下载 https://zookeeper.apache.org/ https://archive.apache.org/dist/zookeeper/
安装 上传到 linux 上[xiamu@hadoop202 software]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/[xiamu@hadoop202 module]$ mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7/[xiamu@hadoop202 module]$ cd zookeeper-3.5.7/[xiamu@hadoop202 zookeeper-3.5.7]$ mkdir zkData[xiamu@hadoop202 zookeeper-3.5.7]$ cd conf/[xiamu@hadoop202 zookeeper-3.5.7]$ mv zoo_sample.cfg zoo.cfg[xiamu@hadoop202 conf]$ vim zoo.cfg
1 2 dataDir=/opt/module/zookeeper-3.5.7/zkData
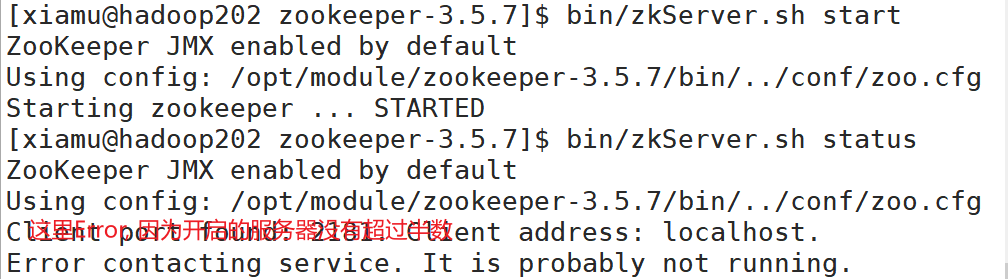
本地启动和停止 [xiamu@hadoop202 zookeeper-3.5.7]$ bin/zkServer.sh start启动 zookeeper
[xiamu@hadoop202 zookeeper-3.5.7]$ jps 查看进程是否启动
[xiamu@hadoop202 zookeeper-3.5.7]$ bin/zkServer.sh status查看状态
[xiamu@hadoop202 zookeeper-3.5.7]$ bin/zkCli.sh 启动客户端[zk: localhost:2181(CONNECTED) 0] quit退出客户端
[xiamu@hadoop202 zookeeper-3.5.7]$ bin/zkServer.sh stop停止 ZooKeeper
