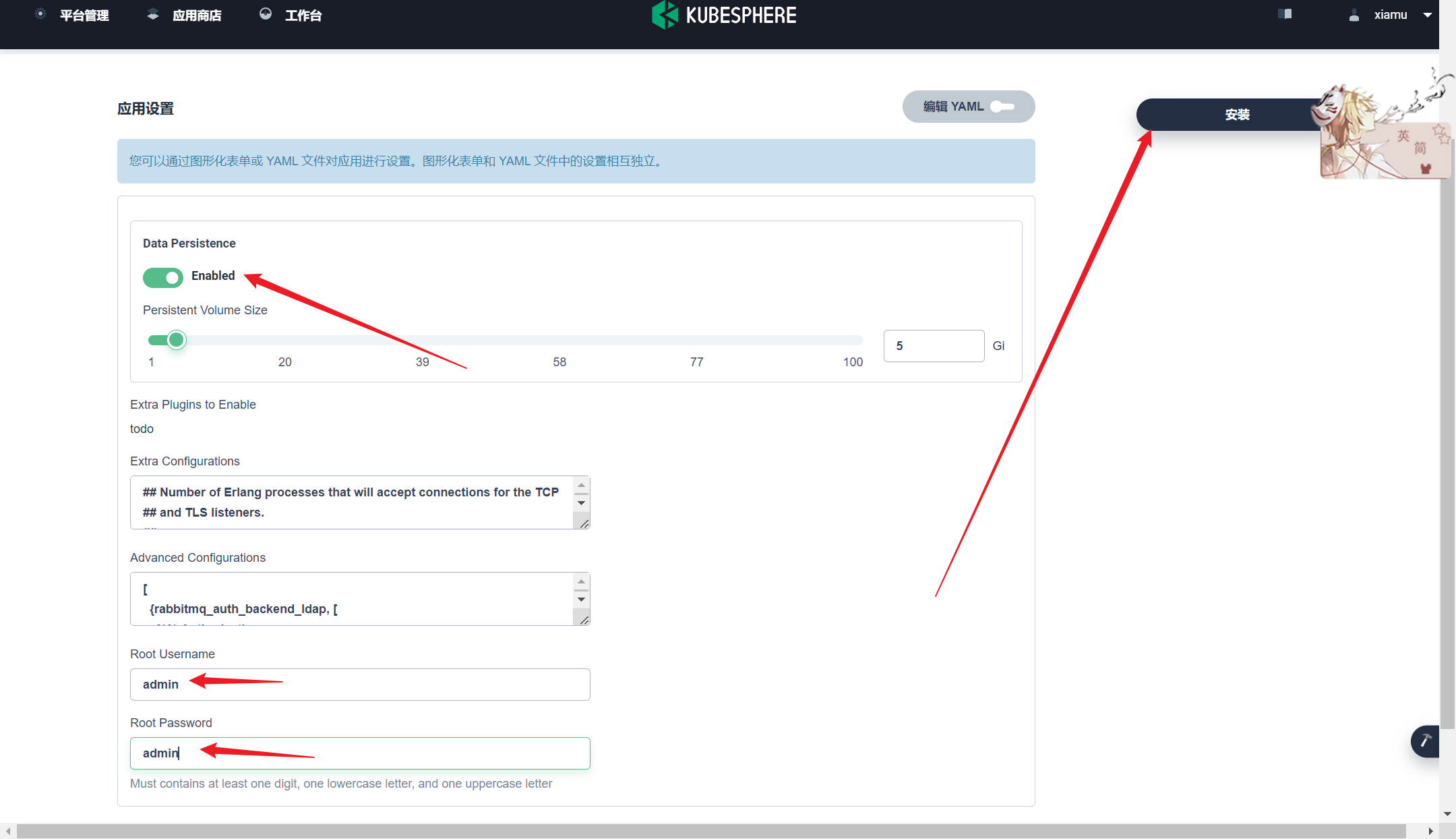
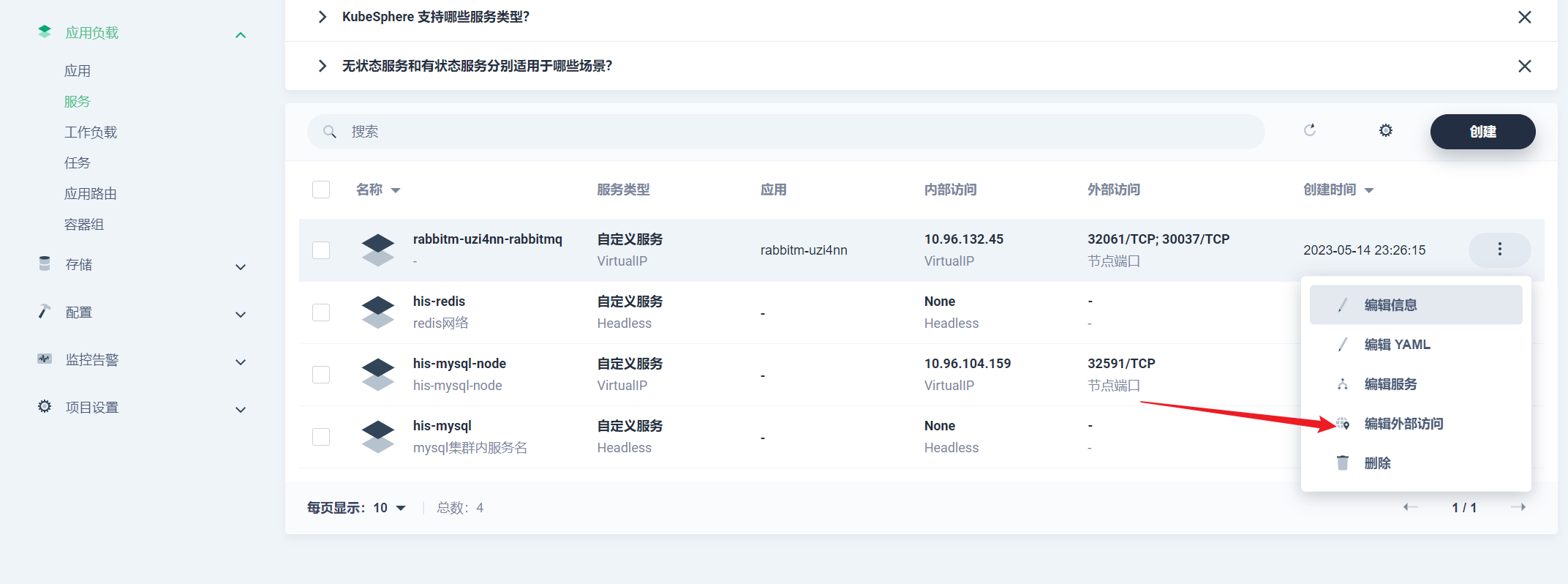
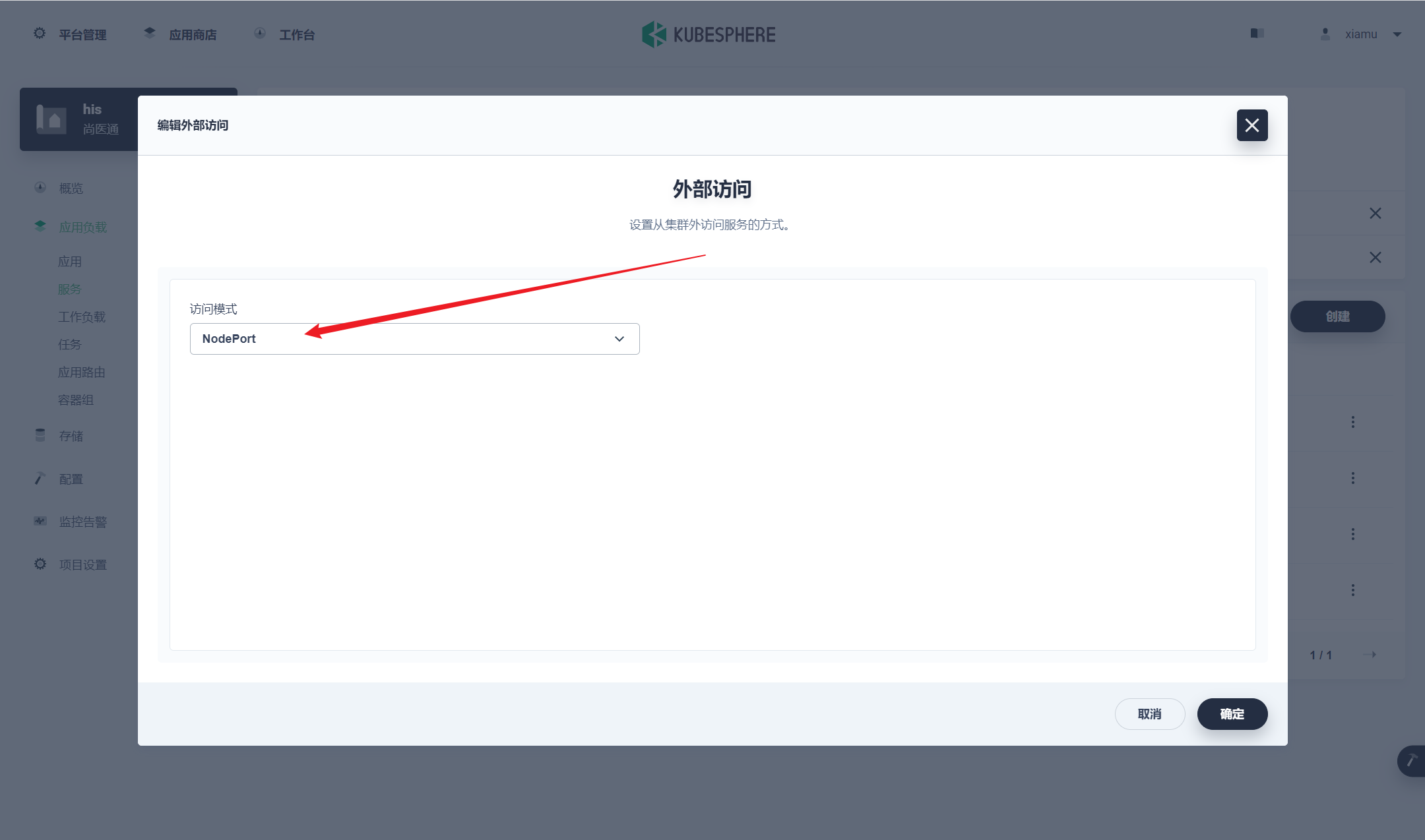
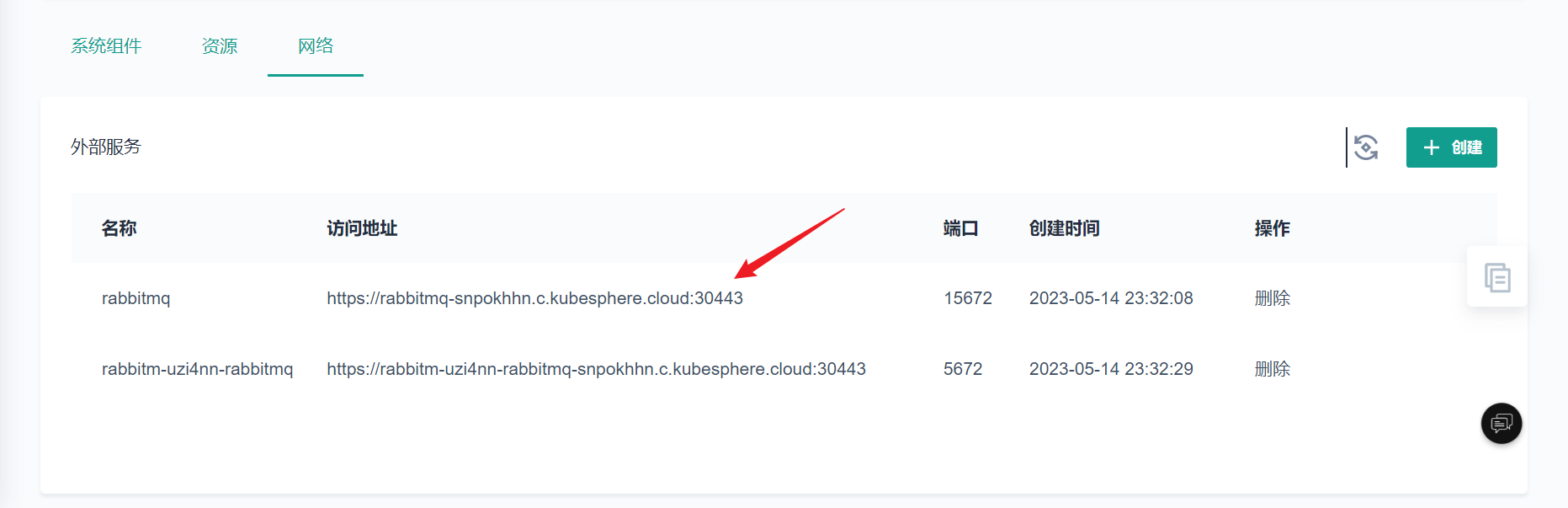
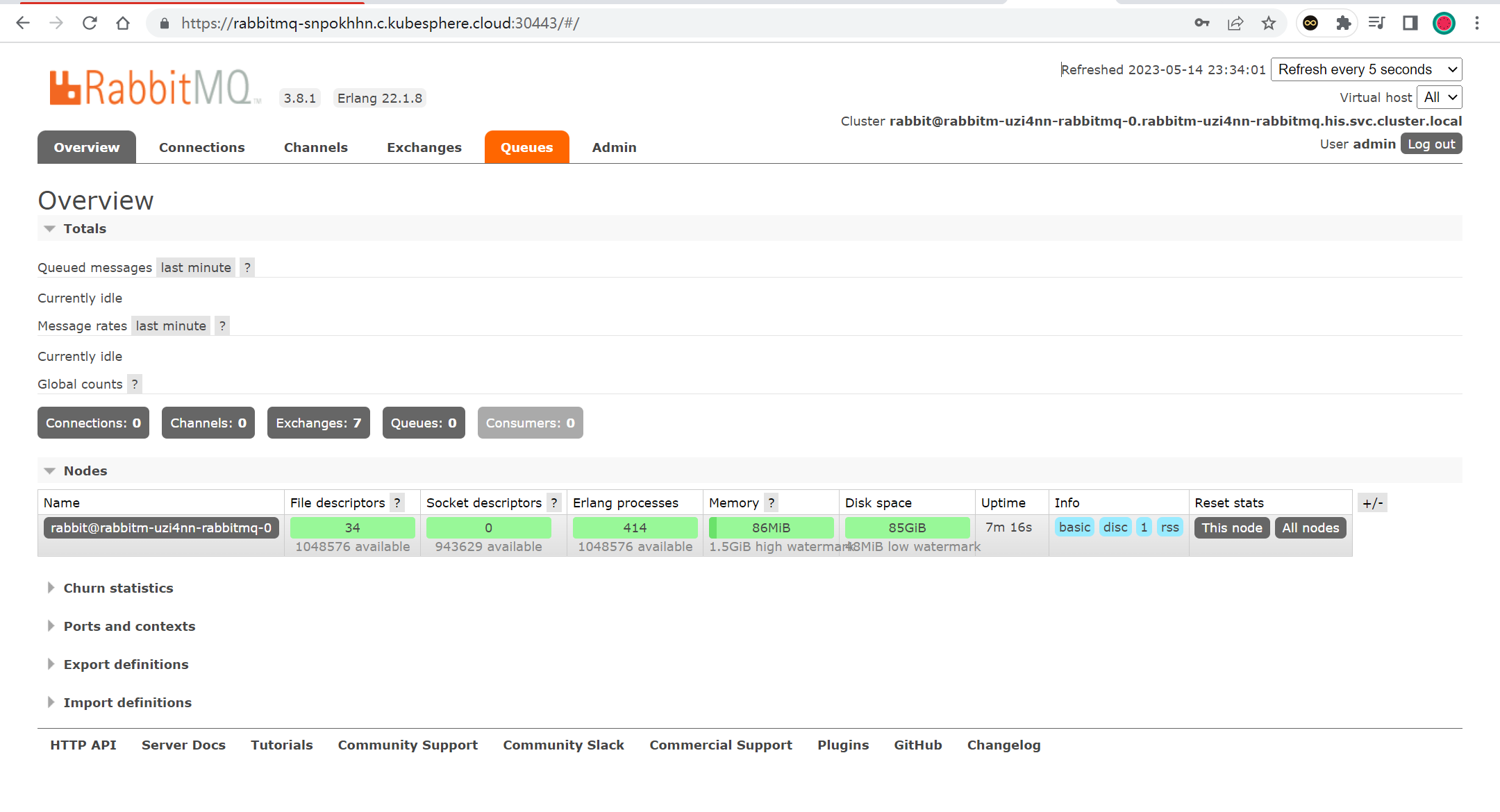

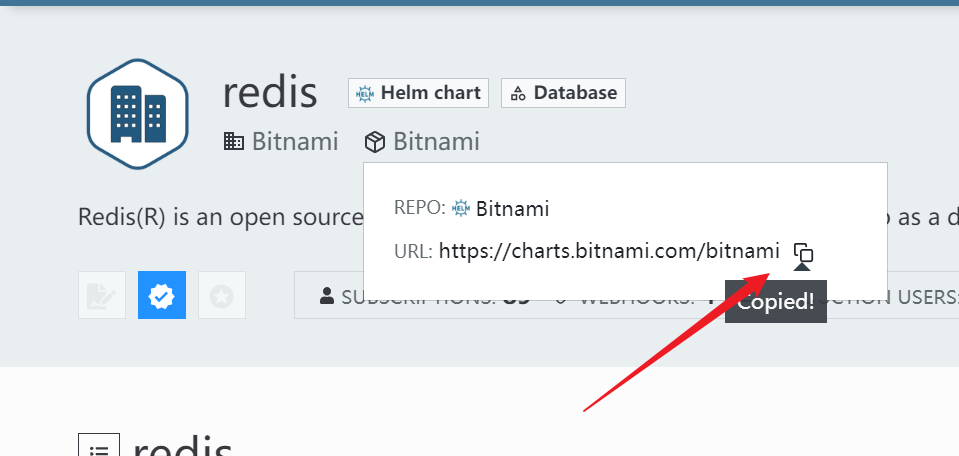