集群安装 在创建好的 zkData 目录下创建一个文件 myid[xiamu@hadoop202 zkData]$ vim myid[xiamu@hadoop203 zkData]$ vim myid[xiamu@hadoop204 zkData]$ vim myid[xiamu@hadoop202 module]$ xsync zookeeper-3.5.7/
配置[xiamu@hadoop202 conf]$ vim zoo.cfg
1 2 3 4
配置完成之后分发[xiamu@hadoop202 conf]$ xsync zoo.cfg
集群启动 [xiamu@hadoop202 zookeeper-3.5.7]$ bin/zkServer.sh start[xiamu@hadoop202 zookeeper-3.5.7]$ bin/zkServer.sh status[xiamu@hadoop203 zookeeper-3.5.7]$ bin/zkServer.sh start[xiamu@hadoop203 zookeeper-3.5.7]$ bin/zkServer.sh status[xiamu@hadoop204 zookeeper-3.5.7]$ bin/zkServer.sh start[xiamu@hadoop204 zookeeper-3.5.7]$ bin/zkServer.sh status
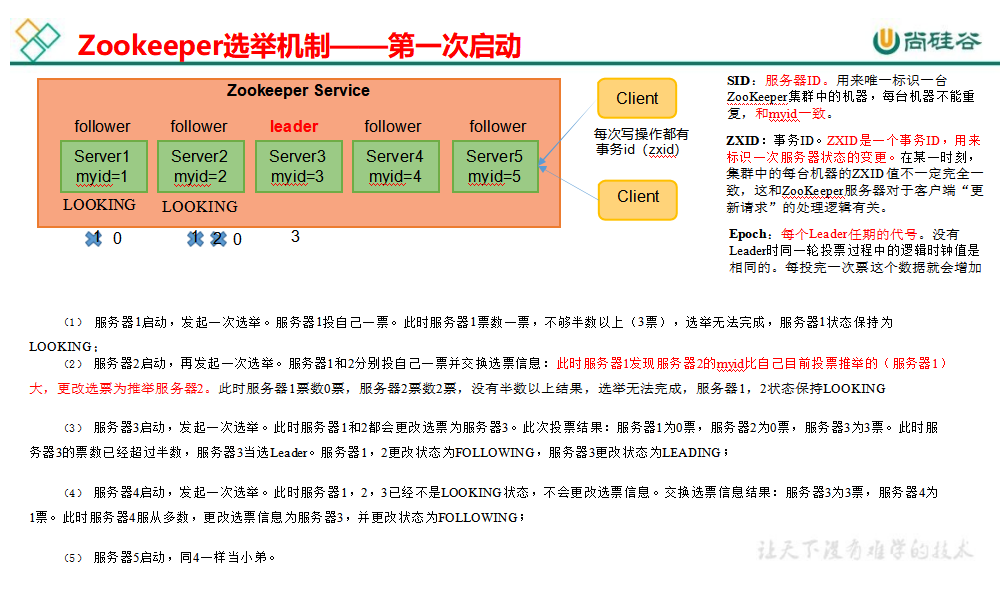
第一次选举机制
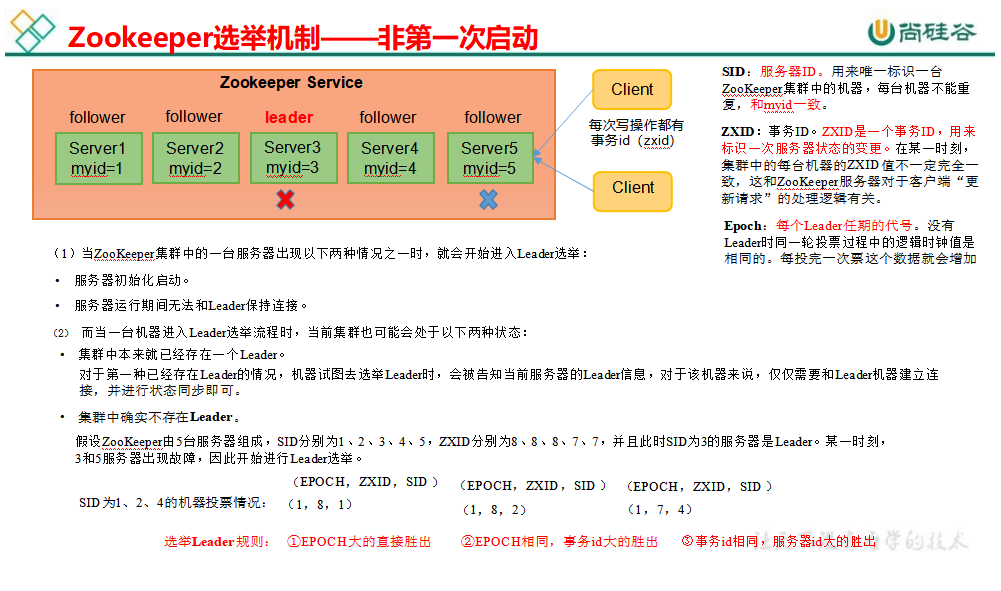
非第一次选举机制
编写启动停止脚本 在/home/xiamu/bin 目录下创建 zk.sh 脚本[xiamu@hadoop202 bin]$ vim zk.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #!/bin/bash case $1 in "start" ){for i in hadoop202 hadoop203 hadoop204do echo ---------- ZooKeeper $i 启动 ----------$i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start" done "stop" ){for i in hadoop202 hadoop203 hadoop204do echo ---------- ZooKeeper $i 停止 ----------$i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop" done "status" ){for i in hadoop202 hadoop203 hadoop204do echo ---------- ZooKeeper $i 状态 ----------$i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status" done esac
给予可执行权限[xiamu@hadoop202 bin]$ chmod 777 zk.sh[xiamu@hadoop202 bin]$ xsync zk.sh [xiamu@hadoop202 bin]$ zk.sh start[xiamu@hadoop202 bin]$ zk.sh status[xiamu@hadoop202 bin]$ zk.sh stop
命令行-节点信息 命令行语法
命令基本语法
功能描述
help
显示所有操作命令
ls path
使用 ls 命令来查看当前 znode 的子节点[可监听]
-w 监听子节点变化
| create | 普通创建
-e 临时(重启或者超时消失) |
[xiamu@hadoop202 zookeeper-3.5.7]$ bin/zkCli.sh客户端直接连接[xiamu@hadoop202 zookeeper-3.5.7]$ bin/zkCli.sh -server hadoop202:2181[zk: hadoop202:2181(CONNECTED) 0] ls / 查看当前 znode 中所包含的内容[zk: hadoop202:2181(CONNECTED) 1] help 显示所有操作命令[zk: hadoop202:2181(CONNECTED) 4] ls -s / 查看当前节点详细数据
1 2 3 4 5 6 7 8 9 10 11 [zookeeper]cZxid = 0x0
(1)czxid:创建节点的事务 zxid
命令行-节点类型(持久/短暂/有序号/无序号) 创建永久节点 创建普通节点(默认创建的是不带序号的永久节点)