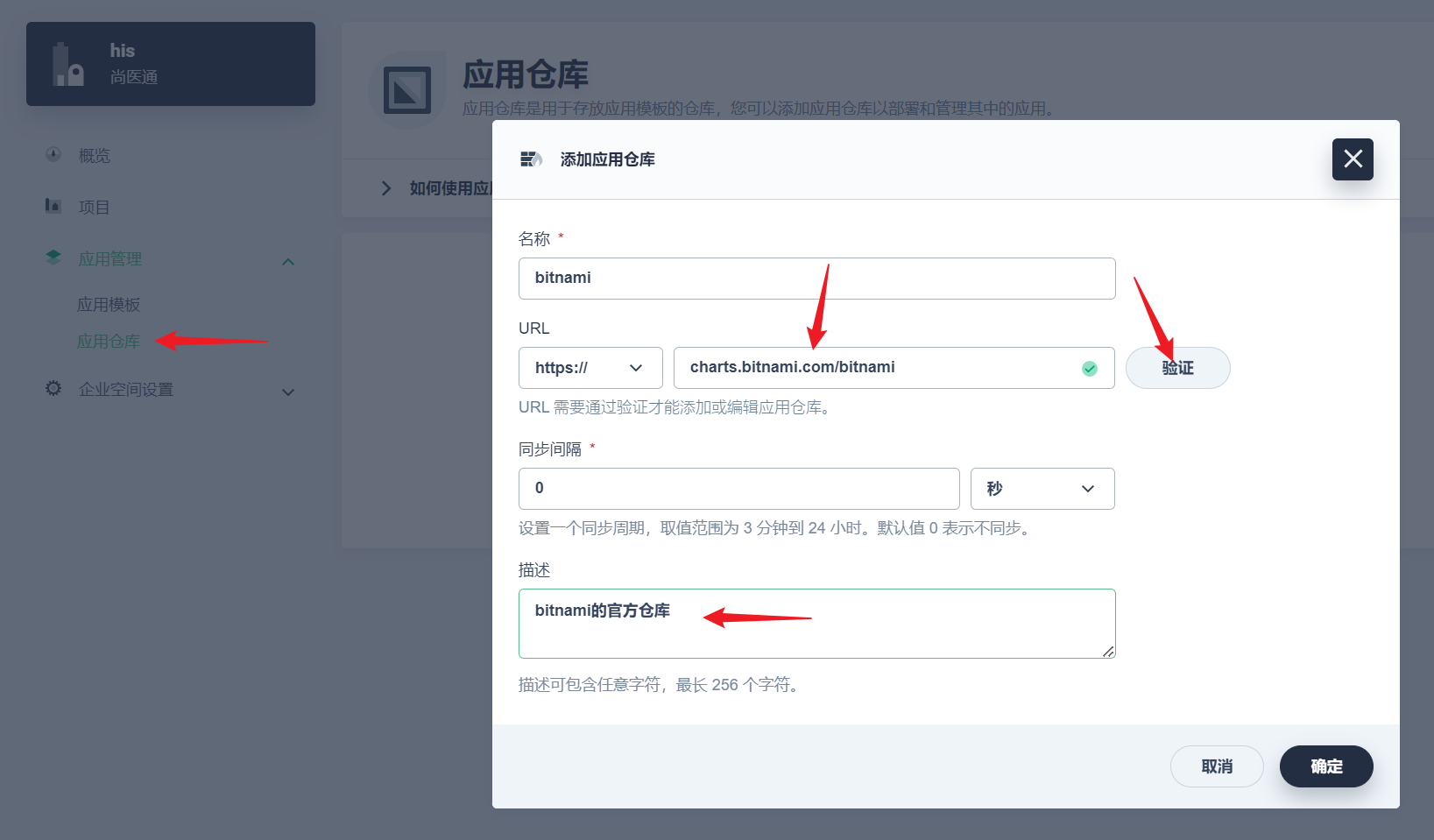
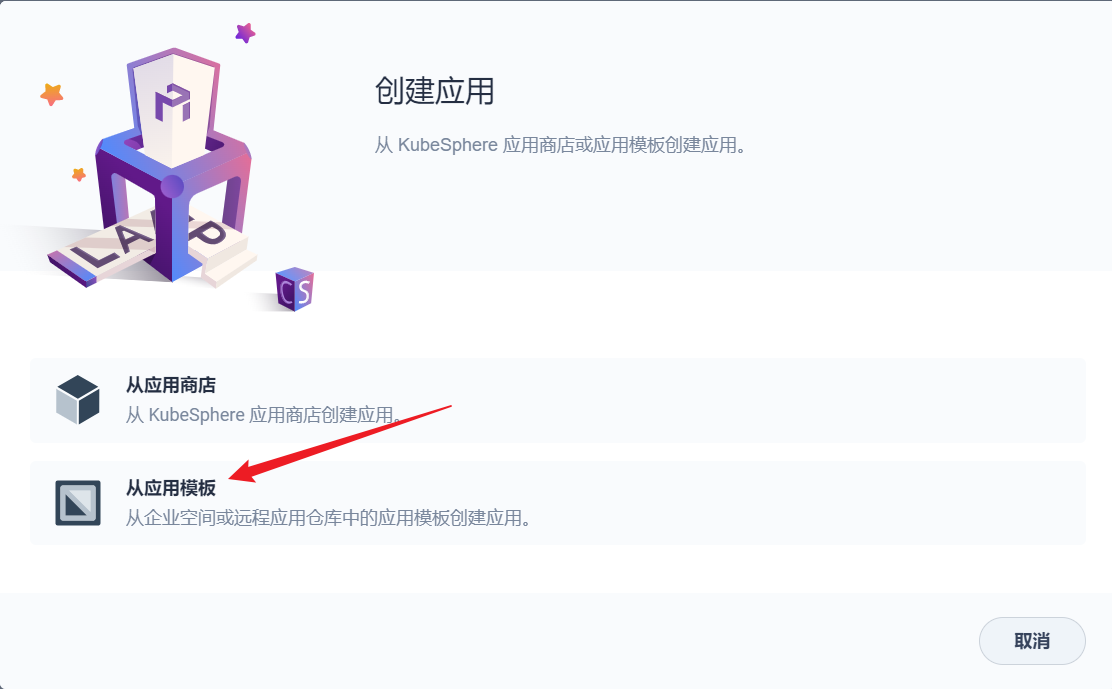
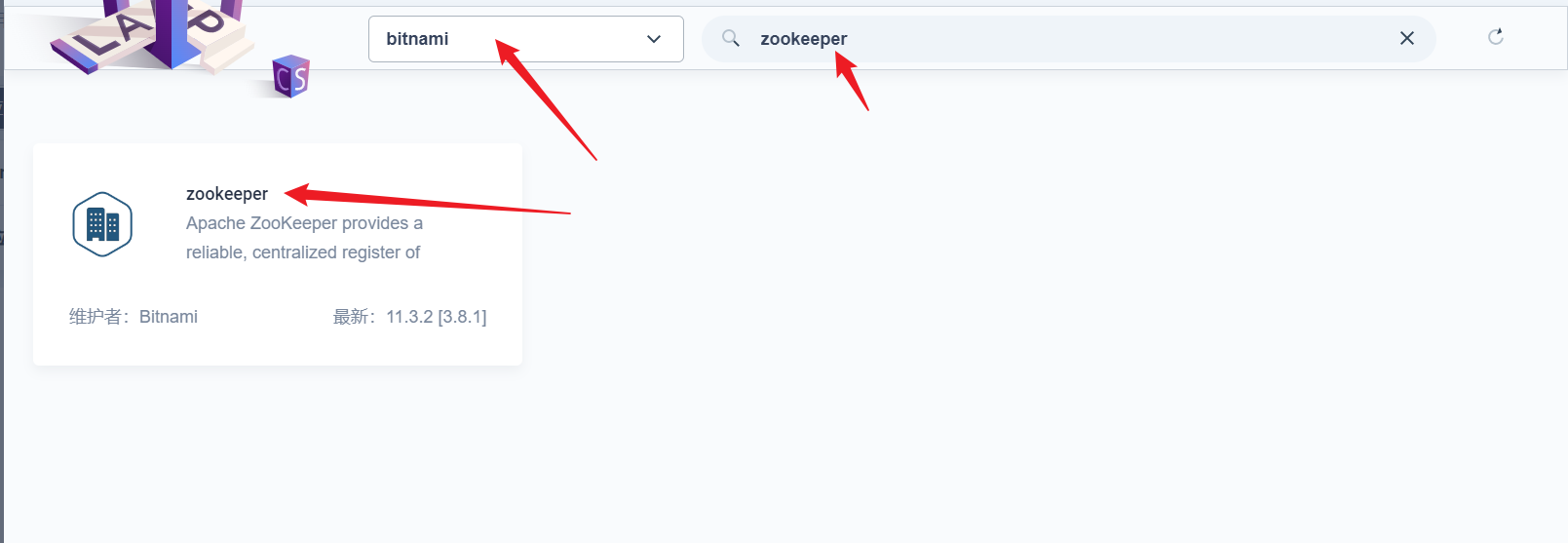
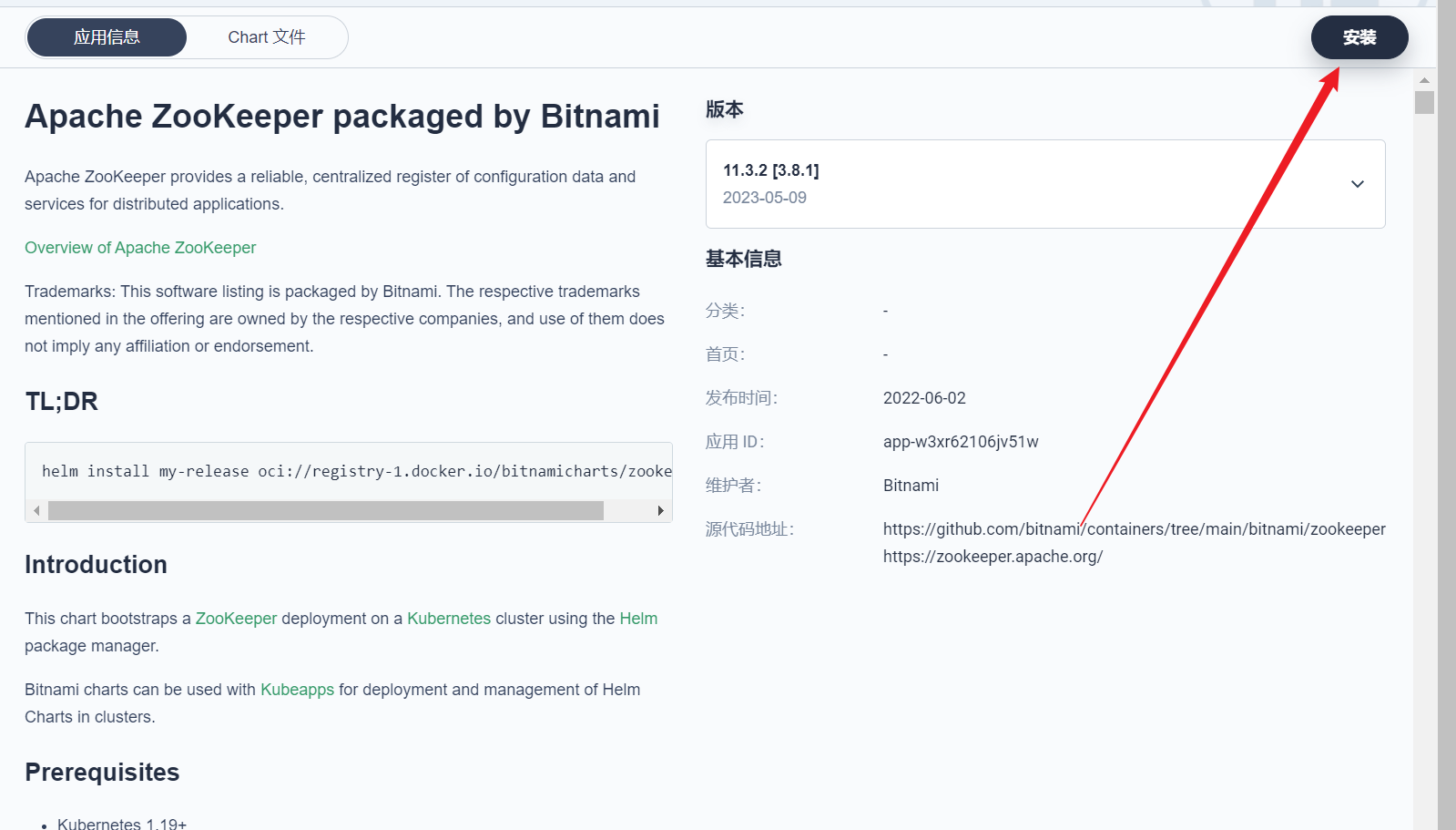
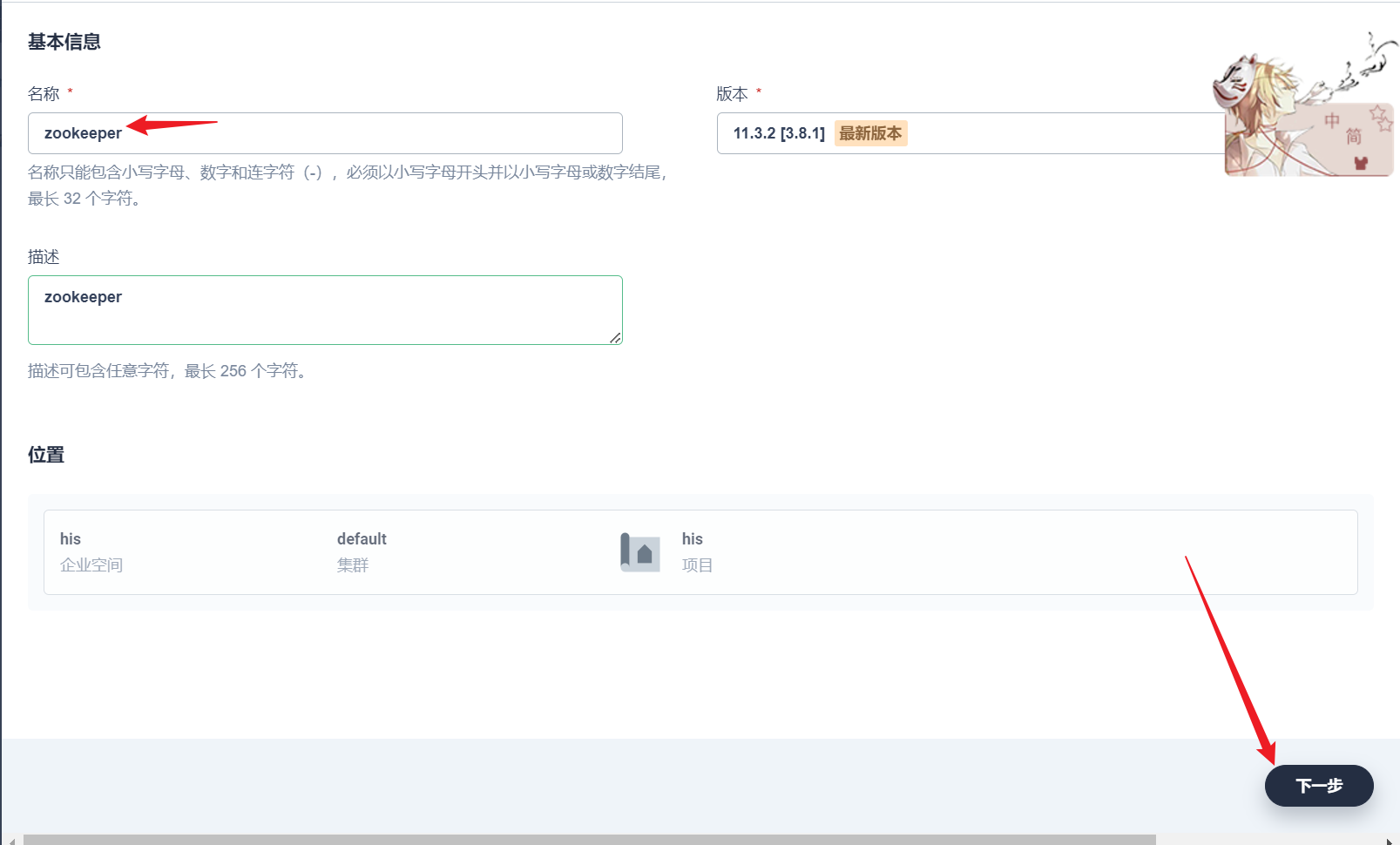
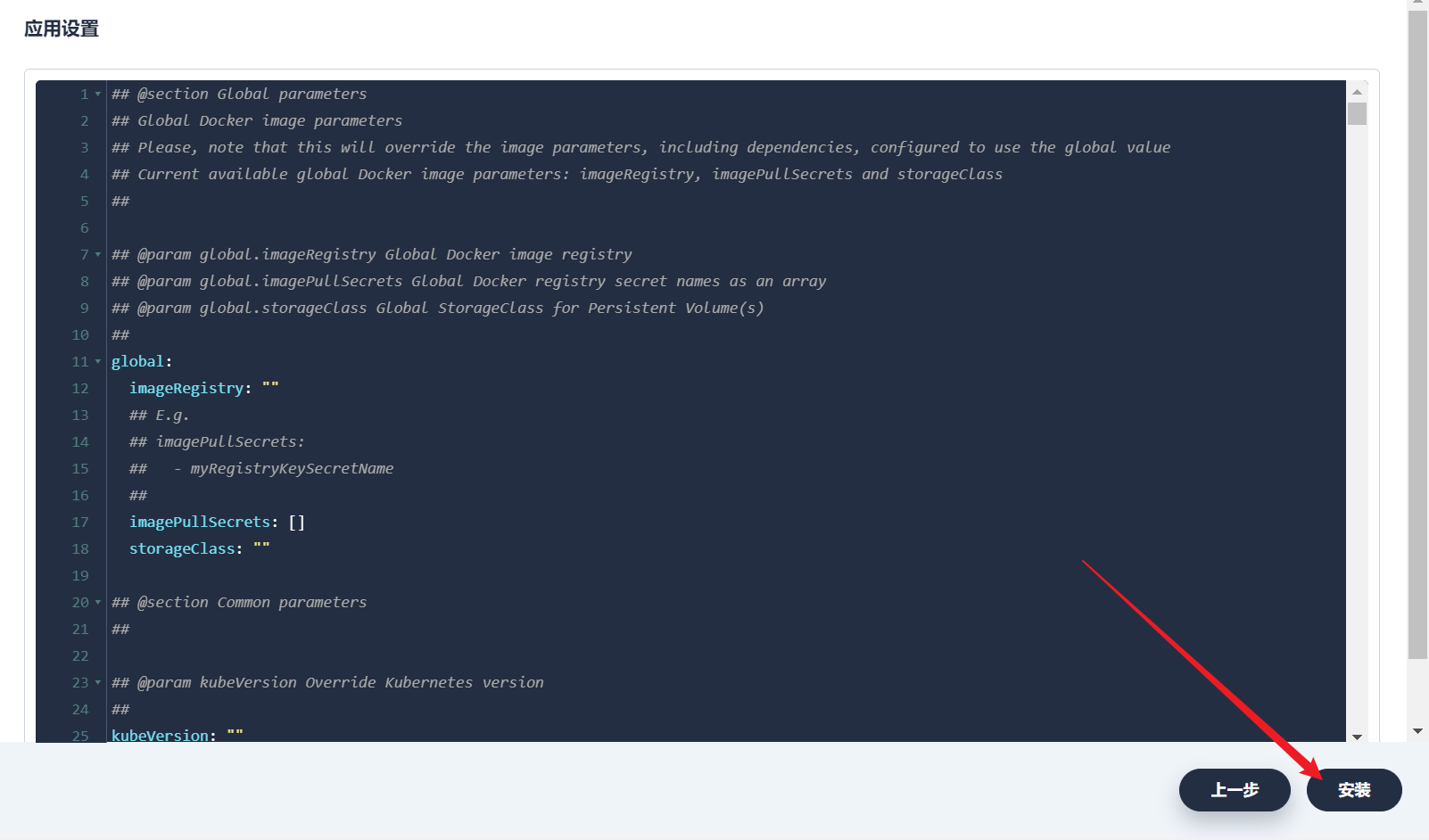