1 2 3 4 5 6 7 8 9 10 11 12 13 [zk: hadoop202:2181(CONNECTED) 0] ls /"diaochan" ls /"liubei" ls /sanguo
获取节点中的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [zk: hadoop202:2181(CONNECTED) 8] get -s /sanguo
创建带序号的节点
1 2 3 4 5 6 7 8 9 10 "zhangliao" ls /ls /sanguo/weiguo
带序号的永久节点第二次创建会自动加上序号, 而不带序号的永久节点再次创建会报错
1 2 3 4 5 6 7 8 [zk: hadoop202:2181(CONNECTED) 15] create -s /sanguo/weiguo/zhangliao "zhangliao" "caocao" "caocao"
使用quit退出客户端, 再次连接, 发现之前创建的节点仍然存在
1 2 3 4 5 6 7 8 [zk: hadoop202:2181(CONNECTED) 17] quitls /sanguols /sanguo/weiguo
创建临时节点 创建临时节点只需要加上参数-e 即可
1 2 3 4 5 6 7 [zk: hadoop202:2181(CONNECTED) 2] create -e /sanguo/wuguo "zhouyu" ls /sanguo
创建一个带序号的临时节点
1 2 3 4 5 6 7 [zk: hadoop202:2181(CONNECTED) 4] create -e -s /sanguo/wuguo "zhouyu" ls /sanguo
断开quit连接之后, 吴国(wuguo)就没有了, 因为吴国创建的时候有-e, -e 表示是临时节点, 临时节点断开连接之后就删除了
1 2 3 4 5 6 [zk: hadoop202:2181(CONNECTED) 6] quitls /sanguo
**总结: **
修改节点的值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [zk: hadoop202:2181(CONNECTED) 2] get -s /sanguo/weiguoset /sanguo/weiguo "simayi"
监听器及节点删除 监听节点的值 在 hadoop204 中, get -s /sanguo查看 sanguo 的值, 并且使用get -w /sanguo监控 sanguo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [zk: hadoop204(CONNECTED) 0] get -s /sanguo
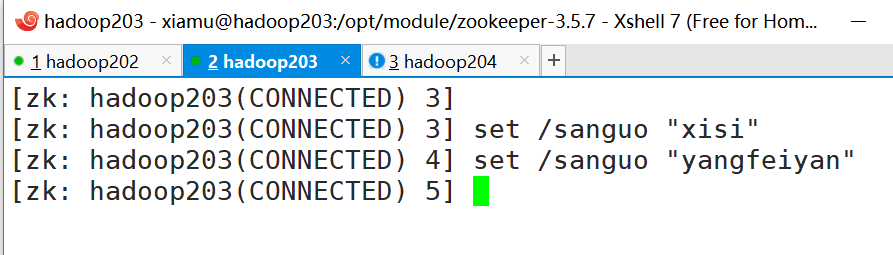
在 hadoop203 中修改 sanguo 的值, 在 hadoop204 的选项卡会出现一个感叹号
1 2 3 [zk: hadoop203(CONNECTED) 3] set /sanguo "xisi" set /sanguo "yangfeiyan"
监听节点的路径变化 在 hadoop204 中使用ls -w /sanguo监听 sanguo 的路径变化
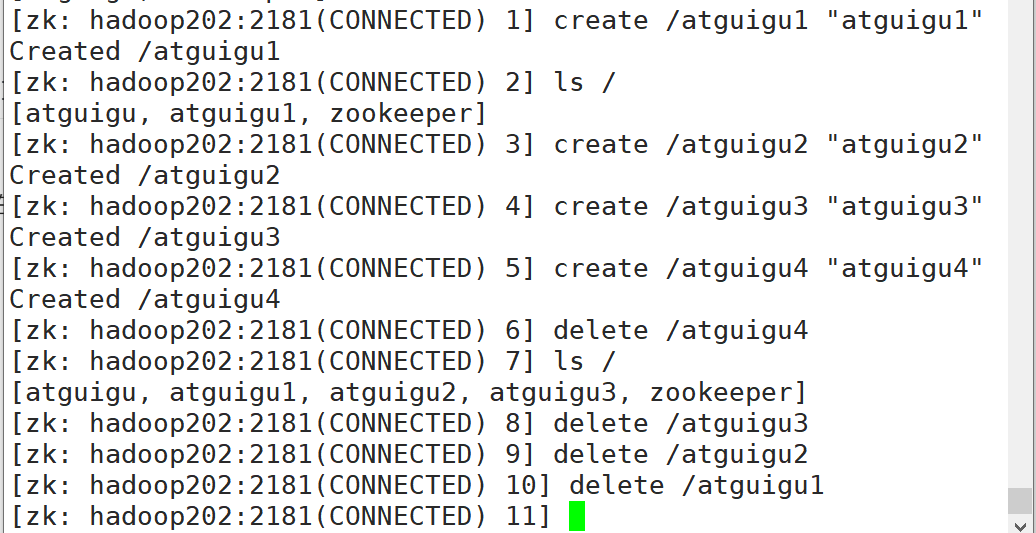
删除节点 删除节点和递归删除节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [zk: hadoop204(CONNECTED) 7] ls /ls /sanguols /sanguols /sanguols /
查看节点状态 查看节点状态, 但是不查看值
1 2 3 4 5 6 7 8 9 10 11 12 13 [zk: hadoop204(CONNECTED) 21] stat /sanguo
客户端-创建节点 创建 maven 项目zookeeper
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <dependencies>
在 resource 添加 log4j.properties 配置文件
1 2 3 4 5 6 7 8 log4j.rootLogger=INFO, stdout
创建包名com.atguigu.zkzkClient