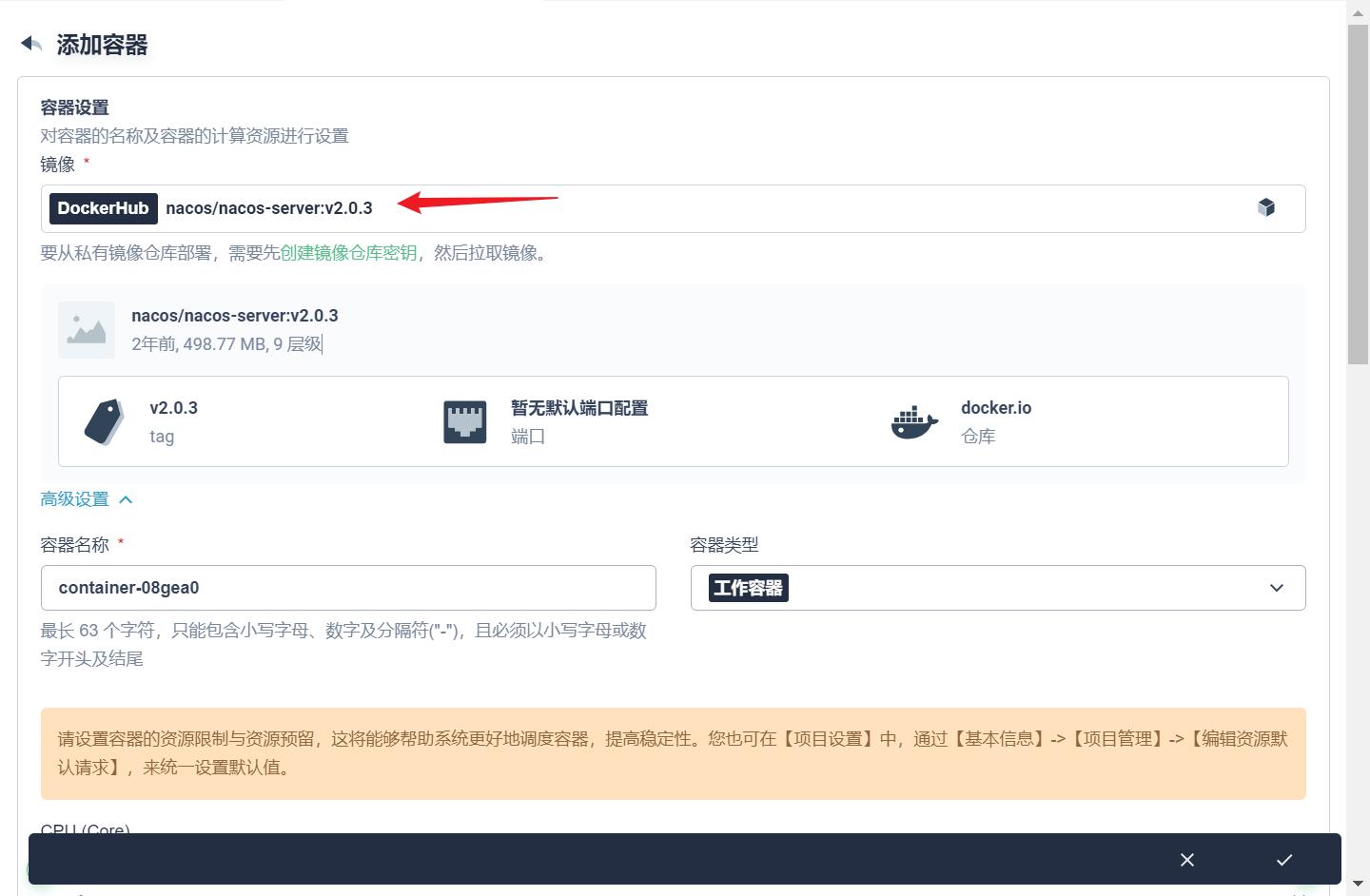
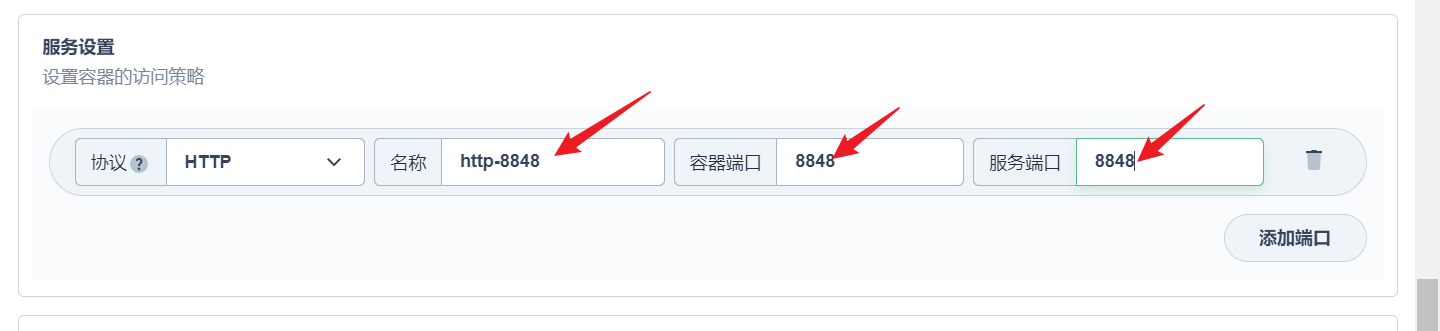

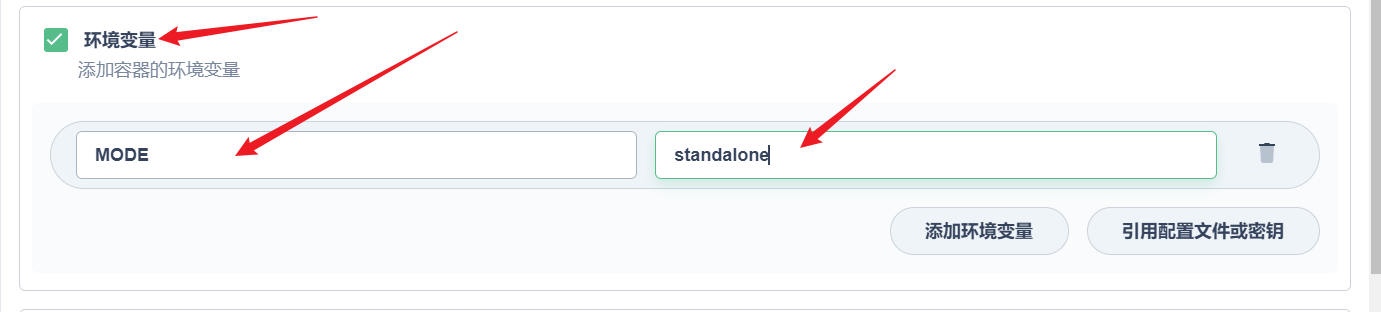
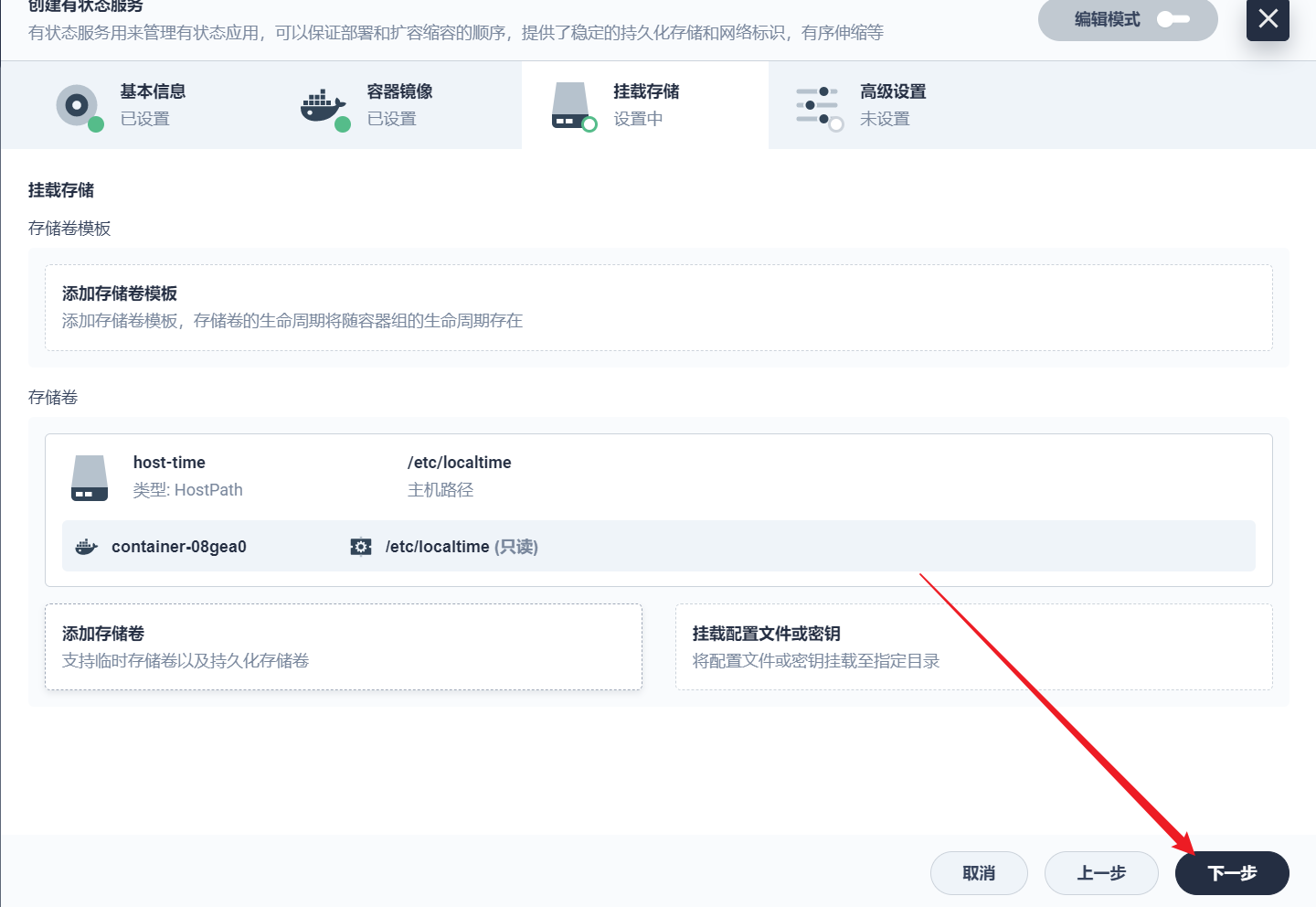
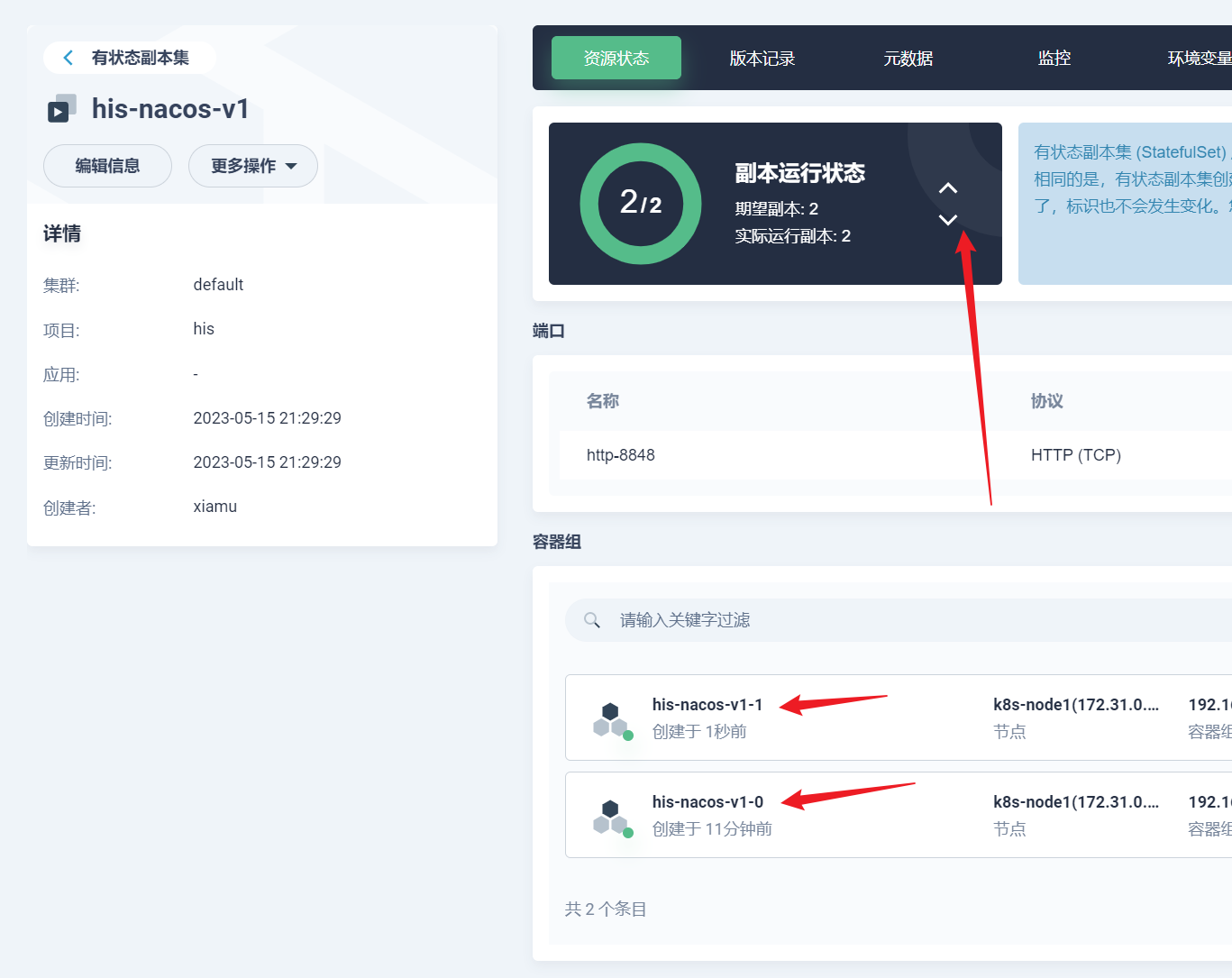
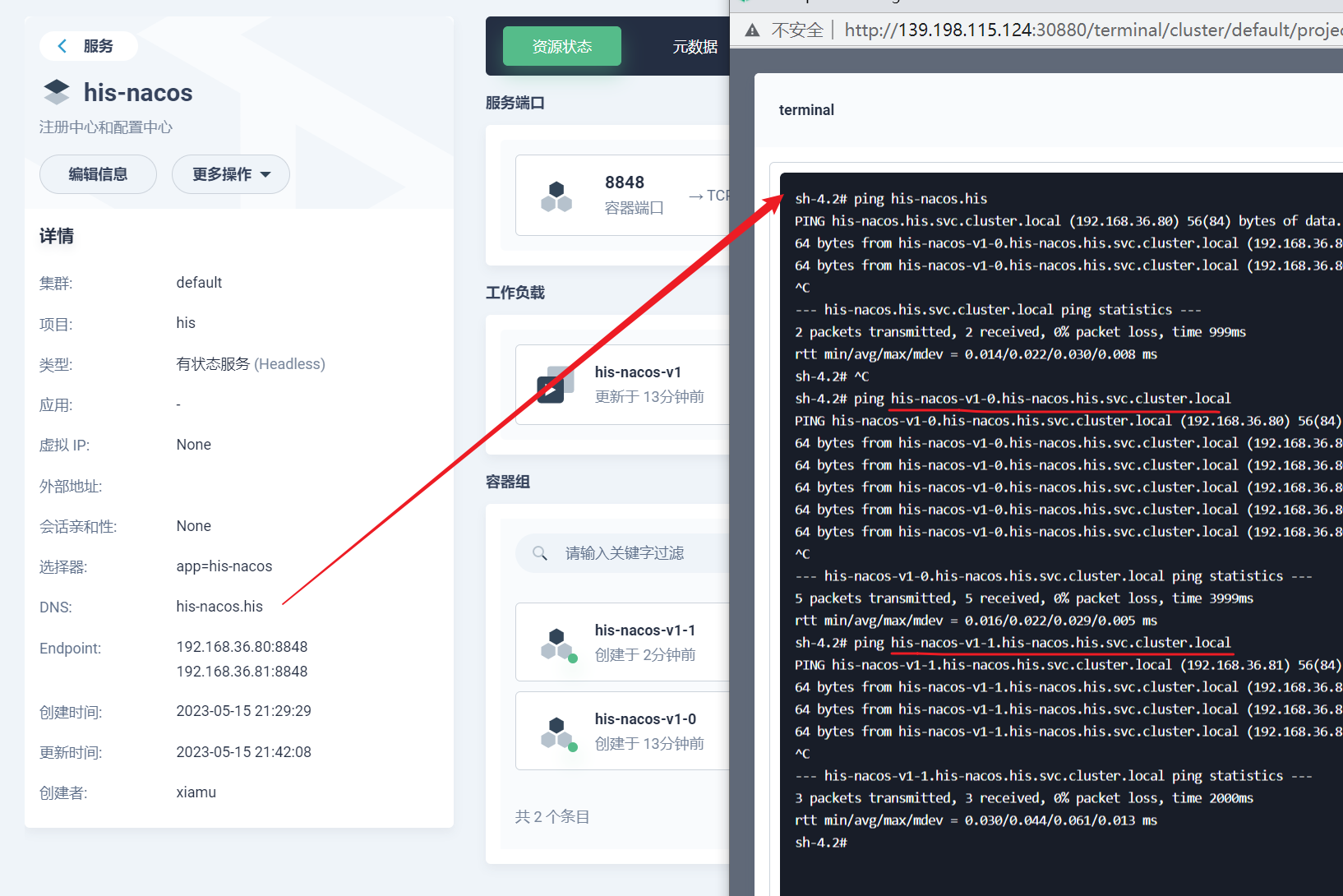
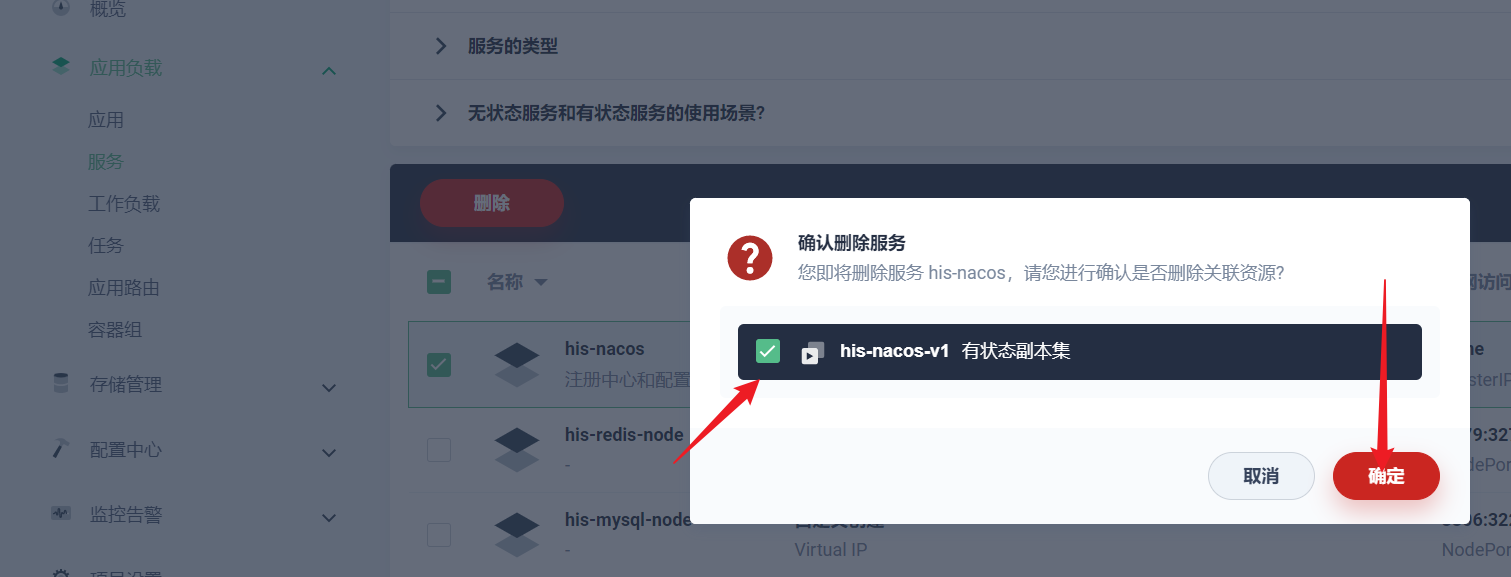
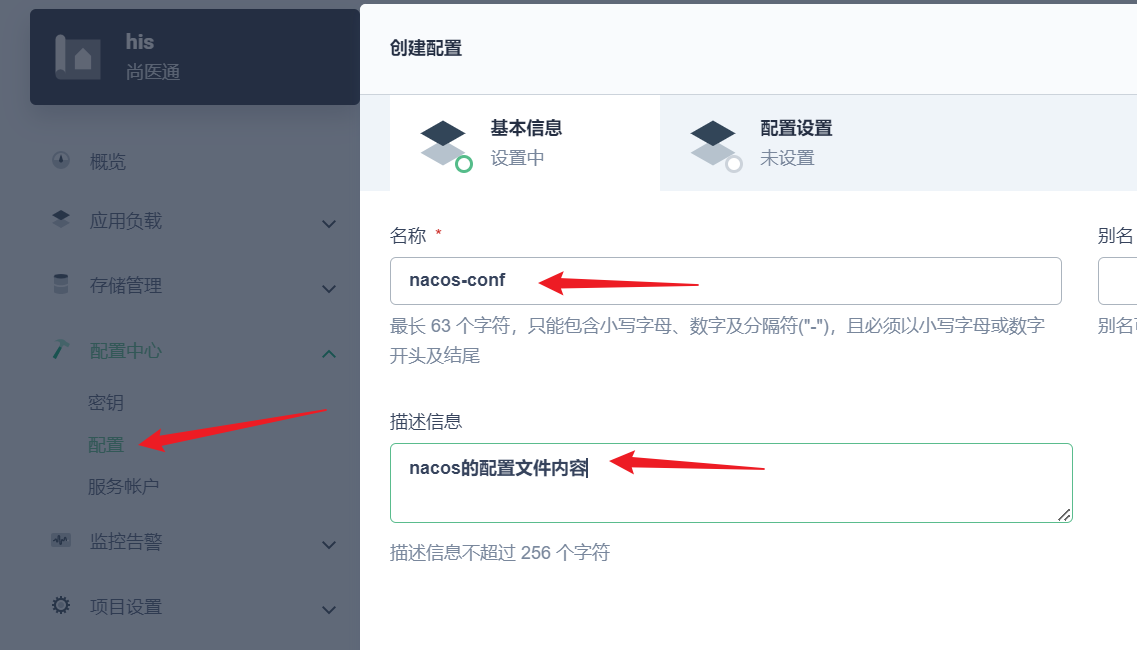
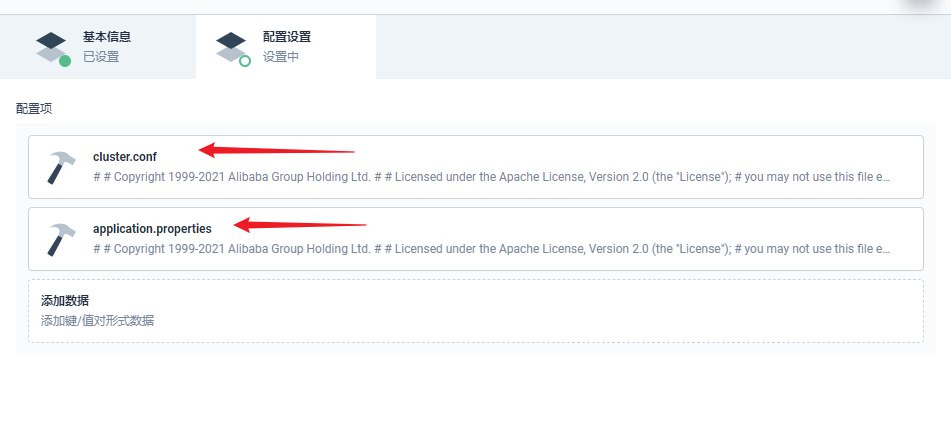
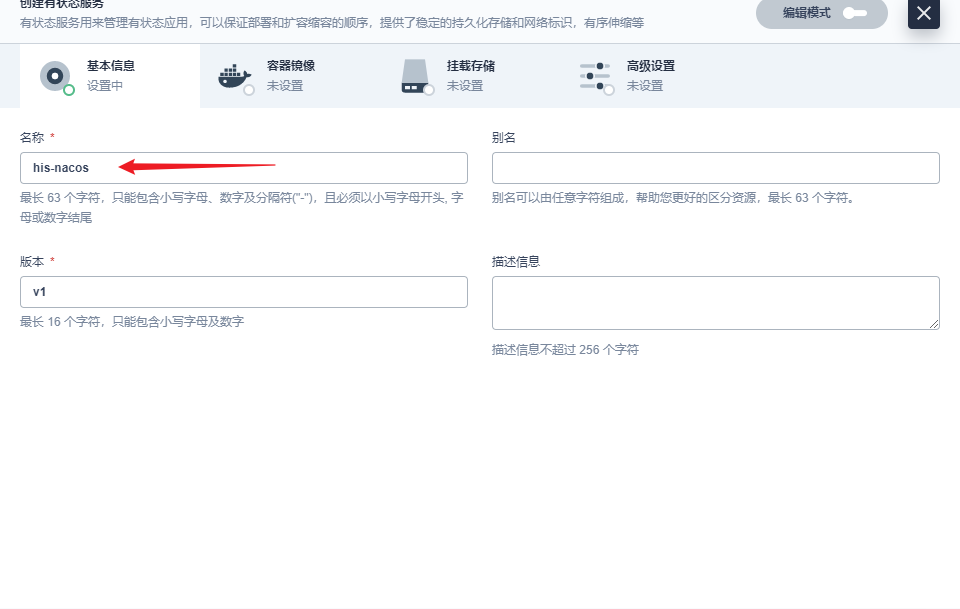
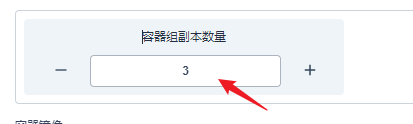