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class zkClient {"hadoop202:2181,hadoop203:2181,hadoop204:2181" ;Watcher "/atguigu" , "ss.avi" .getBytes(),
客户端-监听节点的变化 getChildren 中第二个参数为 true 会调用 init 中 new Watch(){…}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @BeforeWatcher "/" , true );"------------------" );for (String child : children) {"------------------" );"/" , true );sleep (Long.MAX_VALUE);
监听的同时, 在 linux 中添加/删除节点, idea 能监听得到
客户端-判断节点是否存在 1 2 3 4 5 6 // 判断Znode是否存在stat = zooKeeper.exists("/atguigu" , false );stat == null ? "not exist" : "exist" );
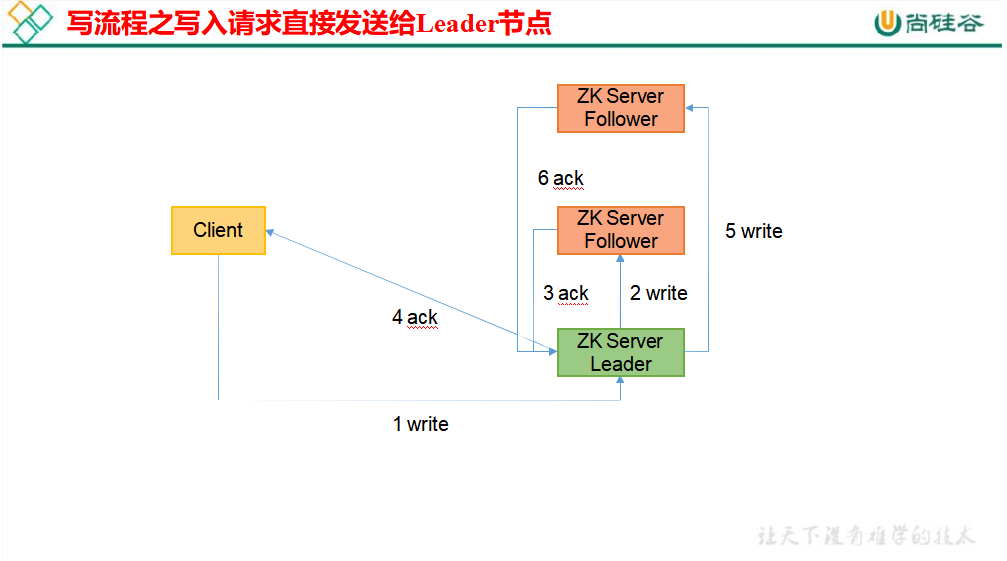
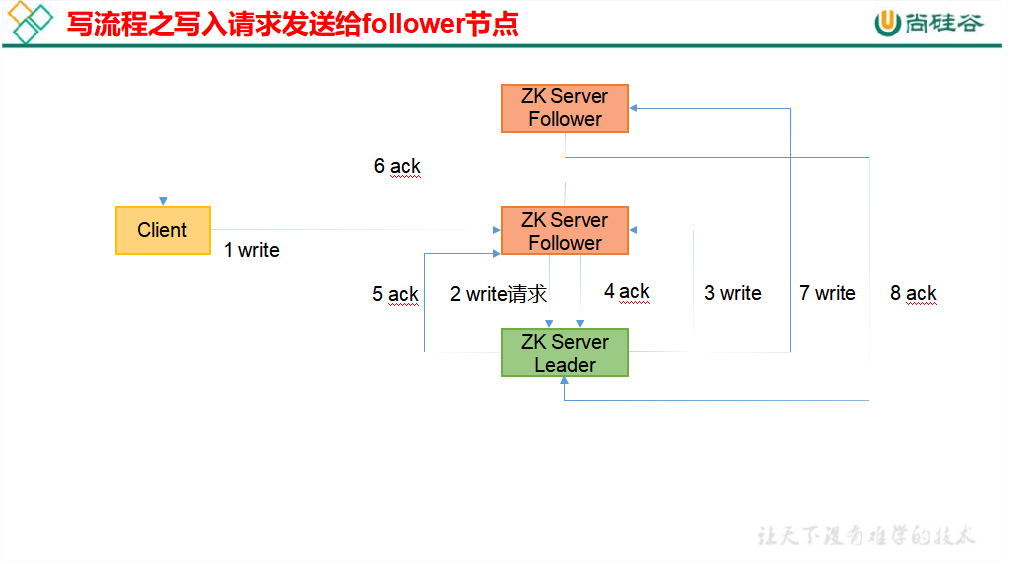
写数据原理 ack 表示应答
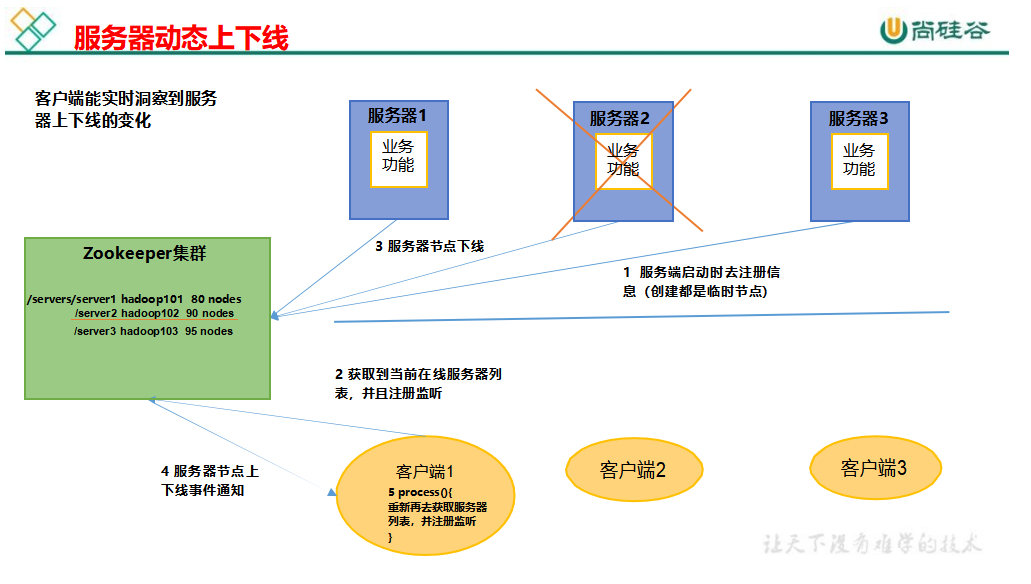
服务器动态上下线
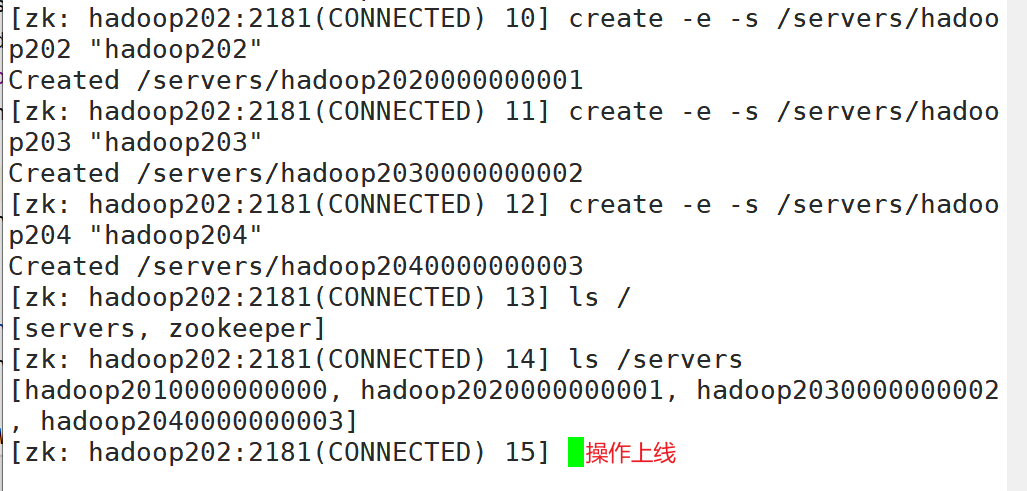
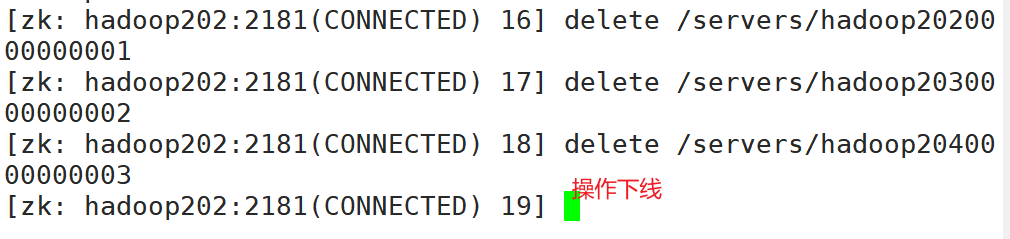
操作上线
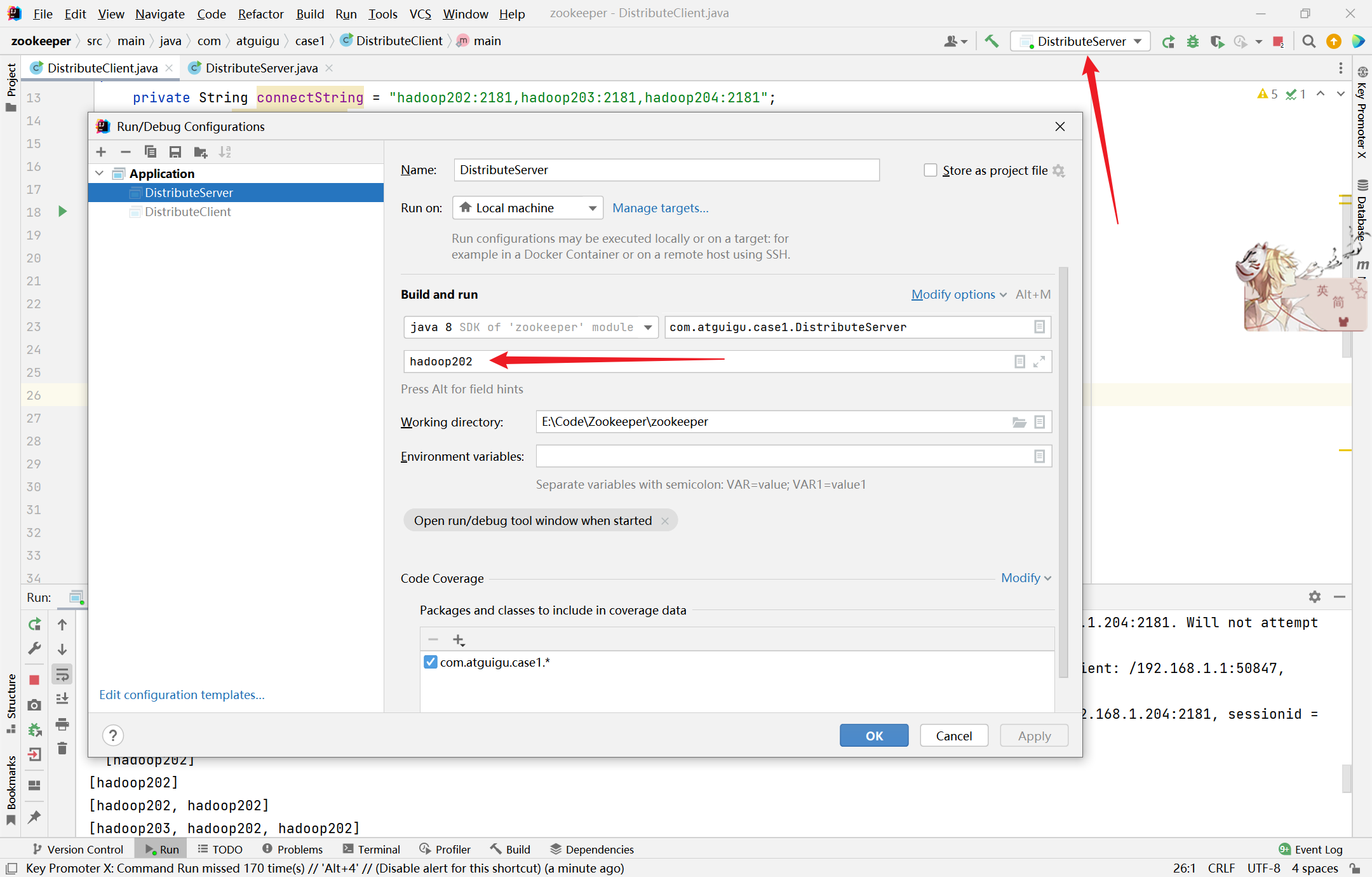
DistributeServer 代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package com.atguigu.case1;"hadoop202:2181,hadoop203:2181,hadoop204:2181" ;sleep (Long.MAX_VALUE);"/servers/" + hostname, hostname.getBytes()," is online" );Watcher