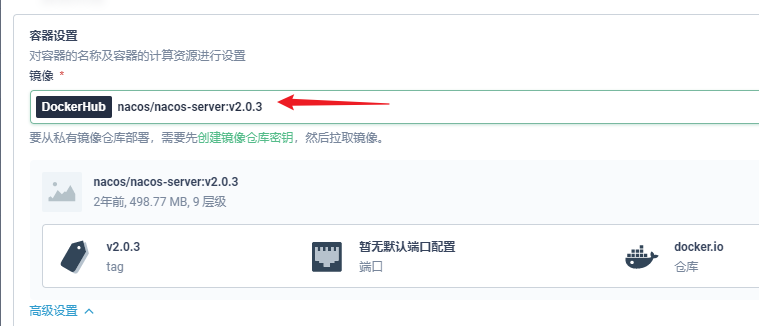
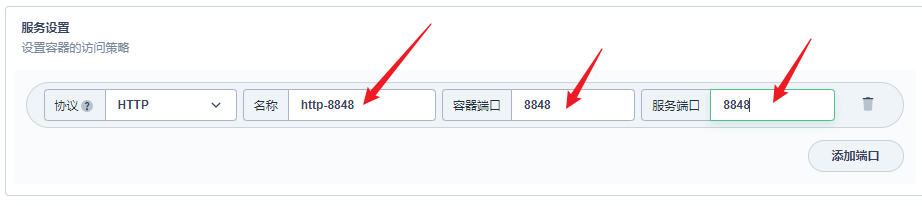

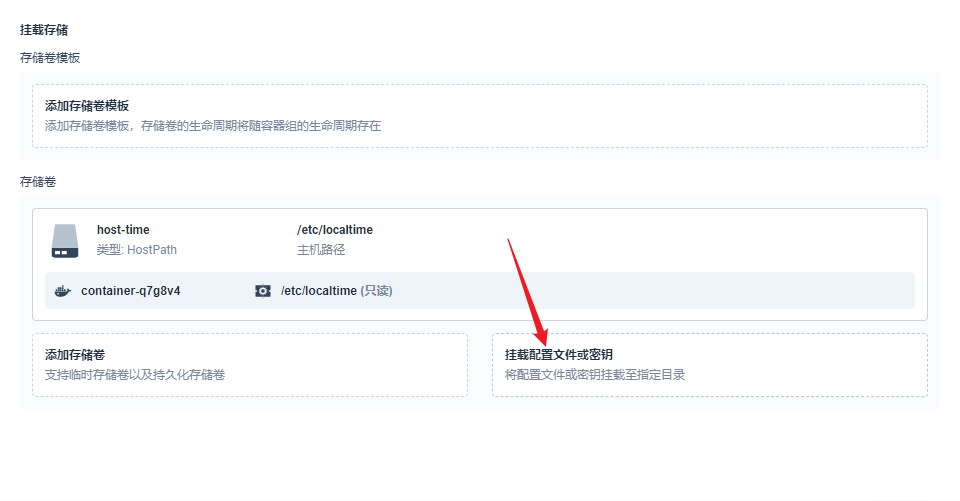
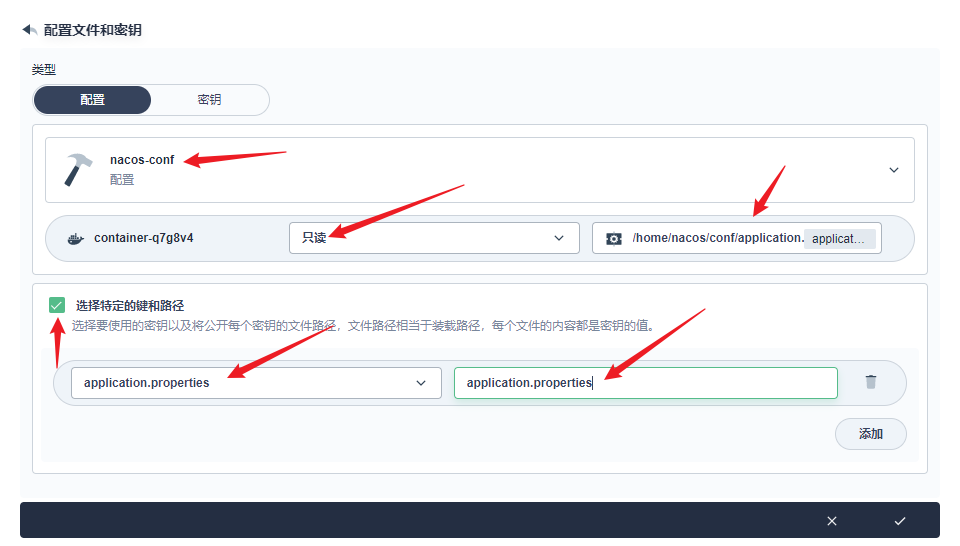
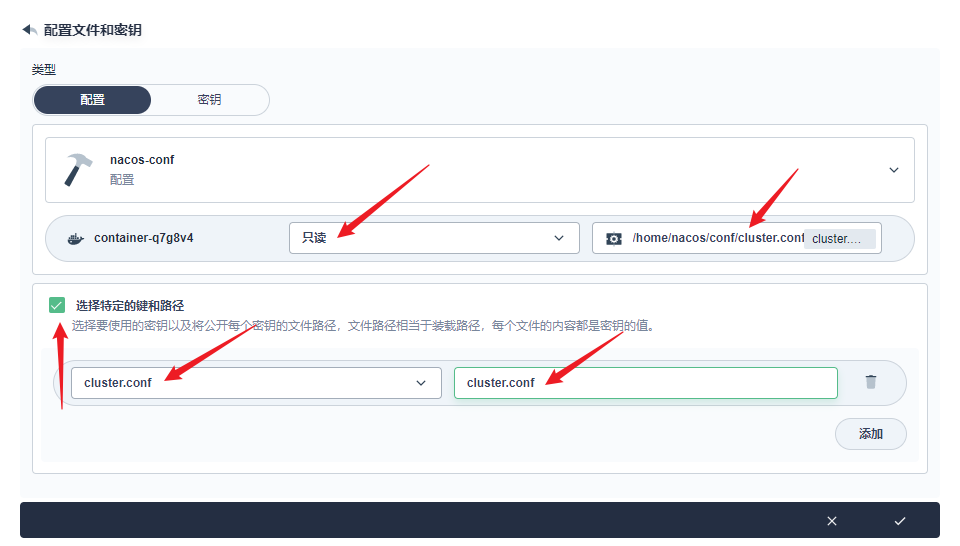
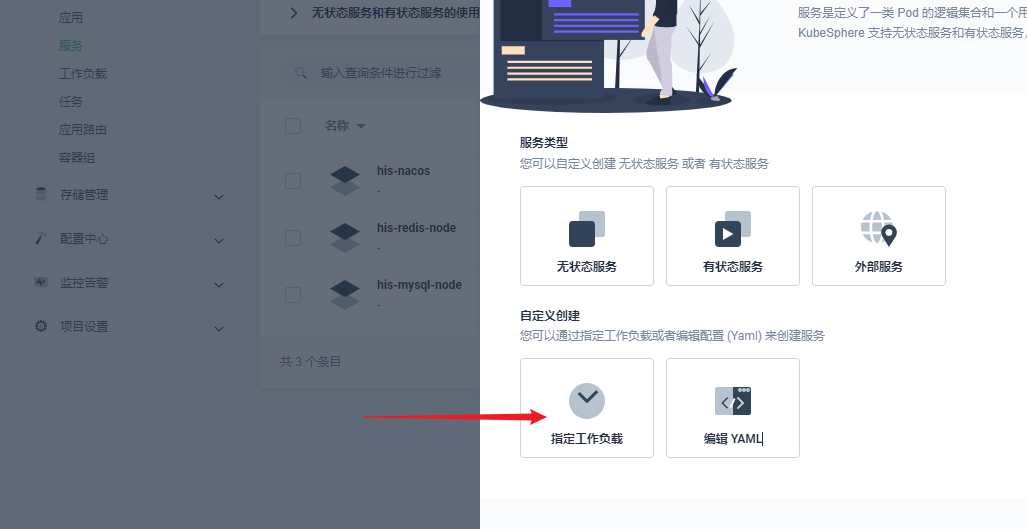