DistributeClient 代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 package com.atguigu.case1;"hadoop202:2181,hadoop203:2181,hadoop204:2181" ;sleep (Long.MAX_VALUE);"/servers" , true );for (String child : children) {"/servers/" + child, false , null);Watcher
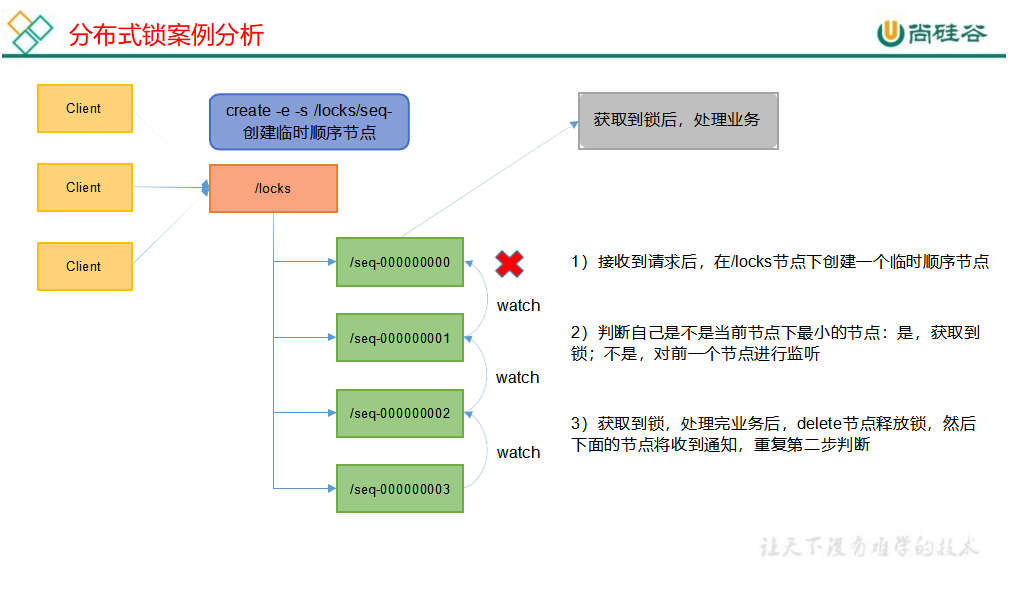
分布式锁 什么叫做分布式锁呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 package com.atguigu.case2;"hadoop202:2181,hadoop203:2181,hadoop204:2181" ;Watcher if (watchedEvent.getState() == Event.KeeperState.SyncConnected) {if (watchedEvent.getType() == Event.EventType.NodeDeletedstat = zooKeeper.exists("/locks" , false );if (stat == null) {"/locks" , "locks" .getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);zkLock "/locks/" + "seq-" , null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);"/locks" , false );if (children.size() == 1) {return ;else {sort (children);"/locks/" .length());if (index == -1) {"数据异常" );else if (index == 0) {return ;else {"/locks/" + children.get(index - 1);true , null);return ;unZkLock