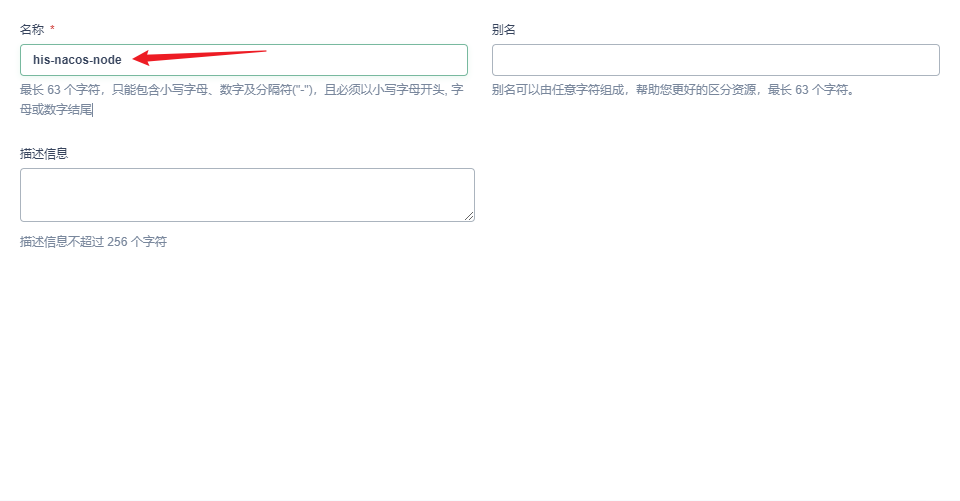
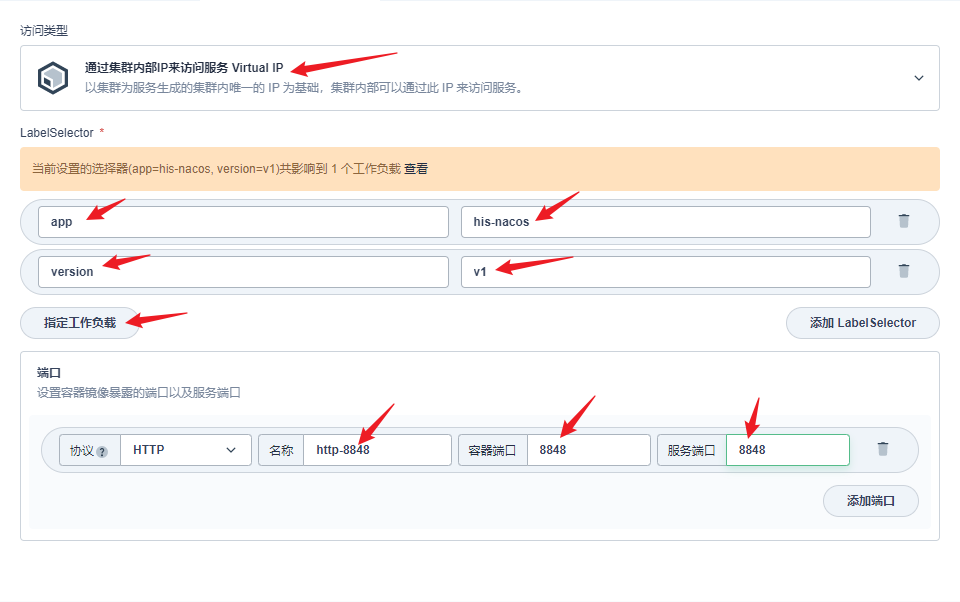
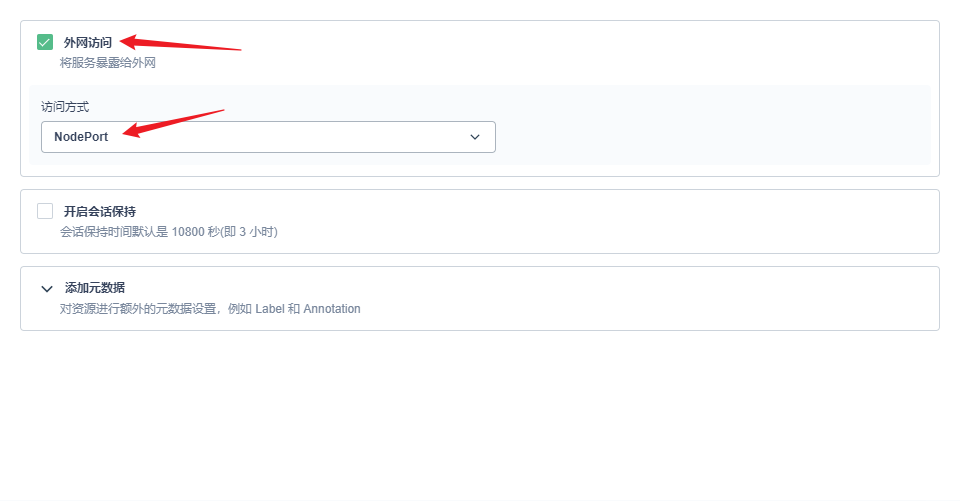
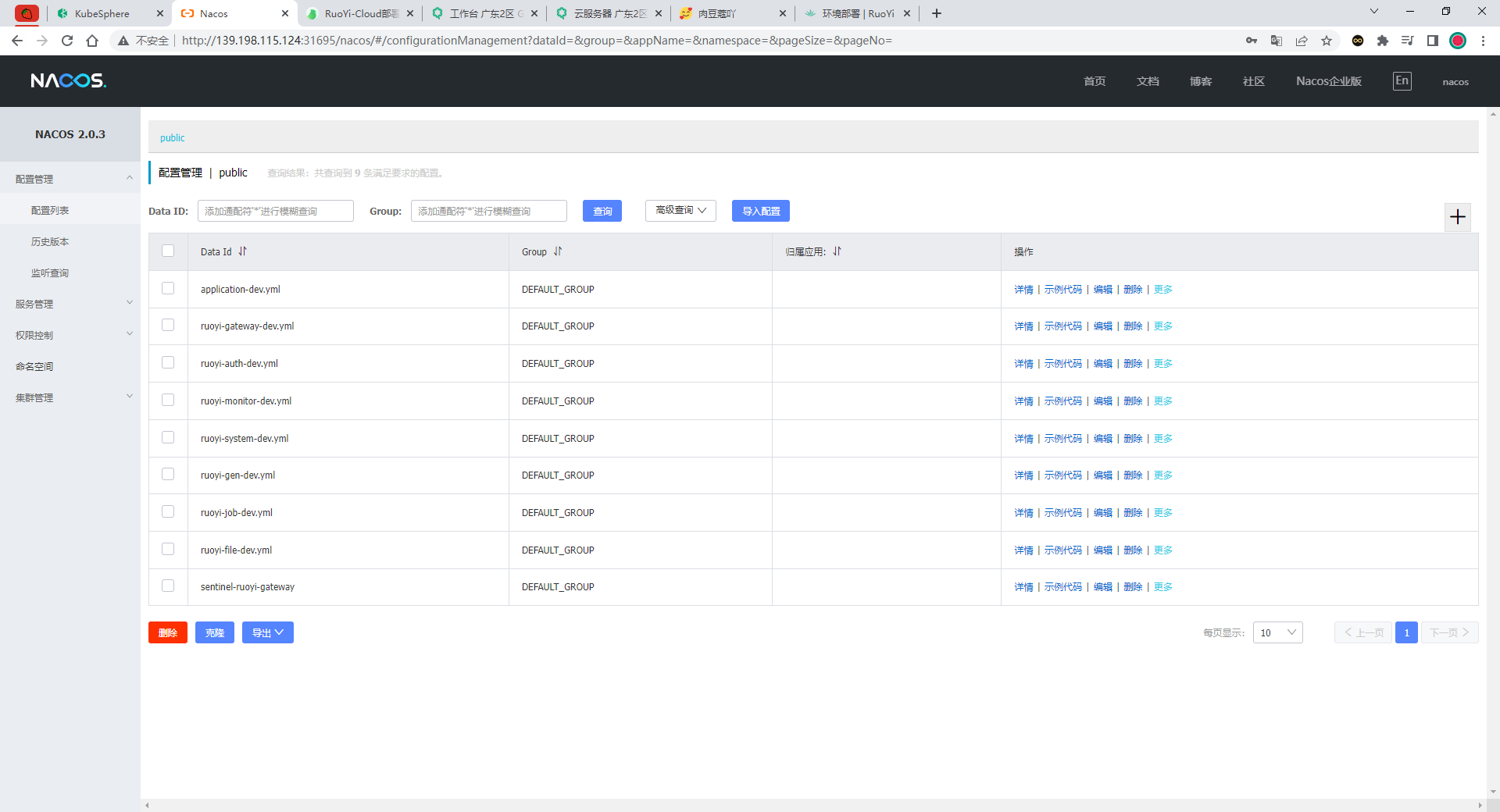
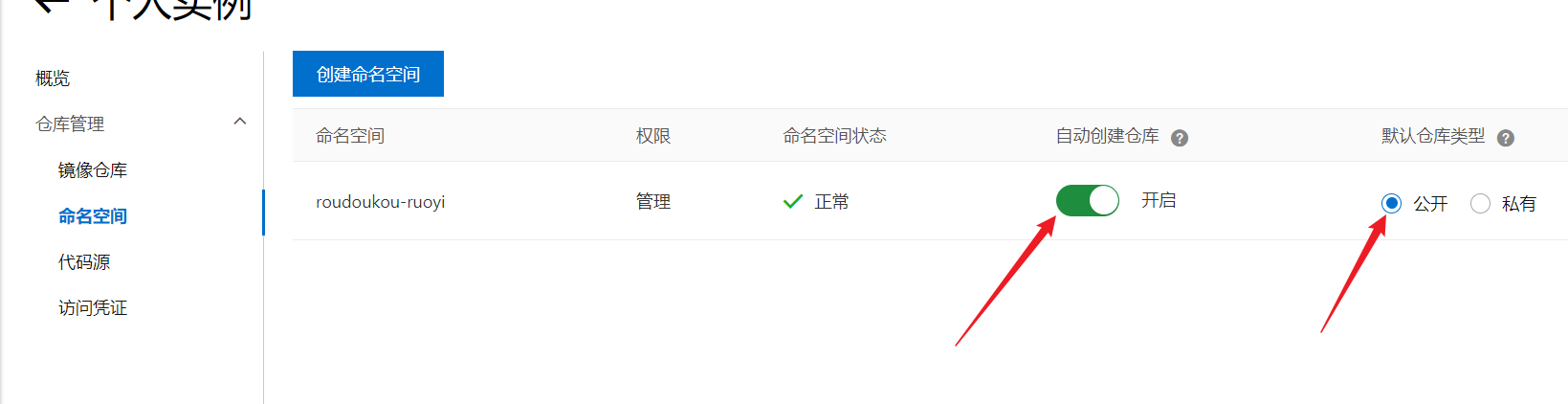
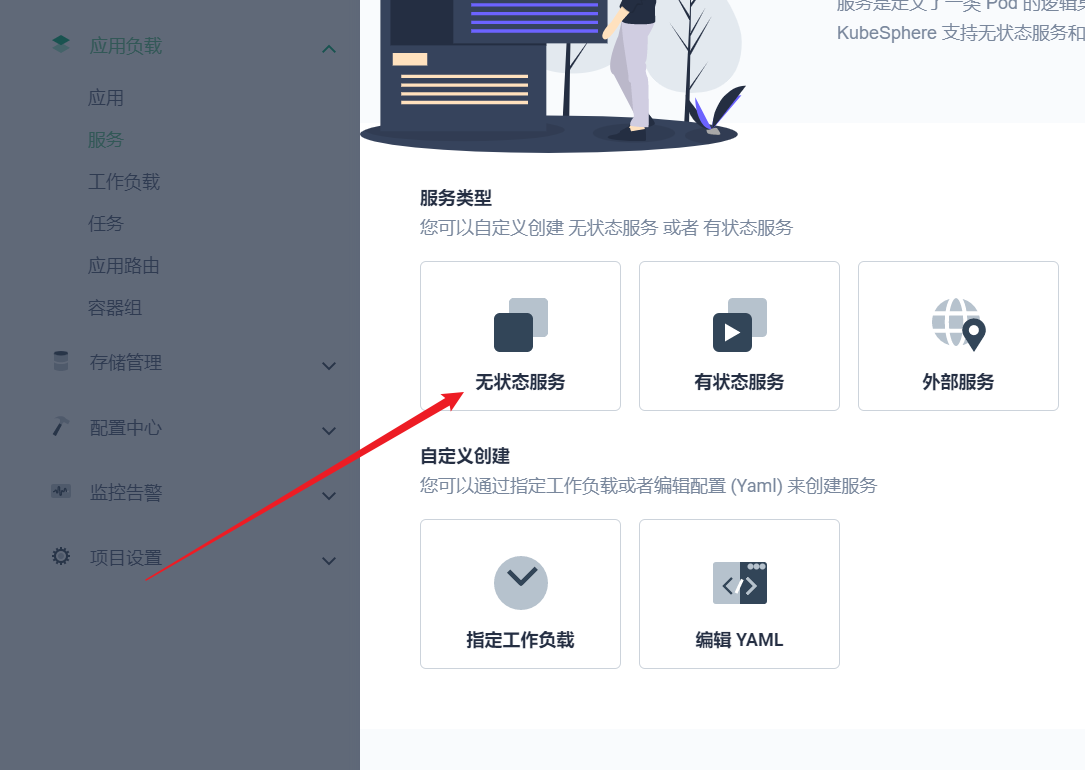

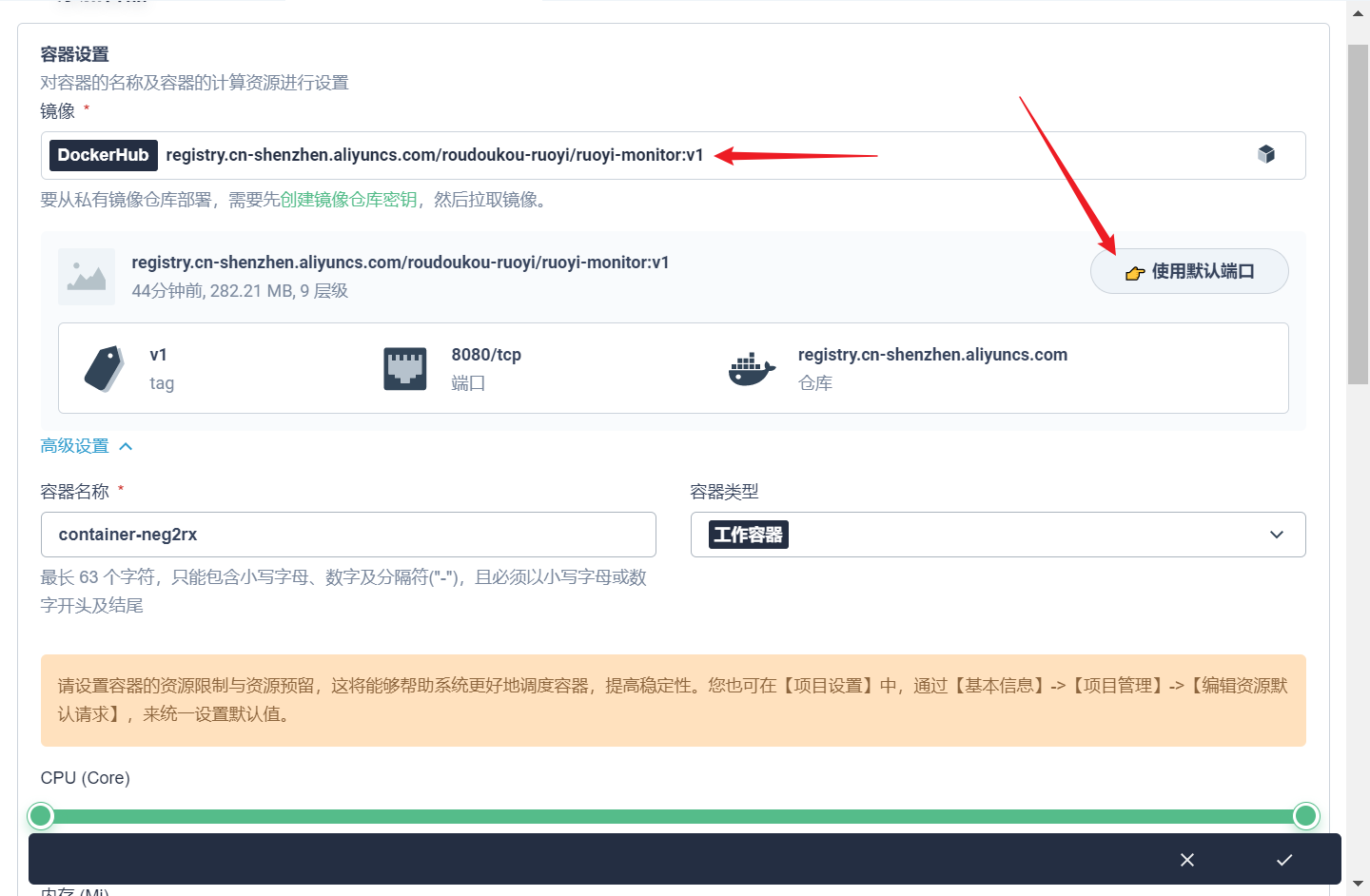
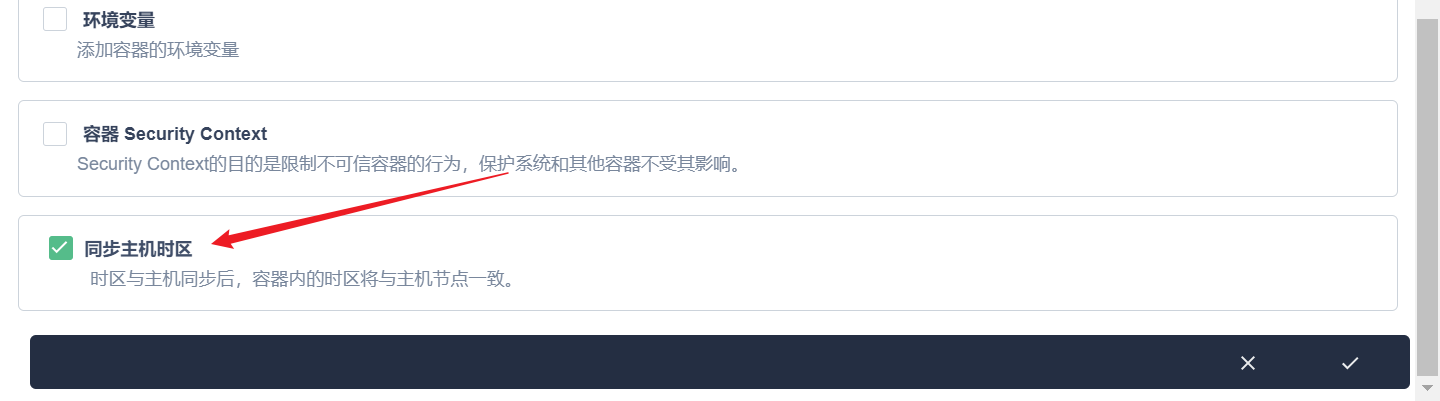
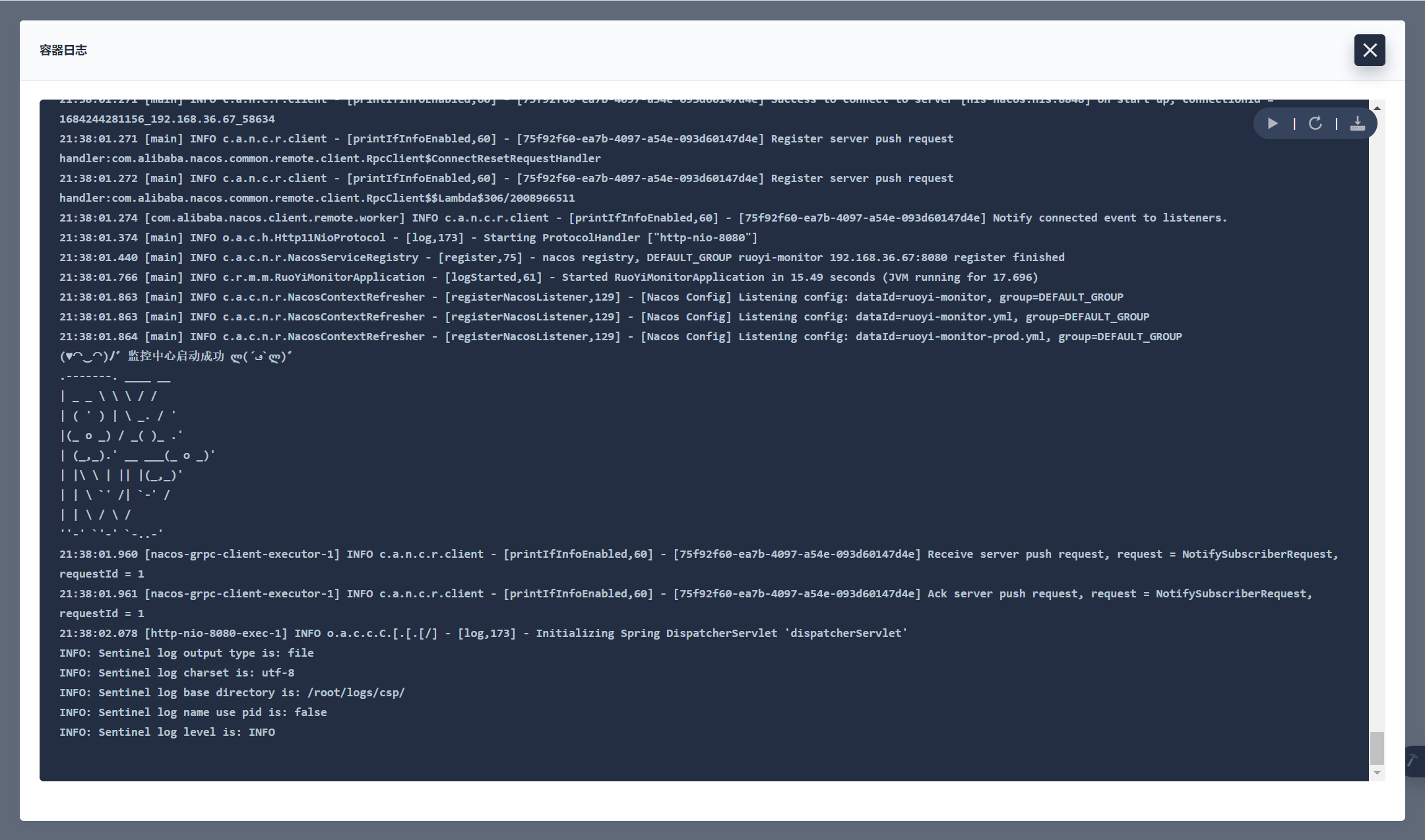
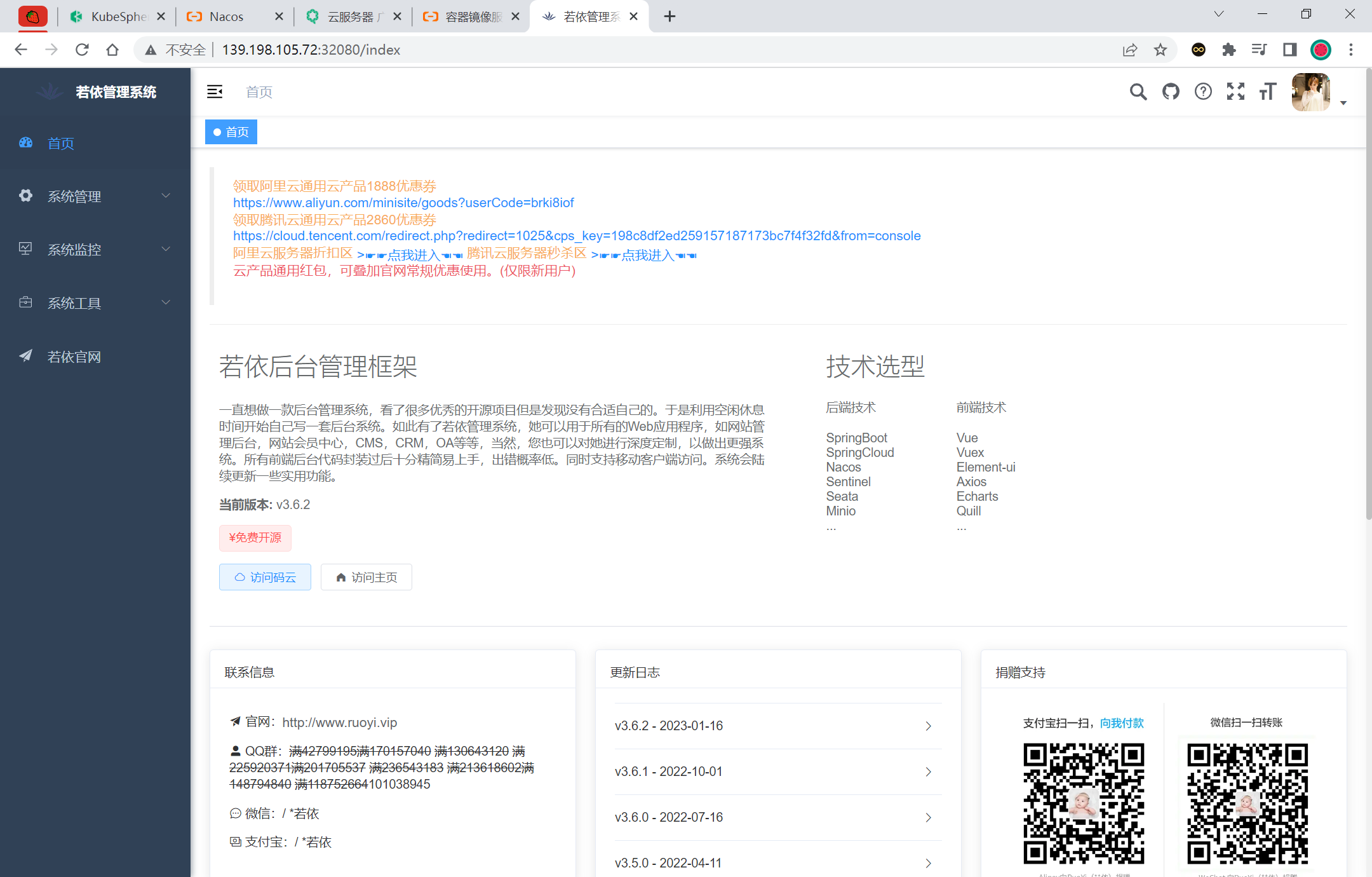
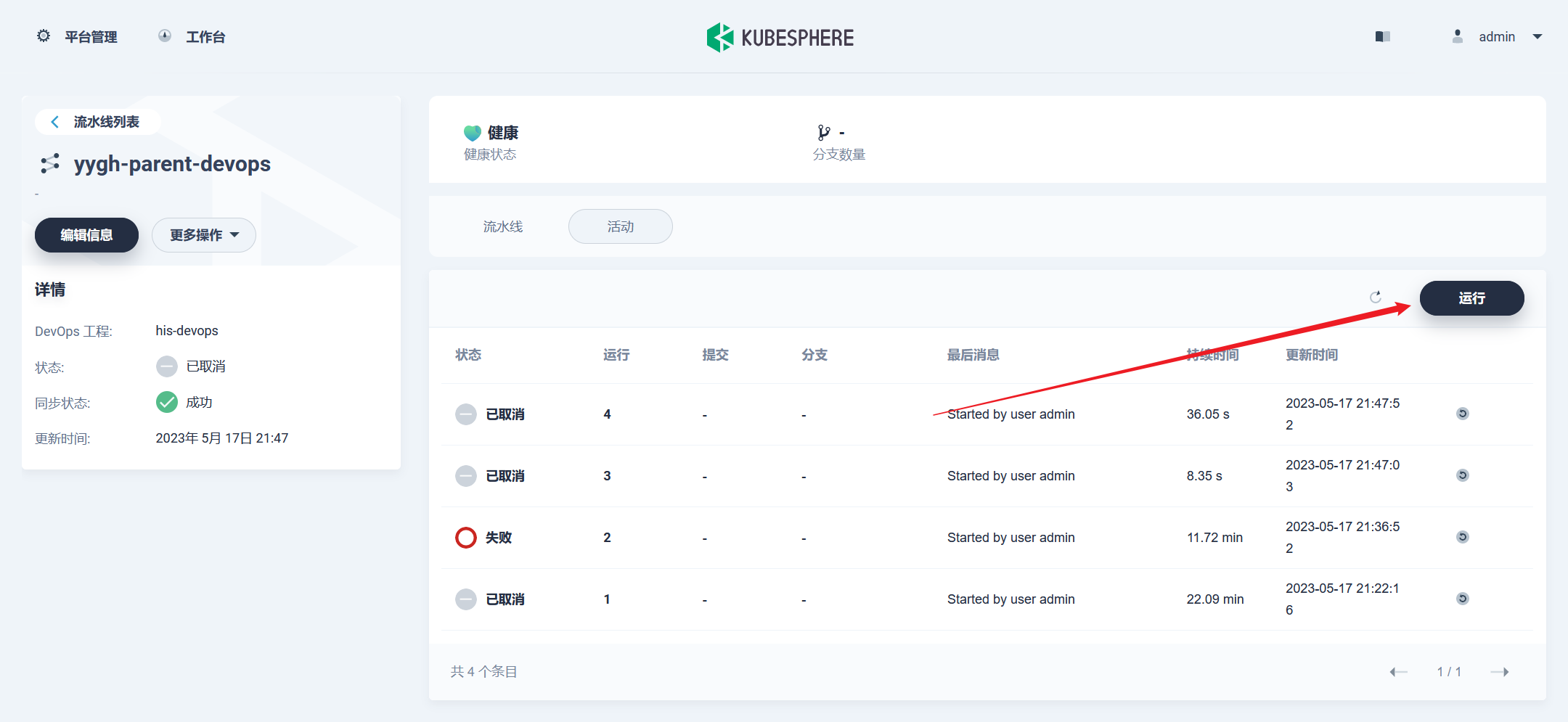
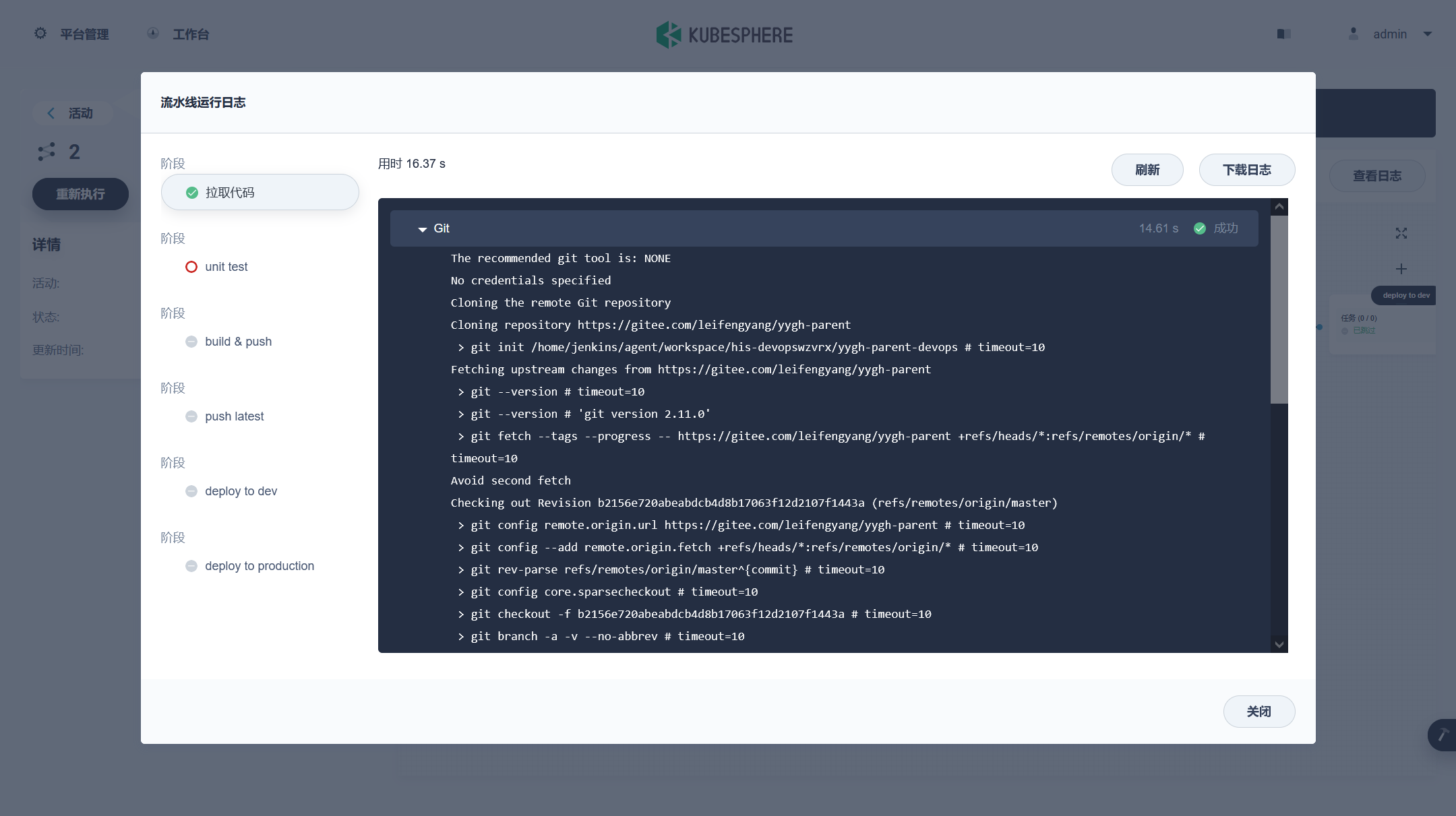