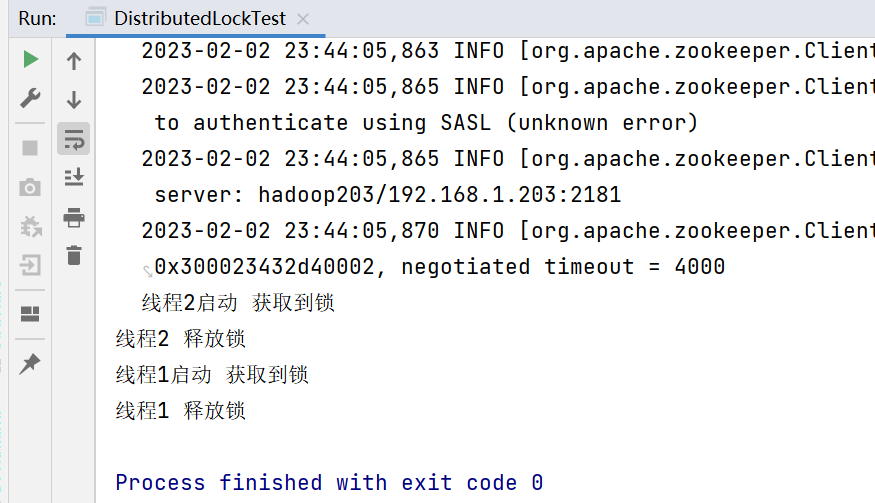
DistributedLockTest 代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package com.atguigu.case2;Runnable run "线程1启动 获取到锁" );sleep (5 * 1000);"线程1 释放锁" );Runnable run "线程2启动 获取到锁" );sleep (5 * 1000);"线程2 释放锁" );
运行结果如下:
Curator 框架实现分布式锁案例 pom.xml 导入依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <dependency>
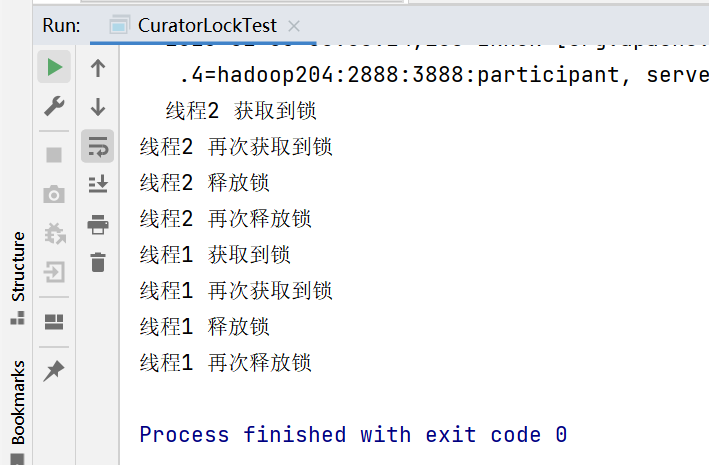
CuratorLockTest 代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 package com.atguigu.case3;"/locks" );"/locks" );Runnable run "线程1 获取到锁" );"线程1 再次获取到锁" );sleep (5 * 1000);"线程1 释放锁" );"线程1 再次释放锁" );Runnable run "线程2 获取到锁" );"线程2 再次获取到锁" );sleep (5 * 1000);"线程2 释放锁" );"线程2 再次释放锁" );getCuratorFramework "hadoop202:2181,hadoop203:2181,hadoop204:2181" )"zookeeper 启动成功" );return client;
说明同一个线程中锁是可以多次获取的
企业面试真题(面试重点) 选举机制 半数机制,超过半数的投票通过,即通过。
生产集群安装多少 zk 合适? 安装奇数台。生产经验:
常用命令 ls、get、create、delete