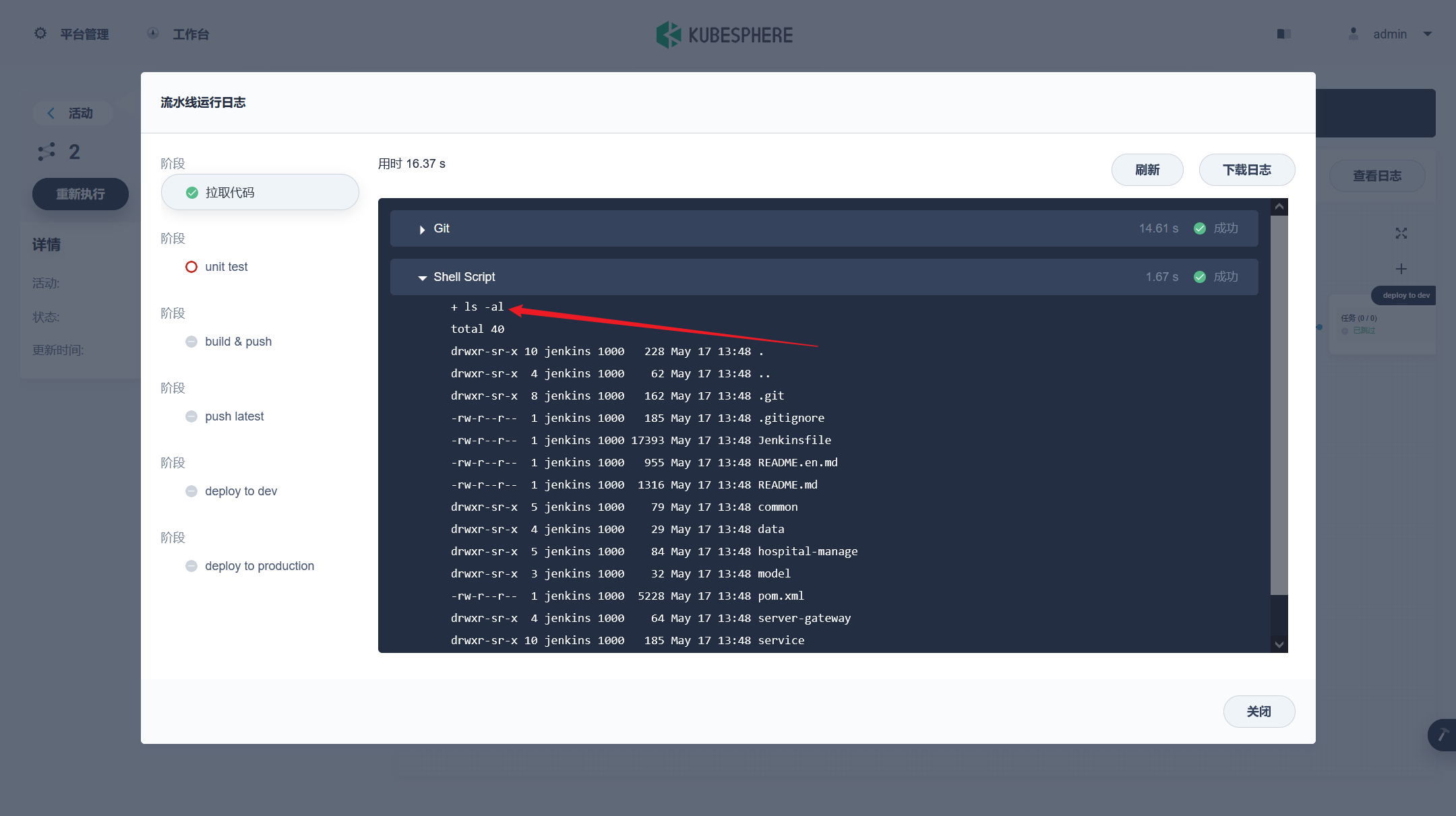
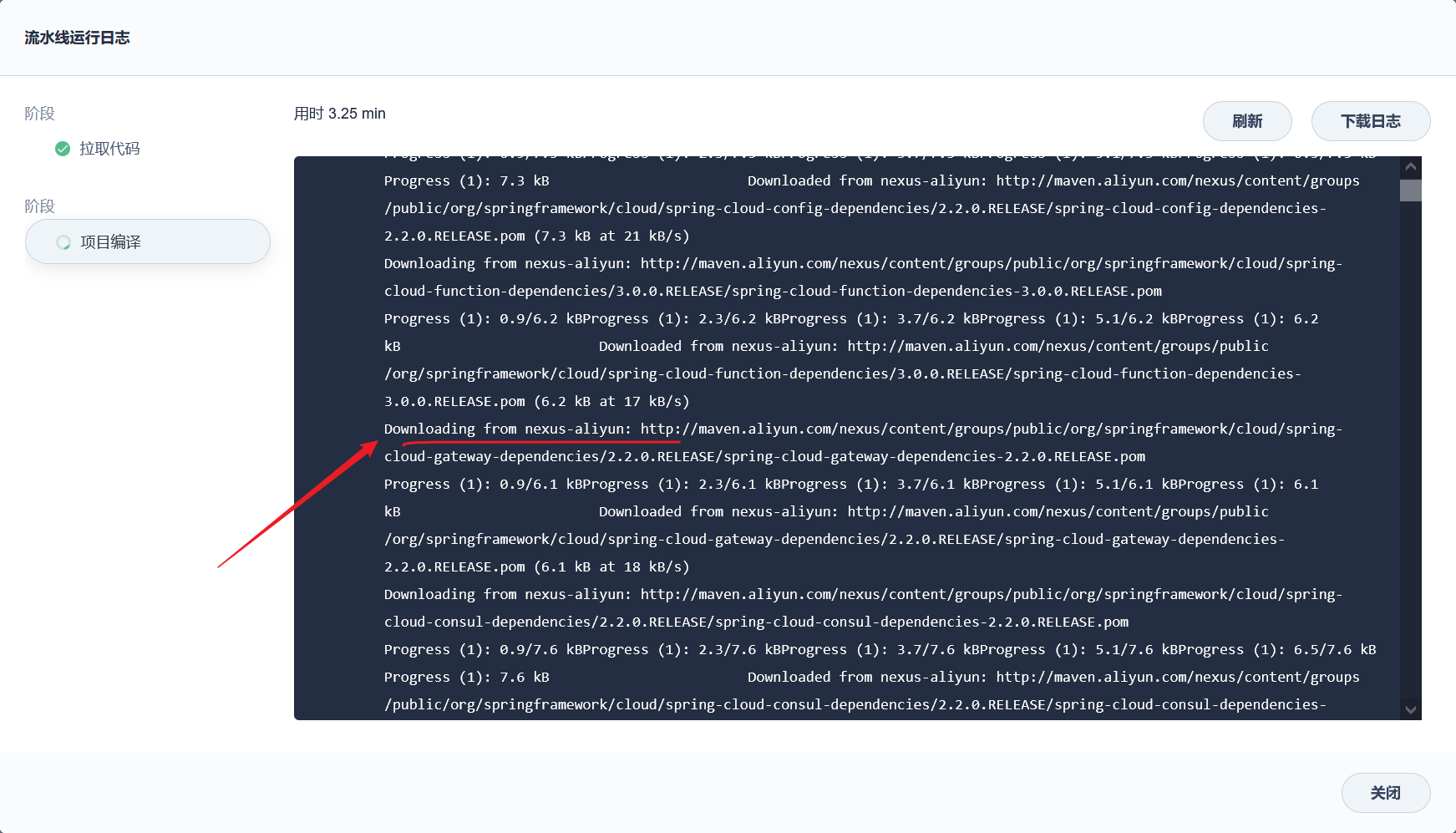
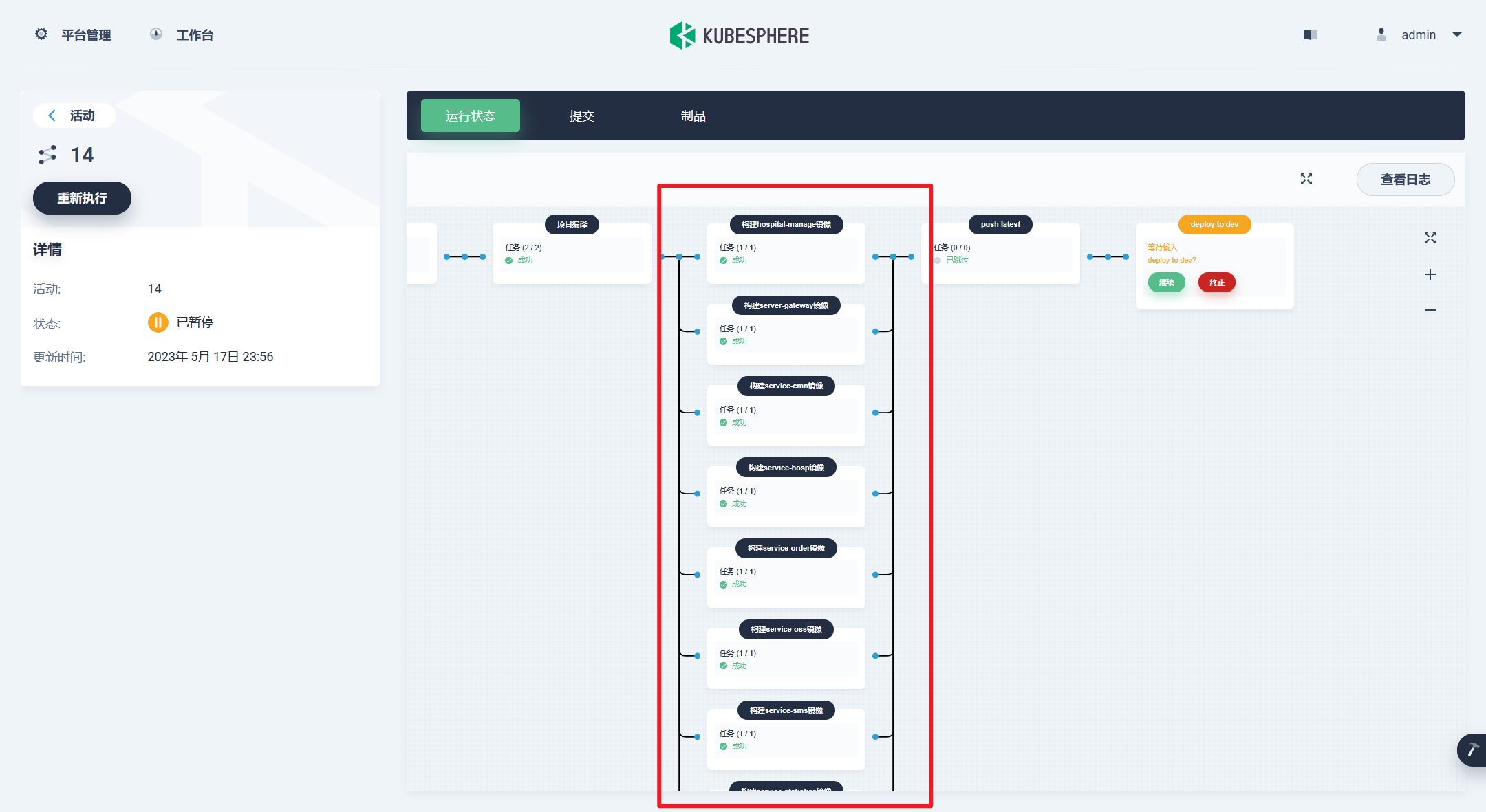
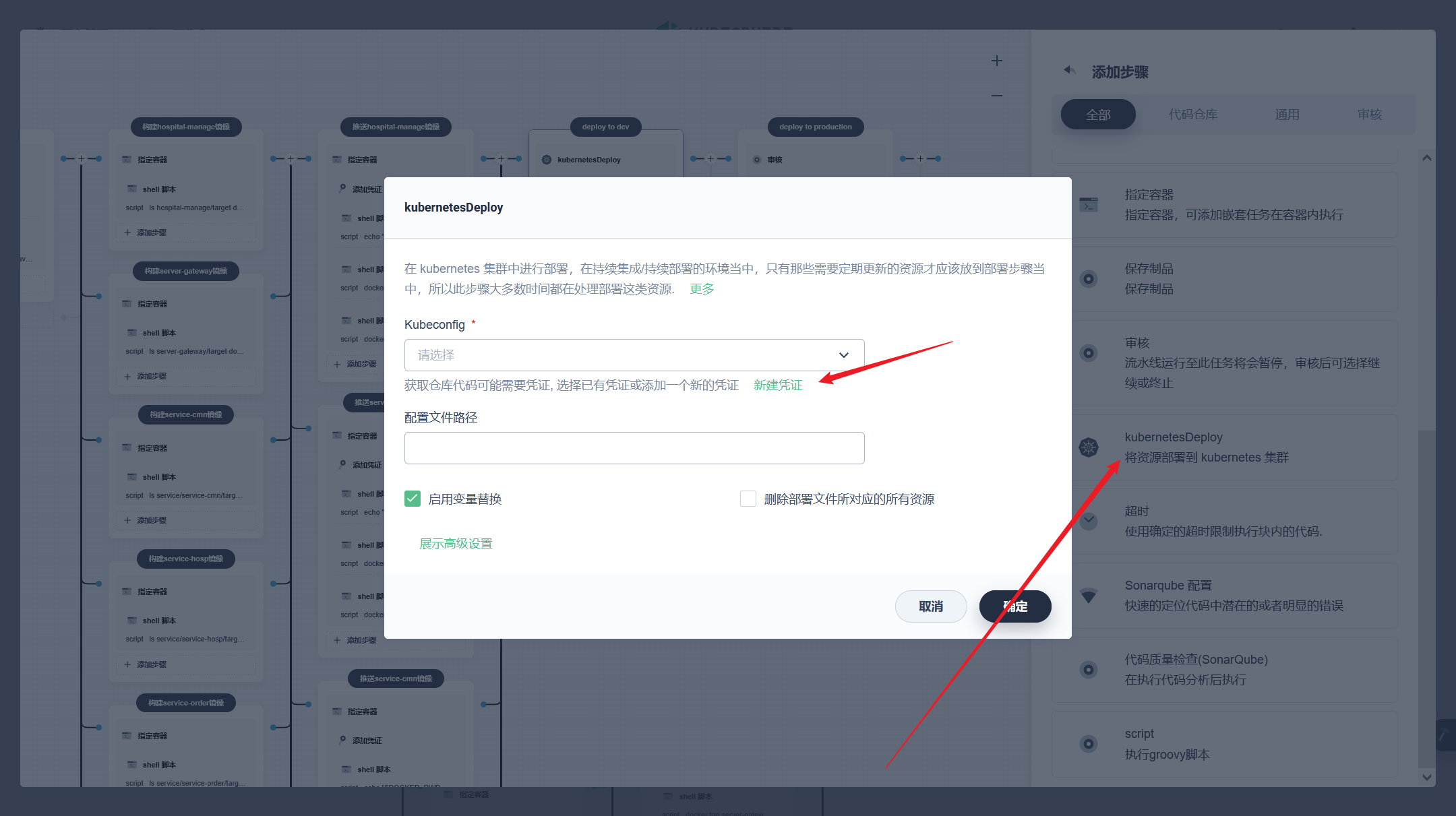
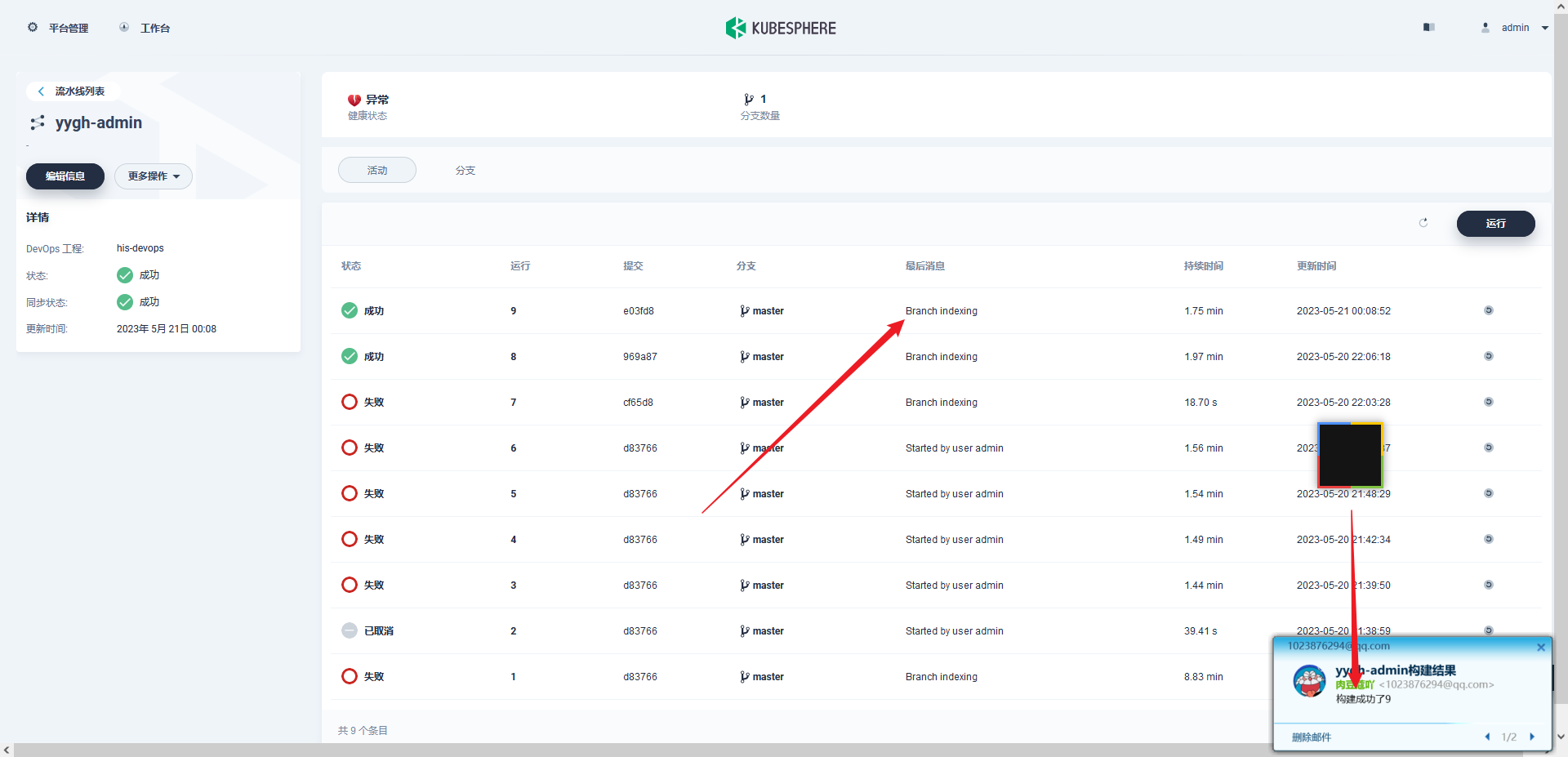
 部署完成之后查看日志,没有报错就ok
部署完成之后查看日志,没有报错就ok